Google Study On Sitemaps
The Google Webmaster Central blog notified us that Googlers have presented a new study on Sitemaps at the WWW’09 conference in Madrid. The study is absolutely interesting and I recommend printing out the ten page PDF document and reading it. For those of you who don’t have time for that, I hope to highlight the […]
The Google Webmaster Central blog notified us that Googlers have presented a new study on Sitemaps at the WWW’09 conference in Madrid. The study is absolutely interesting and I recommend printing out the ten page PDF document and reading it. For those of you who don’t have time for that, I hope to highlight the most interesting findings from the study below.
The purpose of the study was to measure the past few years of Sitemaps usage at Google to determine how Sitemap files improve coverage and freshness of the Google web index. By coverage, I mean how Google crawls the web deeper and finds more content that it might not have found. Bt freshness, I mean how Google crawls new or updated content faster, when compared to the normal crawl.
Interesting facts from the study:
- ~35 million Sitemaps were published, as of October 2008.
- The 35 million Sitemaps include “several billion” URLs.
- Most popular Sitemap formats include XML (77%), Unknown (17.5%), URL list (3.5%), Atom (1.6%) and RSS (0.11%).
- 58% of URLs in Sitemaps contain the lastmodification date.
- 7% of URLs contain the change frequency field.
- 61% of URLs contain the priority field.
The paper discusses the process used by Google for Sitemaps. Here is a flow diagram that explains it quickly.
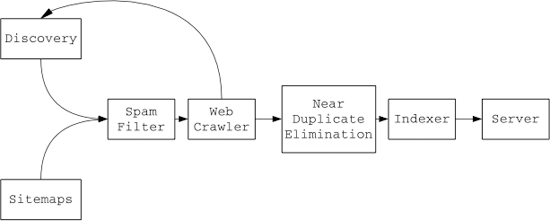
Coverage:
The dataset used to measure the “coverage” of Sitemaps was approximately 3 million URLs, 1.7 millions URLs specifically from Sitemaps and the remainder from the normal discovery process. Duplicate URLs were close to one million during the discovery crawl process, as opposed to only a 100 duplicate URLs in the Sitemaps files. In short, the study found that discovery was 63% “efficient” and Sitemaps was 99% efficient in crawling the domain at the cost of mission a small fraction of content.
- The percent of duplicates inside Sitemaps is mostly similar to the overall percent of duplicates.
- 46% of the domains have above 50% UniqueCoverage and above 12% have above 90% UniqueCoverage.
- For most domains, Sitemaps achieves a higher percent of URLs in the index with less unique pages.
Freshness:
How fresh can Google get with Sitemaps?
- 78% of URLs were seen by Sitemaps first, compared to 22% that were seen through discovery first.
- 14.2% of URLs are submitted through ping
- The probability of seeing a URL through Sitemaps before seeing it through discovery is independent of whether the Sitemaps was submitted using pings or using robots.txt
The paper then goes on to talk about coming up with ways to determine the crawl order, either via Sitemaps or Discovery. Concepts such as SitemapScore and DiscoveryScore are brought up and possible methods.
The study seems like a great read for most SEOs interested in understanding how Google Sitemaps work and how it can benefit your sites.
Related stories
About the author
In 2019, Barry was awarded the Outstanding Community Services Award from Search Engine Land, in 2018 he was awarded the US Search Awards the "US Search Personality Of The Year," you can learn more over here and in 2023 he was listed as a top 50 most influential PPCer by Marketing O'Clock.
Barry can be followed on X here and you can learn more about Barry Schwartz over here or on his personal site.