Why crawl budget and URL scheduling might impact rankings in website migrations
You've down everything right from an SEO standpoint, but your website has still dropped in rankings following a site migration. What gives? Contributor Dawn Anderson breaks down how Google determines page importance and allots crawl budget.

Earlier this year, Google’s Gary Illyes stated that 30x redirects (301, 302, etc.) do not result in a loss or dilution of PageRank. As you can imagine, many SEOs have greeted this claim with skepticism.
In a recent Webmaster Central Office Hours Hangout, I asked Google’s John Mueller whether perhaps the skepticism was because when SEOs experience loss of visibility during migrations, they might not realize that all signals impacting rankings haven’t passed to the new pages yet, so they assume that PageRank was lost.
Mueller’s reply:
[blockquote]Yeah, I mean, any time you do a bigger change on your website — if you redirect a lot of URLs, if you go from one domain to another, if you change your site structure — then all of that does take time for things to settle down. So, we can follow that pretty quickly, we can definitely forward the signals there, but that doesn’t mean it will happen from one day to the next.[/blockquote]
During a migration, Googlebot needs to collect huge amounts of data for collation in logs, mapping and updated internally, and rankings can fluctuate throughout this process. But in addition to that, when Googlebot visits plays a fundamental part in rankings fluctuation during a migration, and that can relate to “URL scheduling,” a key component of crawl budget.
Crawl budget = host load + URL scheduling combined
URL scheduling is essentially “What does Googlebot want to visit (URLs), and how often?” Host load, on the other hand, is based around “What can Googlebot visit from an IP/host, based on capacity and server resources?” Together, these make up “crawl budget” for an IP or host. Both of these still matter in migrations.
On a 10-page brochure site, you likely won’t see any loss of visibility during a site migration. But what if your site is, for example, an e-commerce or news site with tens of thousands, hundreds of thousands, or more URLs? Or what if you’re merging several sites into one on the same IP host?
For everything to be fully passed, it all has to start as a bare minimum with at least a complete site crawl by Googlebot. It may even take a few complete site crawls, as Googlebot understands more about URLs — and how everything fits and links together internally in a site — with each subsequent visit to a newly migrated site.
On larger sites, that may not happen as soon as you’d hoped.
You’ve likely spidered your website with your favorite crawling tools prior to migration “go live,” and you’re confident that there are no issues. But then rankings and overall visibility drops. What could have gone wrong?
Many things can go wrong with a migration, but consider this: maybe nothing has gone wrong.
Maybe some of those signals that have not been passed are just “late and very late signals in transit,” rather than “lost signals.”
Some signals could even take months to pass. Why? Because Googlebot does not crawl large websites like crawling tools do, and it’s well nigh impossible for tools to emulate.
Your migration schedule is not Googlebot’s schedule
You have a migration schedule. It doesn’t follow that Googlebot will fall into step. Googlebots have their own work schedules, too.
Crawl frequency of URLs is on a per-URL basis. Google’s John Mueller confirmed this, saying:
[blockquote]Some URLs are crawled every few minutes, others just every couple months, and many somewhere in between.[/blockquote]
While Google states that there are many factors affecting the crawl frequency of URLs, in a recent webinar, Gary Illyes referred to “scheduling” and “buckets” of URLs prepared beforehand for Googlebot to visit. So we know that scheduling exists. It’s also covered in lots of Google patents on crawl efficiency.
It is worth noting that crawl frequency is not just based on PageRank, either. Both Google’s Andrey Lipattsev and Gary Illyes have remarked in separate webinars recently that PageRank is not the sole driver for crawling or ranking, with Lipattsev saying, “This (PageRank) has become just one thing among very many things.”
‘Importance’ is important
I’m not going to apologize for my overuse of the word “important,” because it’s been confirmed that crawl scheduling is mostly driven by the “importance” of URLs.
In fact, Gary Illyes states just that in a recent Virtual Keynote recorded interview with Eric Enge, and he notes that we should not keep focusing on PageRank as the sole driver for crawling or ranking.
Many of the Google Patents touch on Page Importance and mention that this “may include PageRank,” but it is clear that PageRank is only a part of it. So Page Importance and PageRank are not the same, but one (Importance) may include the other (PageRank).
What we do know is that important pages are crawled more often.
[blockquote cite=”John Mueller”]There is the kind of relationship where … when we think something is important we tend to crawl it more frequently.[/blockquote]
So, just what is ‘page importance?’
Of course, Google is not going to tell us of all the contributors to Page Importance, but a number of Google Patents around crawl efficiency and managing URLs touch on the subject.
These are a few of my findings from patents, webinars, Google Webmaster Hangouts, old interviews, blog posts and Google Search Console help. Just to be clear, there are undoubtedly more factors than this, and only some of the factors listed below are confirmed by Google.

There are other clues about page importance, too:
- Recently, Gary Illyes mentioned in a Virtual Keynote webinar with Eric Enge that if a page was included in an XML sitemap, it would likely be considered more important than others not included.
- We know that hreflang and canonicalization are used as signals (in page robots management).
- As mentioned above, PageRank “may be included in Page Importance” (and presumably with that internal PageRank).
- In Google’s Search Console Help Center, internal backlinks are stated as “a signal to search engines about the relative importance of that page.”
- Matt Cutts, Google’s former Head of Webspam, spoke of search engines understanding the importance of pages according to their position in URL parameter levels. Illyes also uses the example of an “about us” page and a “home page which changes frequently” as having different levels of importance to users who want to see fresh content. The “about us” page does not change much.
- File types and page types are also mentioned in patents, and we know that, for instance, image types are crawled less frequently than other URLs because they don’t change that often.
Change management/freshness is important, too
One thing we do know is that change frequency impacts crawl frequency.
URLs change all the time on the web. Keeping probability of embarrassment for search engines (the “embarrassment metric”) by returning stale content in search results below acceptable thresholds is key, and it must be managed efficiently.
Most of the academic papers on web crawling efficiency and information retrieval, conference proceedings and even patents attribute the term “search engine embarrassment” to Wolf et al.
To combat “embarrassment” (returning stale content in results), scheduling systems are built to prioritize crawling important pages and important pages which change frequently over less important pages, such as those with insignificant changes or low-authority pages.
These key pages have the highest probability of being seen by search engine users versus pages which don’t get found often in search engine results pages.
[blockquote cite=”John Mueller”]In general, we try to do our crawling based on what we think this page might be changing or how often it might be changing. So, if we think that something stays the same for a longer period of time, we might not crawl it for a couple of months.[/blockquote]
This implies that important change frequency is learned over time on web pages by search engines (it’s also mentioned in the crawl efficiency Google Patents) by comparing current with previous copies of the page to detect patterns of critical change frequency.
Emphasis is on how important the changes on the pages are to search engine users (“critical material change”) and also how important the pages themselves are to users (Page Importance, which may include PageRank).
Notice that Mueller says, “WHAT we think this page might be changing.” It needs to be changing some key feature (“critical material change”) in the page that is useful to search engine users.
Why can’t Googlebot visit all migrated pages at once?
From the above, we can conclude that Googlebots mostly arrive at a website with a purpose, a “work schedule,” and a “bucket list” of URLs to crawl during a visit. The URLs in the bucket list have been assigned to it by “The Scheduler” in the Google search engine system, if numerous Google patents around crawl efficiency are to be believed (see image).
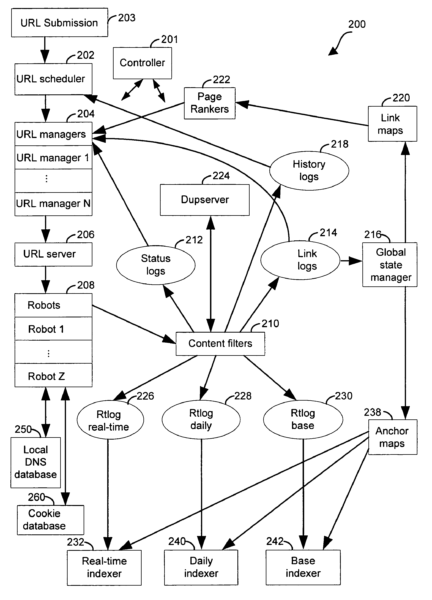
I say “mostly” because initial discovery crawling of brand-new sites is different. There is no knowledge of what is there already, so there is nothing — no past versions of the URLs — for the scheduler to compare anything to.
When Googlebot arrives at your site, if your IP (host) doesn’t suffer connection slowdown or server error codes during the visit, Googlebot completes its bucket list and checks around to see if there is anything more important than the URLs on the original bucket list that may also need collecting.
If there is, then Googlebot may go a little further and crawl these other important URLs as well. If nothing further important is discovered, Googlebot returns for another bucket list to visit on your site next time.
Whether you’ve recently migrated a site or not, Googlebot is mostly focusing on very few (important) URLs, with occasional visits from time to time to those deemed least important, or not expected to have changed materially very often (for example, old archives on news sites or unchanging product pages on e-commerce sites).
When Googlebot arrives at your website, and you’ve decided to go live with a migration, it’s not forewarned. It already had a scheduled list of URLs to get through on your site, and those might be important URLs (with expected important changes for search engine users) that Googlebot still wants to visit on this occasion.
Those URLs still have to take priority.
Googlebot is not likely to want to visit all of your new redirecting URLs right now, because not all pages will be of equal importance, and they may not be expected to have any useful change due to take place for some time to come (and so will not have been scheduled for a crawl).
Most probably, the search engine has noted that your migration is underway. The redirections on the URLs that Googlebot came to visit will be followed (and maybe a percentage more, too, from a crawl percentage reserved for discovery of additional important changes outside of the schedule), and all of the crawled pages’ server response codes will be reported back to the status logs and history logs.
If Googlebot comes across lots of redirection response codes, it will likely send a signal that says, “Hey, there’s a migration of some sort underway over there,” and the URL scheduler will respond in scheduling visits as a result of that. This is according to John Mueller:
[blockquote]Usually what happens when we see that a site is moving, we will try to crawl a little bit faster to pick up on everything.[/blockquote]
They do this because they want to catch up. However, it doesn’t necessarily follow that everything will get crawled straightaway, or that everything is even worth “catching up with” for quite a while.
For the most part, only the most important migrating URLs will get crawled as a priority, and maybe more frequently than they normally would, too. Just to make sure that everything (several signals) about those important “new” URLs (redirected from the “old” URLs) is picked up on.
Page importance and change frequency are not the only factors affecting when URLs will be visited, of course. Here are a few others:
Limited search engine resources
The web is growing at a much faster pace than resources available to search engines. For example, the number of websites on the internet grew by one-third between 2013 and 2014. Available search engine resources and capacity must be shared increasingly amongst IPs (hosts) and the sites residing at them to be crawled.
Host load
Every IP (web host) has a connection capacity it can handle. The search engine system learns over time what your host or IP can handle and schedules visits by Googlebots in accordance with its past knowledge of that. If you’re on a shared hosting, a virtual IP or a content delivery network (CDN), this will also play a part, as “host load” will be learned and shared with other sites at the IP. Googlebot is sent to crawl in such a way that it doesn’t cause damage to your server.
URL queues and low importance of migrating pages
There are two types of queues in crawl scheduling. First, there are queues of websites (strictly speaking, it’s queues of IPs/hosts). Second, there are queues of pages/URLs to crawl within individual websites or from an IP (host).
The queues of hosts (IPs and websites within them) is largely dependent upon “host load.” What can this host handle? If there are slowdowns in connection or server error codes, Googlebot may even prioritize crawling the highest importance URLs and drop the lower-importance URLs from crawls. In a migration, this means that low-importance URLs (often deeper in the website) may be dropped if Googlebot is struggling on the server.
Googlebot will also pull back if it experiences these types of slowdowns and error codes for a while (confirmed by Google’s Gary Illyes at SMX East, 2014). So, even less crawling. This could mean that over time, you end up with quite a queue of URLs from within your site waiting to be visited.
The queues of web pages within hosts is largely driven by “URL scheduling.” Queues may be managed by various sorting processes based largely on change frequency and importance of pages. In a migration, likely once Googlebot has informed the various players in the search engine crawling system (URL scheduler, history logs and so forth), the URLs to be crawled will be sorted and queued by what is known about the URLs being redirected from.
If you have a lot of “unimportant URLs,” or pages with historical non-critical change, or pages which change, but the features within them are not important enough to constitute “material change,” you may have to wait awhile in the queue after migrations. And that is before any issues with “host load.”
Scheduling still applies during migrations, but your queue of URLs to crawl got bigger
When I asked John Mueller whether scheduling still applied during migrations (August 2016), he said yes, continuing:
[blockquote]We can’t just suddenly crawl a whole new huge complete website after a migration.[/blockquote]
Crawl efficiency is still key.
In a site migration, you’ve effectively added a whole additional copy of your site’s worth of URLs to crawl. This is made even worse if you’ve decided to merge several individual sites at a new folder level in an existing main site to consolidate — even more URLs.
Suddenly, you’re asking Googlebot to crawl double the number of URLs at a bare minimum. Even with direct redirections alone (no redirect chains or historical “cruft” — another full subject), Googlebot’s going to hit the 301 from the index and then hop on to the 200 OK (a minimum of two URLs per initial URL visit, so double the size of the site).
Google crawls higher-quality site sections more
And what if you add a whole new fresh, content-rich, highly relevant and well internally linked section to your new site, while some low-importance sections of the old migration still are not fully crawled?
Well, there is an argument that the new higher-importance-score/higher-quality site sections will be crawled more, and old sections noted as having lesser importance, or lower-quality URLs queued for even later when there is spare crawling capacity.
In other words, it takes longer still to get everything passed across post-migration.
And if you have duplicates or low-value content, the process will take even longer. You might have to wait months! According to Google’s former Head of Webspam, Matt Cutts:
[blockquote]Imagine we crawl three pages from a site, and then we discover that the two other pages were duplicates of the third page. We’ll drop two out of the three pages and keep only one, and that’s why it looks like it has less good content. So we might tend to not crawl quite as much from that site.[/blockquote]
More recently, when interviewed by Eric Enge, Google’s Gary Illyes commented:
[blockquote]Higher quality site sections get crawled more and deeper, for instance, a high quality section on plants or trees might mean the flower page descendants within that section will be more likely to be crawled because their parent pages in the website architecture are higher quality.[/blockquote]
This is mentioned at around 46 min in the video below.
Googlebot still wants the important pages after a site migration
In a migration, everything changed (all URLs), but not everything that changed is necessarily a critically important change to users, particularly if the URL that is redirecting is already classified as “unimportant” with low “material change” frequency. Per a recent Google patent:
[blockquote]In some cases, the stale content in the search engine may have no particular significance, because the changes to the documents listed in a search result are minor, or the relevance of the documents remains substantially the same.[/blockquote]
Would it be the end of the world if a page which hardly ever changes, or only changes a few dynamic bits and pieces on load, redirected from the index?
Likely not. The user still manages to reach the destination page from the search engine result pages via your redirection, so their experience is not reduced significantly.
Your ‘unimportant’ pages may actually be adding quite a lot to your pre-migration visibility
It’s likely that current rankings across longer-tailed queries (which can sum to a lot) are in place due to many minor signals picked up from legacy crawls on matured URLs over time. The important pages get the early crawl following a migration, whereas the majority of low- to no-importance pages (which may include low to no PageRank) combined are adding huge amounts to overall visibility.
This can include the votes of relative importance (e.g., from the internal link structure alone), which will be all over the place.
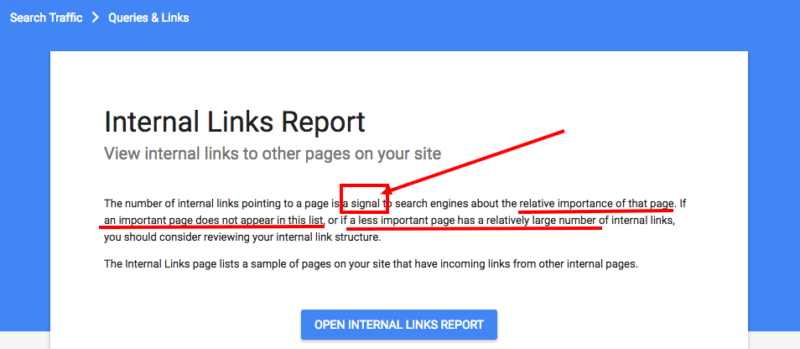
The signals used for ranking purposes from these will not have passed across to the newborn URLs until after the crawl and update back at the search engine. It will take quite a while for all the low-importance (but contributing to visibility) pages to be crawled.
And what of those pages on your old site which you may have noindexed previously prior to migration? They were likely contributing something of value for visibility.
Gary Illyes commented in the recent Virtual Keynote with Eric Enge that he didn’t think there was any dissipation in passing PageRank from noindexed URLs, so it is likely that this and other historical ranking signals will still be adding something to your migrating URLs.
Yet they are no longer in the index and may not get crawled again for a long time, so any legacy signals will take a long time to pass.
They will still get visited from time to time, along with 404s and even 410s, because “gone” is never truly gone (that’s another whole subject, which I’m not going to go into here).
For instance, in this example of a site which changed address and it’s rankings dropped, Google engineers suggested the reason may be that some pages from the old site were no longer indexed.
Clearly, there was something of value which had not been passed across but actually was vital (from an overall ranking perspective) and had been passed at some point historically.
Everything matters.
The ‘big picture’ and the website ‘ontology’ needs to be rebuilt
Until everything has been put back together following migration, your website is not the same. It’s in a half-built state, with parts of the overall jigsaw puzzle missing or pieces moved around.
The internal link architecture and relative importance signals from your own internal pages (text surrounding internal links, providing context, and any internal anchors) have to be rebuilt, for a start.
Googlebot also needs to rebuild its understanding of where the pages sit in the overall architecture. Everything can be skewed for a while on a site of any decent size.
The whole “inter-connectedness,” the theme or “ontology” of your site, and all of the semantic relevance within it, as an entity, is now also incomplete.
Until everything is reassembled (including the low-importance pages and their relative internal links), the relevance, context and external and internal importance signals (including PageRank) are recombined, the website is not as it was before, even if you took all the right SEO steps for a site migration.
Initially, you may just have the corners and the sides of the jigsaw puzzle rebuilt as the important pages of the site are crawled and processed, but everything combined makes the difference to “the big picture” and where your site ranks.
Until the site is rebuilt as it was before, Googlebot and the other search engine workers’ job is not complete.
At least wait for the work to be done before drawing conclusions.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Related stories
New on Search Engine Land
About the author