Coping With Enhanced Campaigns & The Problem Of Modifier Stacking
As we predicted a few months back, Enhanced Campaigns and mobile modifiers have been a benefit to those companies that employ them wisely. We’re excited to fold Google’s cross-device and in-store tracking into this mix as well as our own system for understanding micro-conversions. We’re also excited about the future of Enhanced Campaigns as more […]
As we predicted a few months back, Enhanced Campaigns and mobile modifiers have been a benefit to those companies that employ them wisely. We’re excited to fold Google’s cross-device and in-store tracking into this mix as well as our own system for understanding micro-conversions.
We’re also excited about the future of Enhanced Campaigns as more contextual modifiers are rolled out to the API to allow even more granular targeting at scale by geography, proximity, audience, and many more to come (we expect).
So what’s the problem?
The problem is modifiers have to be applied on top of each other in a stack. That works just fine as long as the effects we’re targeting are independent of each other. However, smart money suggests that the effects are not independent of each other in many cases.
Let’s dive into this in some detail to highlight the challenge.
If all the contextual effects are independent of each other, we can calculate modifiers in isolation of each other, and multiplying them all together will actually yield the “right” result for each combination of factors.
Here’s a reeeeaaaalllly simple model to illustrate this:
In our simple model, there are three modifiers: device, geography and proximity. To make life simple, we’ll say each modifier has two possible options — so for device, it’s small and large (anybody else ready to ditch the misleading labels of “mobile vs. desktop?”); for geography, there are good geographies and bad ones; and for proximity, there is close proximity to a location or not close.
This simple model creates 8 different combinations which our modifier calculations must handle:
- Large Device + Good Geography + Close Proximity
- Large Device + Good Geography + Not Close Proximity
- Large Device + Bad Geography + Close Proximity
- Large Device + Bad Geography + Not Close Proximity
- Small Device + Good Geography + Close Proximity
- Small Device + Good Geography + Not Close Proximity
- Small Device + Bad Geography + Close Proximity
- Small Device + Bad Geography + Not Close Proximity
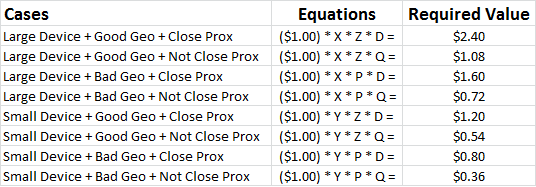
If the large vs. small device effect on traffic value is uniform across all geographies and regardless of proximity and the good vs. bad geography effect is the same regardless of device and proximity and the close vs. not close proximity effect is the same regardless of device and geography then and only then we can solve for the right modifiers like so:
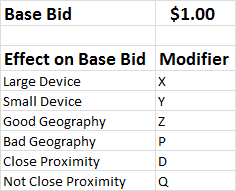

Effectively, the algorithm determines what the bids need to be and works backward to solve for the modifiers that will achieve those bids given the base case bid. We have 6 unknowns and 8 equations — no problem…

However, we might very well find in the data that the device effect is hugely dependent on proximity. With a better understanding of store spillover, we’re likely to find that we should bid more on mobile searches conducted near our stores — or near a competitor’s! — which would yield an unsolvable system of equations.
We don’t have the flexibility to set a different mobile modifier dependent on proximity. We are forced to compromise in our targeting and be smart about which compromises produce the best outcome. Not ideal.
There Are Better Solutions
The ideal solution is to scrap modifiers and allow advertisers to calculate and set discrete bids for each possible combination of modifier states. Our rudimentary model required 8 bids; however, in the real world, this may necessitate setting hundreds, possibly thousands of bids for each ad for each context… each time you set bids, which might be hourly.
We’d be game for that for the sake of precise targeting, but I doubt Google will go that route. Doing so would create controls and a level of complexity that only sophisticated platforms could play with through API integrations, and they have historically wanted to avoid having separate sets of controls for “experts only.”
In truth, when data is sparse, high rent statistical models have to make assumptions under the hood about degrees of independence, so granular estimates of traffic value might line up better with the independence assumption than they should, simply because they have to make similar assumptions.
It could also be the case that the effects referenced are largely independent of each other and only conflict episodically.
If that is the case, the better solution may be to simply allow some conditional logic. The case in which mobile modifiers need to vary with proximity could be handled by a rule that says something to wit: “if proximity = close, then set mobile modifier = +30%; else set mobile modifier = -50%.”
Limited inter-dependencies could be handled fairly well with rules rather than the full blown matrix approach.
We remain excited about the improved ability to target based on context. Replicating campaigns across massive accounts was not scalable, particularly as we roll into having more and more controls through Enhanced Campaigns. There are issues to be addressed, certainly, but imperfect granular controls are better than no controls.
As we outlined in our Q3 Digital Marketing Report, the ability to set device modifiers for all AdGroups dynamically (dayparting on our end so we can handle device effects that change day to day) has led to improvements in smartphone ROI and revenue volume — a nice win rolling into Q4.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author