7 fundamental technical SEO questions to answer with a log analysis (and how to easily do it)
According to columnist Aleyda Solis, a thorough analysis of your server logs can help uncover SEO insights you might not have gleaned otherwise.
Log analysis has evolved to become a fundamental part of technical SEO audits. Server logs allow us to understand how search engine crawlers interact with our website, and analysis of your server logs can lead to actionable SEO insights you might not have gleaned otherwise.
First: Choosing your tools
Many tools are available to help with a server log analysis, and which one is right for you will depend on your technical knowledge and resources. There are three types of log file analysis tools that you will want to consider (unless you’re doing it from the command line, which I wouldn’t recommend if you don’t already have experience with it):
Excel
If you know your way around Excel — if creating pivot tables and using VLOOKUP is second nature to you — you might want to give Excel a go by following the steps shown in this guide by BuiltVisible.
It’s important to note, too, that even if you use one of the other tool options, at some point you will need to export the data you have collected into Excel. This will output the data into a format that’s easy to integrate or compare with other data sources such as Google Analytics or Google Search Console.
Whether you use Excel throughout the entire analysis or only at the end will depend on how much time you want to spend using it to filter, segment and organize the data.
Open source tools
This is your choice if you don’t have a budget to spend on tools but you do have the technical resources to configure them. The most popular open source option is Elastic’s ELK stack, which includes Kibana, Elasticsearch and Logstash.
Paid tools
This is really the best option if you don’t have technical support or resources, especially as these tools are pretty straightforward to set up. A few options also support cURL in case you need to manually upload the log files (instead of connecting directly to the server to monitor):
- Splunk is probably the best-known paid log analyzer in the market, although it’s not the cheapest option. However, it has a light version that is free that you might want to check out.
- Logz.io offers ELK as a service (It’s based in the cloud), has considered SEO as one of their use cases, and has a free option, too.
- Loggly also has a limited free version. This is the one I use at the moment, after having tried the other ones, and it is the program you will see in my screen shots throughout the piece. Loggly is based in the cloud, and I really like its easy-to-use interface that facilitates easy filtering and searching. This functionality allows me to save my time for the analysis instead of segmenting and filtering data.
Once you have chosen the best tool for your case, it’s time to start with the analysis. You’ll want to ensure that you focus your analysis on actionable SEO items, as it’s easy to get lost in the non-SEO-oriented environment.
Here are a few questions that help me drive log analysis, and how I easily answer them (using Loggly, in my case). I hope this will allow you to see how you can also go through your logs in a non-painful way and analyze them for your own SEO process.
1. What bots access your site? Look for spambots or scrapers to block.
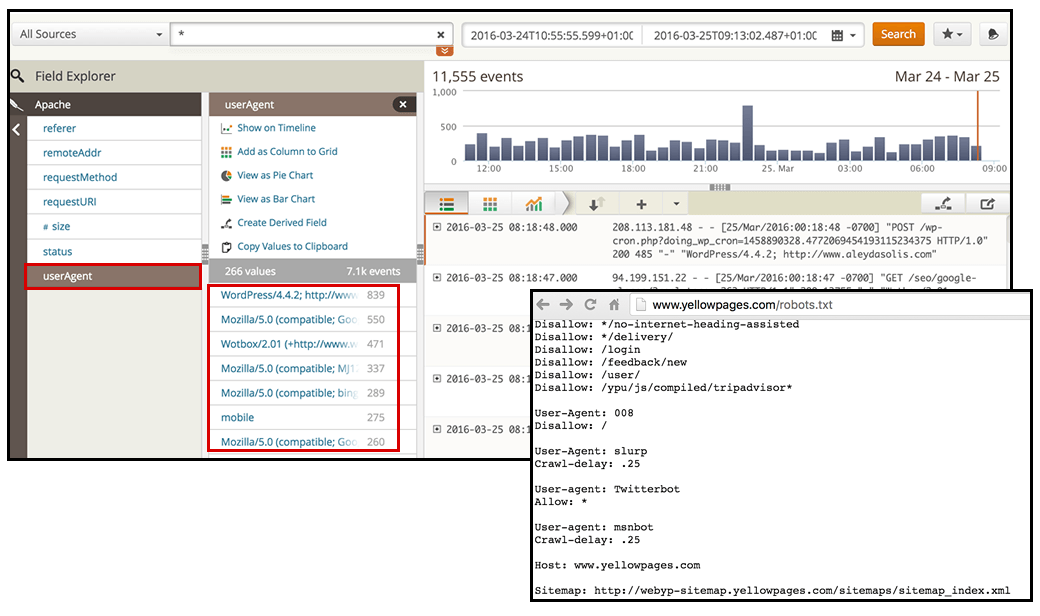
Logs follow a predefined format. As you can see in the screen shot below, identifying the user agent can be done more easily in Loggly with predefined filters for the log fields.
[Click to enlarge]
When you start doing log analysis for the first time, it might be worthwhile to not only check out the activity of search bots (such as the Googlebots, bingbots or Yandex bots), but also potential spambots that can generate performance issues, pollute your analytics and scrape your content. For this, you might want to cross-check with a list of known user agents, such as this one.
Look for suspicious bots, and then analyze their behavior. What’s their activity over time? How many events have they had during the selected time period? Does their appearance coincide with performance or analytics spam issues?
If this is the case, you might not only want to disallow these bots in your robots.txt file but also block them via the htaccess, as they won’t often follow the robots.txt directives.
2. Are all of your targeted search engine bots accessing your pages?
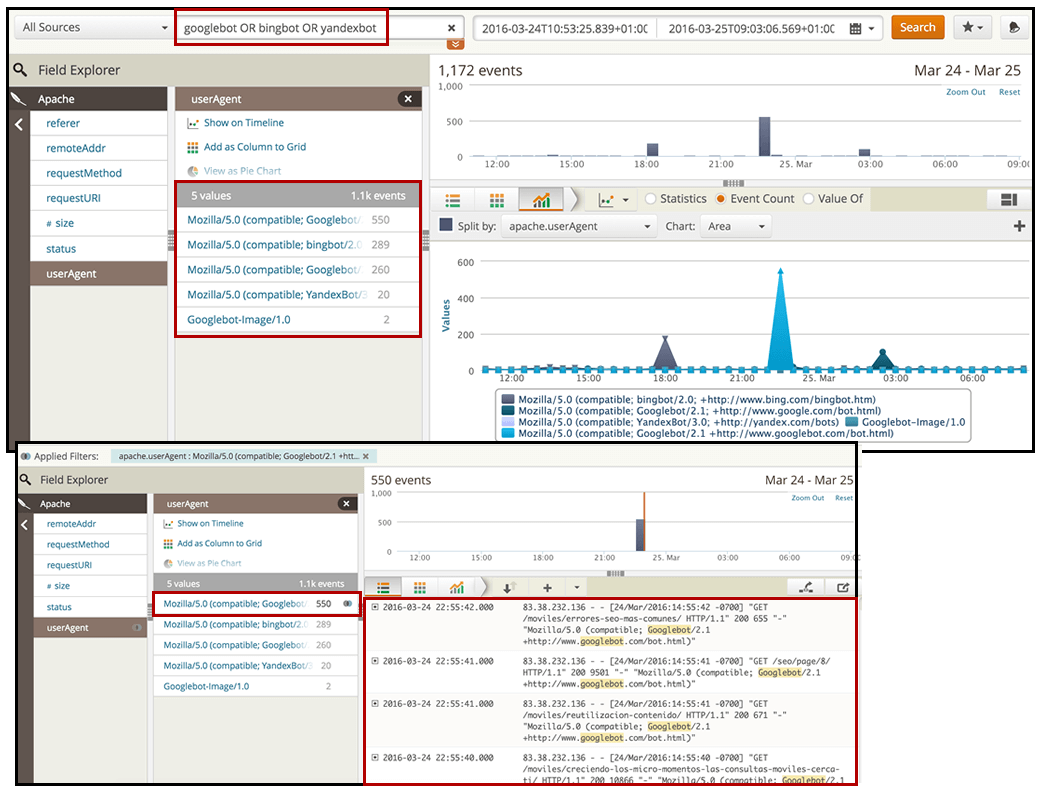
Once you have identified the bots that arrive to your site, it’s time to focus on the search engine bots to make sure they’re successfully accessing your pages and resources. With the “userAgent” filter in Loggly, you can directly select the ones you want to analyze or search for them by name with the search functionality using Boolean operators.
Once you’ve filtered to show only the search engine bots you’re interested in, you can select the graph option to visualize their activity over time. Which search bots have the highest level of activity on your site? Do they coincide with the search engines you want to rank with?
For example, in this case, we can see that one of the Googlebots has twice as much activity as one of the Bingbots and had a specific spike at 22:30h on March 24.
[Click to enlarge]
What’s important here is not only that the search bots come to your site, but that they actually spend their time crawling the right pages. Which pages are they crawling? What’s the HTTP status of these pages? Are the search bots crawling the same pages or different ones?
You can select each of the search user agents you want to check and export the data to compare them using pivot tables in Excel:

Based on this initial information, we’re going to start digging deeper to verify not only how these bots differ in crawling behavior, but if they really are crawling where they should be.
3. Which pages are not correctly serving? Look for pages with 3xx, 4xx & 5xx HTTP statuses.
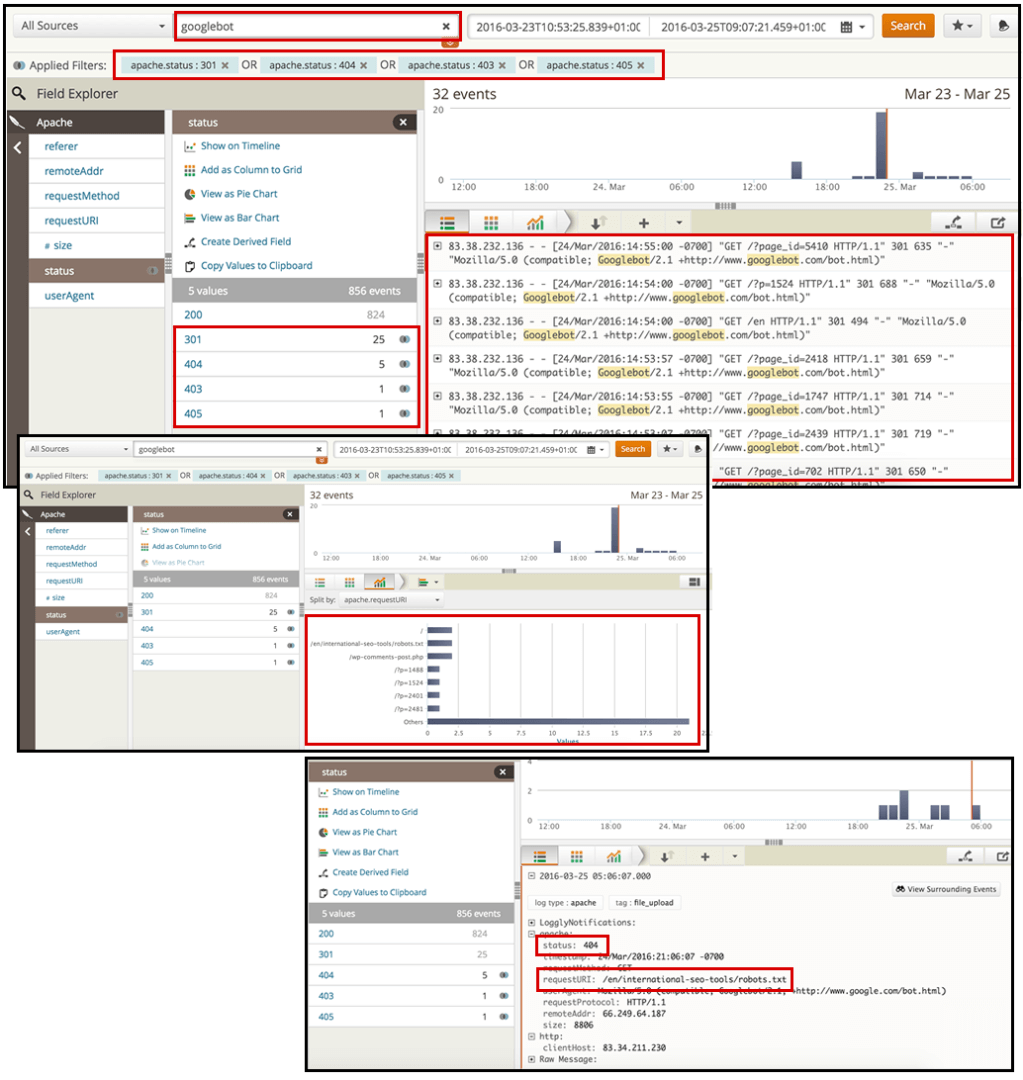
By searching for your desired search bot (in this case, Googlebot), and then choosing the “status” filter, you can select the HTTP values of the pages you want to analyze.
I recommend looking for those with 3xx, 4xx and 5xx status codes, as you want to see redirected or error pages that you’re serving to the crawlers.
[Click to enlarge]
From here, you can identify top pages generating most of the redirects or errors. You can export the data and prioritize these pages to be fixed in your SEO recommendations.
4. What are the top crawled pages by each of the search bots? Verify if they coincide with your site’s most important ones.
When searching for your desired search bot, you can directly select the “requestURI” filter to get a list of the top web documents, whether resources or pages, that the bot is requesting. You can review these directly in the interface (to verify that they’re featuring a 200 HTTP status, for example) or export them to an Excel doc, where you can determine if they coincide with your high-priority pages.
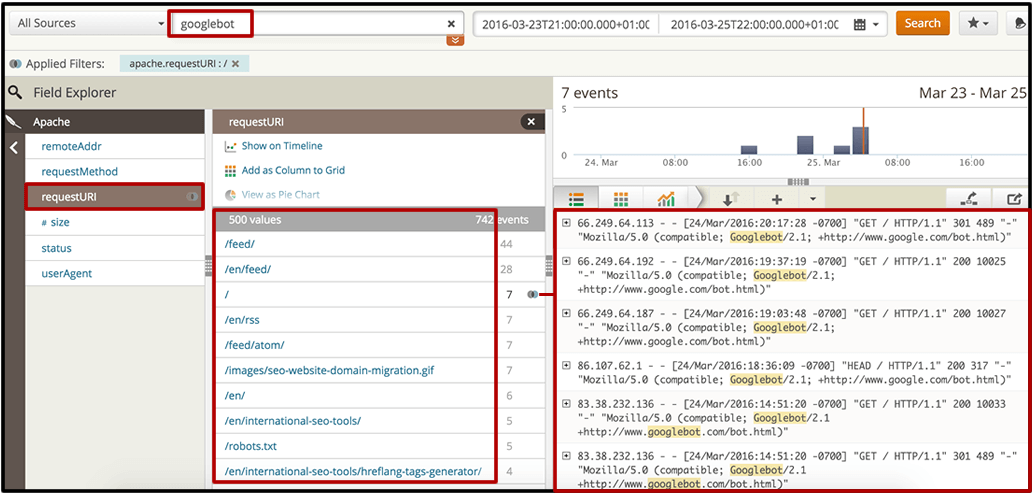
[Click to enlarge]
If your most important pages are not among the top crawled pages (or worse, are not included at all), you can then decide on the appropriate actions in your SEO recommendations. You might want to improve internal linking to these pages (whether from the home page or from some of the top crawled pages that you identified), then generate and submit a new XML sitemap.
5. Are the search bots crawling pages that they shouldn’t?
You’ll also want to identify pages and resources that are not meant to be indexed and thus shouldn’t be crawled.
Use the “requestURI” filter again to get a list of the top requested pages by your desired bot, then export the data. Check to see whether the pages and directories you have blocked via robots.txt are actually being crawled.

[Click to enlarge]
You can also check for pages which are not blocked via robots.txt but shouldn’t be prioritized from a crawling perspective — this includes pages that are noindexed, canonicalized or redirected to other pages.
For this, you can do a list crawl from the exported list with your favorite SEO crawler (e.g., Screaming Frog or OnPage.org) to add the additional information about their meta robots noindexation and canonicalization status, in addition to the HTTP status that you will already have from the logs.
6. What’s your Googlebot crawl rate over time, and how does it correlate with response times and serving error pages?
Unfortunately, the data that can be obtained through Google Search Console’s “Crawl Stats” report are too generic (and not necessarily accurate enough) to take action. Thus, by analyzing your own logs to identify the Googlebot crawl rate over time, you can validate the information and segment it to make it actionable.
With Loggly, you can select to view Googlebot’s activity in the desired time range in a line chart, where the HTTP status can be independently shown in order to verify the spikes over time. Knowing what type of HTTP requests occurred, and when, will show if errors or redirects were triggered, which could generate a non-effective crawling behavior from the Googlebot.
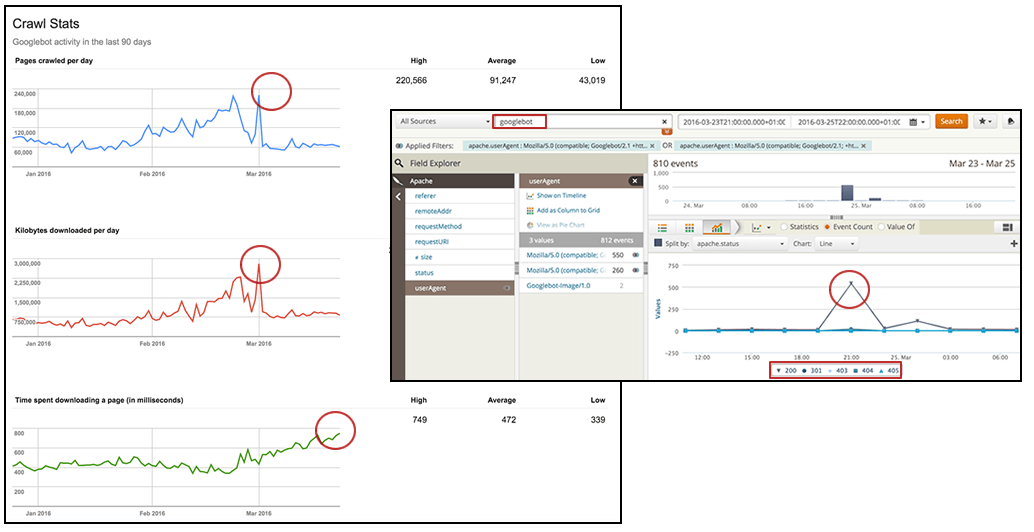
[Click to enlarge]
You can do something similar by plotting the size of the files requested by the Googlebot through a desired period of time in order to identify if there’s a correlation with crawling behavior changes, and then you can take the appropriate actions to optimize them.
7. What are the IPs Googlebot is using to crawl your site? Verify they’re correctly accessing the relevant pages and resources in each case.
I’ve included this one specifically for websites that serve different content to users in different locations. In some cases, such websites are unknowingly providing a poor experience to crawlers with IPs from other countries — from blocking them outright to letting them access just one version of the content (preventing them from crawling other versions).
Google now supports locale-aware crawling to discover content specifically meant to target other countries, but it’s still a good idea to ensure that all your content is being crawled. If not, this may indicate that your website is not properly configured.
After segmenting by user agent, you can then filter by IP to verify that the site is serving the right version of each page to the crawlers coming from the relevant countries.
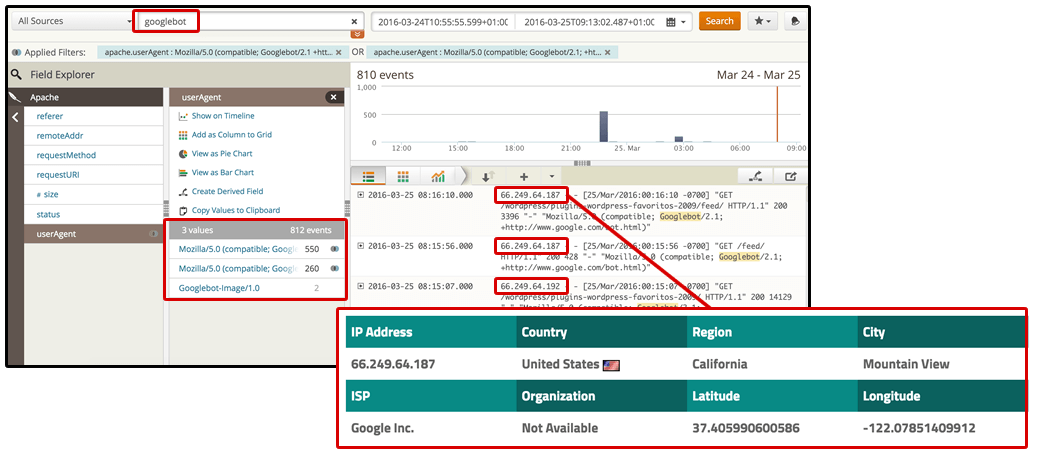
[Click to enlarge]
For example, take a look at what happens when I try to access to the NBA site at www.nba.com with a Spanish IP — I am 302 redirected towards a subdomain about basketball from the AS Website (a local sports newspaper in Spain), as can be seen in the screen shot below.

Something similar happens when I enter from a French IP; I get 302 redirected to the basketball subdirectory of L’Equipe, a local sports newspaper in France.

I’ve explained in the past why I’m not a fan of internationally targeted automatic redirects. However, if they’re meant to exist for business (or any other) reasons, then it’s important to give a consistent behavior to all crawlers coming from the same country — search bots and any other user agents — making sure that SEO best practices are followed in each case.
Final thoughts
I hope that going through these questions — and explaining how they can be answered using log analysis — will help you to expand and strengthen your technical SEO efforts.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author