Impressive: The Wolfram Alpha “Fact Engine”
Much attention has been focused on the forthcoming Wolfram Alpha search service. Will it be as important as Google has become? Perhaps! A new search paradigm? Yes! Or at least a new way of gathering information. A Google-killer? Nope! But when the service launches, it should become an essential in anyone’s search tool kit. Wolfram […]

Much attention has been focused on the forthcoming Wolfram Alpha search service. Will it be as important as Google has become? Perhaps! A new search paradigm? Yes! Or at least a new way of gathering information. A Google-killer? Nope! But when the service launches, it should become an essential in anyone’s search tool kit.
Wolfram Alpha is backed by Stephen Wolfram, the noted scientist and author behind the Mathematica computational software and the book, A New Kind Of Science. The service bills itself as a “computational knowledge engine,” which is a mouthful. I’d call it a “fact search engine” or perhaps an “answer search engine,” a term that’s been used in the past for services designed to provide you with direct answers, rather than point you at pages that in turn may hold those answers.
Earlier this week, I talked with Stephen to understand how the service works. Below, my look.
Amazing Stats, At Your Fingertips
Do a search on Wolfram Alpha, and if it has matching data, it presents a ton of information on a single page, from figures to charts. For example, a search for “newport beach” not only shows the current temperature and forecast but also provides easy access to historical temperatures, which also get charted:
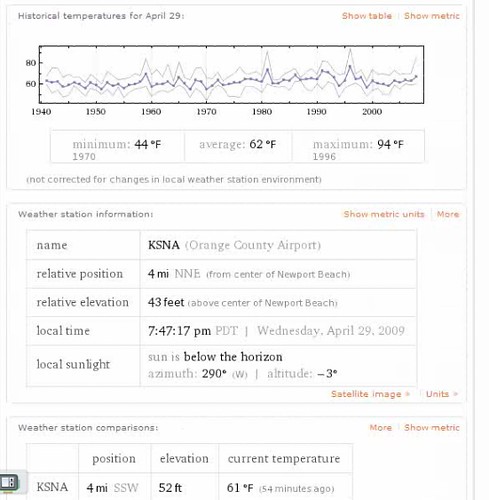
Looking for the gross domestic product of a country, say France? Wolfram Alpha’s got that:

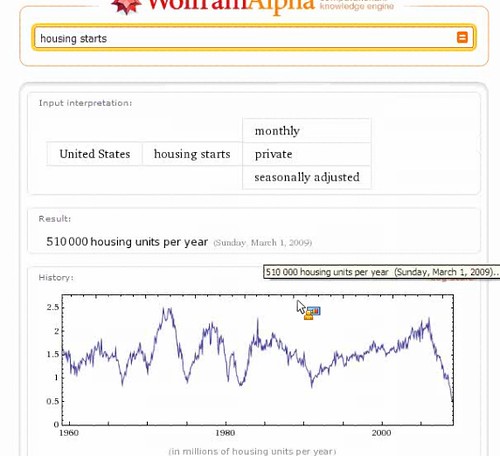
Housing starts in the United States? Got that:
Want to know how popular the name Daniel is in the United States over time and how many people are currently estimated to be alive with that name, plus their ages? Wolfram Alpha can do that, too — though I wasn’t quick enough to screenshot that example during the demo. We moved fast! But over at Read Write Web, See Wolfram Alpha in Action: Our Screenshots has more examples you can view.
Wolfram Alpha also made a public demo debut this week at Harvard, which you can watch here:
Here’s a shorter version that shows actual screenshots of the service.
David Weinberger also has an excellent summary of the public demo.
Tapping Into Databases; Centralizing The Invisible Web
Where’s all this information coming from? Unlike Google or a traditional search engine, Wolfram Alpha isn’t crawling the web and “scraping” information, a process where you try to extract data from a web page. Instead, it’s working with a variety of providers to gather public and private information. More important, it then uses a staff of over 150 people to ensure the information is clean and tagged in a way that Wolfram Alpha can present.
For example, many government agencies publish statistical information, such as the housing starts data I mentioned above. Wolfram Alpha obtains this data, which gets incorporated into the overall database people search against.
There’s no great magic here in dealing with a single set of data. Anyone could download data on housing starts, open the information in a spreadsheet like Excel and produce tables and charts. Where Wolfram Alpha amazes is by having a huge collection of statistics and other facts that, at least in the demo I viewed, can quickly be searched through and displayed with the ease and speed of doing a regular web search.
In some ways, this is like a Holy Grail that any number of “invisible web” search engines have chased over the years, the ability to look inside data sources that can’t easily be crawled and provide answers from them. Wolfram Alpha succeeds because unlike with those past attempts, it has produced its own centralized repository of these answers and stats.
If a traditional search engine is like a giant “book of the web,” with copies of all the pages that it has found stored in a searchable index, then Wolfram Alpha is a like a giant encyclopedia of statistics and facts — or a CIA Fact Book — or a World Almanac. It’s brimming with facts and figures.
Much of the information, once entered, doesn’t need updating. However, some facts and figures change. Pluto, once a planet, is now a dwarf planet. When to refresh the data is another challenge for the system. But the company is working to figure out what information needs to be regularly revisited. Wolfram noted that a new moon of Saturn had just been discovered, “so someone is dutifully adding the information,” he told me.
Another challenge is that some of the information gathered might be wrong. In some cases, Wolfram Alpha might try to average data (and point this out through in the source notations that all pages carry).
“We might still get it wrong because the underlying sources get it wrong or something that our implicit model gets wrong. But there’s the trail of where did the numbers came from,” he said.
In other cases, they’re in a unique position to spot if some data regularly accepted might not be up to snuff.
“Sometimes there will be data that’s incredibly wrong, ” Wolfram said, giving an example of a lake database with latitude and longitude coordinates that, when Wolfram Alpha plotted it against a map, turned up some surprises.
“Someone did the obvious test and plotted the lakes and found lots of them in the middle of oceans. Things that people have never checked, as we start to do visualization and analysis, it’s remarkable how often we find things that were obviously wrong but not noticed before because they were in printed form or not looked at in aggregate,” he said.
Gaps In The Knowledge Base
Wolfram Alpha has limitations, of course. There are plenty of statistics it doesn’t have. For example, one query it couldn’t do was how the size of search engines have changed over time. There are no official sources for this information, especially since the major search engines stopped putting out such figures. And as it doesn’t crawl the web, it doesn’t know of historic figures that I and others have published.
Search engine popularity figures posed a similar challenge. These are regularly provided by at least four different metrics firms, but Wolfram Alpha doesn’t have that data.
Some of this will change. The company is actively working to expand the data sources it contains, and it invites those with information to contribute data and their knowledge expertise.
Some questions it’s unlikely to ever answer. Want to know how Google works? There’s no published formula for this; no set of verified facts about it. Any answer to that takes a more narrative form, and even then, it’s largely subjective based on what various authors might think. The more subjective the query, the less likely Wolfram Alpha will have an answer.
“We’ll never be able to compute some personal detail of somebody’s life, but you can search for it with a traditional search engine,” Wolfram said.
This is why it won’t be a Google-killer, but more on that, further down.
Disambiguating Queries
Any search engines faces the “disambiguation” challenge, figuring out what someone is after when a word can have multiple meanings. Did “apple” mean the fruit or the computer company, for example.
Search engines traditionally use related search options to assist users. In addition, they rely on the fact that by presenting up to 10 different listings per page, they have multiple chances of guessing at the query intent correctly.
Wolfram Alpha, by having a single answer page, doesn’t get such chances. So to help, it makes its best guess at what particular meaning it thinks a word has and presents options to get other answers, based on other definitions. For example with “apple,” it defaults to the “financial entity” term but suggests there’s also:
- a species specification
- a spacecraft
- a general material
- a food
It then allows the user to change their answer based on those:

Wolfram says a huge amount of work has gone into having human editors develop the classification schemes. These are used for more than helping searches select the right definitions for their searches. They also allow the service to know how to automatically blend answers from different data sources into a single page.
For instance, Wolfram Alpha has lots of information from different sources about foods. It has lots of information from different sources about financial data. When a search is done for Apple, and it knows someone means Apple the computer company, it uses this tagging or classification to pull relevant data only out of financial databases, to create an Apple page on the fly. Food information is not used — otherwise, you’d have an odd page where along with a financial chart for the company, you might also get nutrition information for the fruit.
The service also makes use of IP data to help disambiguate. If by using your IP address, it knows you’re near a particular city, then it will use that along with other factors to decide which “city” data to show you in the case of multiple cities with the same name. A “city fame index” is also used.
Computing Knowledge
Just providing easy access and amazing display of data might be enough of an achievement, but Wolfram Alpha goes a step beyond by allowing for sets of data to be calculated against each other. Want to divide the GDP of France and Italy? You can do that by simply entering “gdp of france / italy.” Or in another example they’ve shown, you could divide GDP by the length of railway in Europe.
Some of this feels like cool parlor tricks. Enter 13.56 billion years ago, and you get a page of various stats that Wolfram Alpha thinks might be interesting. They will be to some, but perhaps more in the way that when Google Maps came out, many people cruised the satellite views out of curiosity rather than to solve some immediate need. A query like “uncle’s uncle’s grandson’s grandson” is used as an example of how a family tree can be generated — also interesting for the “wow factor” but not really a query that many would ever do in real life.
While many of the demo queries may feel like ways Wolfram Alpha is being put through its paces, rather than reflecting real life queries, I’m pretty confident we will see some amazing uses of its calculating abilities. As Twitter cofounder Biz Stone recently called Twitter “the messaging service we didn’t know we needed until we had it.” Similarly, Wolfram Alpha may become the search service we didn’t know we needed — and in particular, the search service we may use in ways completely unexpected from what anyone is envisioning.
Complimentary To Google, Not Competitive
Sound amazing? As I’ve said before, I’m pretty jaded about search. Any number of would-be Google-killers have come and gone without gaining traction.
Wolfram’s specific that the service isn’t aiming to be a Google-killer or even considers it a traditional search engine that competes.
“We are not a search engine. No searching is involved here,” he said. “The types of things that people are currently searching for have some overlap [with Google], but it isn’t huge. What’s exciting is that we have a whole new class of things that people can put into a input field and have it tell them what it knows.”
While I think technically that Wolfram Alpha will be pretty amazing — and indeed a huge new significant tool that people should consider — it will still face a hefty awareness challenge. It remains a specialized search tool, and general searchers — which are among those Wolfram Alpha is targeting — typically do not go directly to such tools.
Now That It’s Built, How Many Will Come?
Wikipedia is an excellent example. It has great awareness among the general public, from having been lampooned by Stephen Colbert to having a professor gain attention for banning its use by students. Despite such awareness, Wikipedia still gets a huge amount of its traffic from people who come to it only by doing a search at Google, rather than directly.
For reasons I’ve never seen fully researched or explained, people simply do not go to specialty search tools in mass numbers. Even at Google, the percentage of people going directly to its image or local search services is appallingly small, which has why it has made such an effort with universal search & blended results.
Another challenge is that some of what Wolfram Alpha does can be done VIA Google — emphasis on the VIA part, as I’ll explain.
For example, want a list of words that end -aq? Wolfram Alpha can show you them, but a search on Google quickly brings up a page in the top results that has them as well. Want the weather in Newport Beach? Google (and others) provides a direct display with links to deeper information. For many searches, this will still keep Google as a first port of call. Even though Wolfram Alpha directly displays answers, the Google Habit will remain strong, and they’ll likely be happy enough that Google points them in the right direction. And unlike Wikipedia, Wolfram Alpha likely won’t get a chance to rank in Google’s own results. There’s no set number of pages that Google can crawl, though it will be interesting to see if some pages start getting listed if people link to specific searches (if someone links to a Wolfram Alpha search request, that might generate a page that Google and other search engines can read).
Wolfram Alpha’s edge may be that it’s a unique repository of general knowledge that imitates a search engine (unlike Wikipedia, which has no search engine feel). Of course, the killer combination would be for Wolfram Alpha to be partnered with a major search engine. It’s something Wolfram said is being considered, though there are no formal discussions at the moment. The focus is really getting the service opened to the public and seeing how the initial reaction goes.
“We hope to be a high quality source, a quotable resource, in many cases,” Wolfram said.
Google, of course, just rolled out public data search, allowing people to chart out unemployment and population data in the United States (while this seems like a spoiler to Wolfram Alpha, Google’s since told me the exact timing was completely coincidental and even moved at the last minute due to the birth of a child of someone on the team).
While the launch during Wolfram Alpha’s public demo may have been coincidental, there’s no mistake that Google thinks searching through structured data and databases is important. The company told me it will continue to expand the data it offers, especially based on the type of queries it sees that would most benefit from it.
Still, at the moment, Google has nothing like the number of human editors (“curators,” Wolfram Alpha calls them) involved to build such a centralized database. The Big G can’t be written off, and if it decides that Wolfram Alpha really is drawing away people it needs, I’d expect it to build rapidly to compete. But Wolfram’s coming out with a big head start.
Aiming For Profits
When it goes live, Wolfram Alpha hopes to pay for itself in two ways. The right-side of pages — the “right-rail” in search engine vernacular — will carry sponsorships. Some deals for these are already in place for when the site goes live, though Wolfram didn’t reveal which companies will show there. Unlike traditional search ads, these don’t appear to be cost-per-click driven. Certainly no self-serve AdWords-like system appears in the works.
There will also be a corporate version eventually, which will allow users to do queries that involve heavy amounts of computation, to upload their own data in bulk or download data sets. The company also envisions licensing out private versions of the service and is still planning other offerings.
Will this all make the service eventually profitable?
“I hope it will be. I’ve invested quite a lot of money in it, as you can guess. I certainly hope to make that money back, otherwise it is a very grand piece of philanthropy on my part,” Wolfram said, with a chuckle.
As for the business issues still to be determined?
“I’m one of those people who doesn’t go for, ‘Let’s make an absolutely precise business plan’,” Wolfram said.
About That Name…
I’ve seen a fair amount of criticism that “Wolfram Alpha” doesn’t come along as a catchy name that will resonate with general searchers. Certainly, I find it a bit clunky. Is that really going to be the final name?
“Whether this ends up being Wolfram Alpha or overtaking our Wolfram.com site, that’s a subject of great internal debate at our company. We were keen to make sure this product is associated with our brand. Worst case, if we never figure out a business model at all, it’s great example of what the technology we have built can do. Our corporate name is as good a nonsense word as any Web 2.0 word,” he said.
Commenting further, he added about the “Alpha” part:
“There’s a bit of this being the first of something and a bit of humility that’s just the beginning of what I expect will be a very long term project. This is basically my third large project in life.”
When Can We Play?
Ready to try Wolfram Alpha out? The service is set to launch this month, though an exact data hasn’t been set.
New search services notoriously get overwhelmed by traffic when they debut, and I have no doubt Wolfram Alpha will get swamped with visitors. Given that it is so processor-intensive — that no pages are cached, which helps with load — I wouldn’t be surprised to see it go up-and-down in the first week it’s out. But the company feels confident that when it goes live, it’ll stay up consistently, based on load test it’s doing.
When it does go live, check it out. As said, it won’t be a replacement for Google or a traditional search engine. But it looks like a promising new resource to gather all types of answers.
For more, see related discussion at Techmeme.
Postscript: See these follow-up stories since the one above was written:
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author