Enterprise SEO Audits – Go Beyond The Desktop Crawl
Digital technology — and the way consumers are using it — is evolving at a pace never seen before, and the platforms and tools used by digital marketers are trying to keep up with it all. We all know content is still king. In order to win the battle for the consumer’s attention, or Google […]
Digital technology — and the way consumers are using it — is evolving at a pace never seen before, and the platforms and tools used by digital marketers are trying to keep up with it all.
We all know content is still king. In order to win the battle for the consumer’s attention, or Google rankings, you need to provide quality content and lots of it. (See my article, 3 Tips To Beat The Volume Game, for in-depth discussion on massive internet content growth.)
To satisfy this insatiable demand, content management systems and platforms have had to evolve and allow for the agile and dynamic creation and deployment of content. As you take any SEO recommendation and distill it down, a single message appears: “Build more pages.”
This brings me to the root of this article — performing SEO audits in the enterprise-level world where the number of website pages has become limitless.
Enterprise Level SEO Audits
Simply put, websites are getting increasingly larger and search marketers have to work with dynamically generated pages, master-detail sets, online directories, e-commerce pages, product reviews, shopping carts, dynamic comparison pages, mobile-only content, tags and read-more links, making the average number of pages skyrocket.
Along comes the search marketer who used to have to optimize 50 pages and thought that was challenging; now we are looking at thousands of pages, which creates huge technological and resource challenges when performing technical audits.
Desktop Crawls
Our crawling tool of choice for technical audits is Screaming Frog. It’s an amazing program that will perform any technical SEO audit in the blink of an eye with an incredible level of detail and flexibility. However, like any desktop audit tool, it has four major limitations caused by the simple fact that it is a desktop application.
- Memory Limitations: Desktop crawlers are limited by the amount of memory on the user’s machine. When you are running audits on large sites with 10k+ pages, the crawler dies very quickly due to memory limits.
- Timing: A desktop crawler can only run when the computer is turned on. That prevents you from running automated crawls or monitoring proactively for issues.
- Architecture: Desktop crawlers are fairly flat, file storage applications that do not use smart databases. That means you cannot create rules around them (example: If # of errors > 500 = Send email).
- Collaboration: All of the results sit on a local drive, located and available on a single machine; there is no way to collaborate, share and co-work on the audit.
Note: This is not intended to be a comparison between DeepCrawl (described below) and Screaming Frog; they both have their own unique strengths and applications, and we utilize both of them heavily.
Server-Based Crawls
We set out to evaluate a number of different solutions that would allow us to perform technical audits on a larger scale. We excluded any of the “Suite” providers, as we had very specific needs and wanted a partner that focuses purely on auditing, instead a ranking tool that also does XYZ.
We came across DeepCrawl. DeepCrawl is a server-based solution, so it removes all the limitations you experience with a desktop audit tool — it can run at any time, and the size of your computer’s memory doesn’t matter.
Additionally, DeepCrawl was the only tool that also provided a full-featured API within the application; this allows us to manage sites, initiate crawls and receive results in a scalable and automated way.
Getting Started With DeepCrawl
Today, I want to share with you how we use this tool and how you can get started with it rather quickly.
After you create an account and get the basics set up, you can create your first crawl. One of the interesting features of DeepCrawl is the ability to feed it input from more than a single source. Most crawlers let you choose a single method (sitemap, crawl, list, etc.) but in DeepCrawl, you can conduct a “universal crawl”; this will collect information simultaneously from sources such as:
- Your Sitemap.xml
- A custom list of URLs
- The manual crawl (which it will do)
- Google Analytics
I really like this approach, as it ensures we are also crawling and monitoring PPC landing pages, campaign pages and any other content that is not publicly linked.

The configuration options in DeepCrawl are very flexible. There are a ton of them, so make sure you only crawl what you want. You can define things such as:
- Crawl depth
- Page limit
- Regular Expression rules
- URL sampling
- Variable exclusion
- Geo-based crawling (mobile, US, local etc.)
- Staging server (special URLs requiring authorization)
- Using custom URL rewrites
- And much more
As DeepCrawl is a SaaS (Software as a Service) model, you pay per crawled URL, so it’s crucial to be careful when creating your configuration so you only pay for the URLs you want to audit.
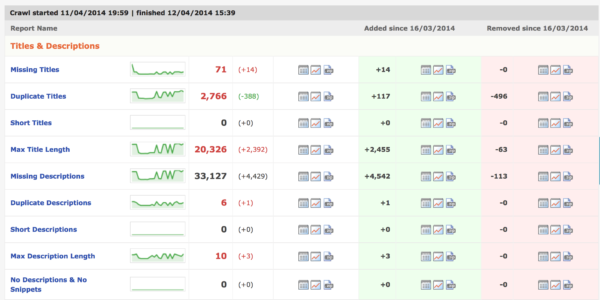
Depending on the size of the site and options, the actual crawl can take quite a while to perform. We are currently using DeepCrawl on sites with 500k+ pages, and it can take a few days. Once the crawl is finished, you will be presented with a very complete report, like the one shown below.

While DeepCrawl is a great all-purpose crawler and audit tool, the fact that it is database-driven and very flexible allows for some pretty creative “hacks.” Below are some of my favourite uses for it.
1. Proactive Change Monitoring
A great feature of DeepCrawl and other server-based audit tools is the ability to schedule crawls on set intervals (daily, weekly, monthly, etc.). No matter if you are in social, SEO or SEM, we all know that pages break or get removed, and we are the last ones to know. You can configure DeepCrawl to inform you of any changes; that way you know when a page is down and can take action.
2. Competitive Monitoring
What are our competitors doing? Are they developing new content? That’s a question we can’t always answer without a lot of manual research. This is a perfect use case for DeepCrawl’s comparison reports.
Set up a weekly report to monitor your competitors; you’ll get an email when they add new pages, and you will always know what they are doing and gain a better understanding of their digital strategy.
3. Implementation Tracking
A project manager’s dream comes true. In DeepCrawl, you can create tickets for changes that need to be made (example: fix broken links, missing canonical, etc.); then, each time DeepCrawl runs its audit, it checks and notifies you if they have been implemented or not.
As an extra bonus, it maintains a history, so if the changes get done but are overwritten during the next server deployment, you will know that as well.
![]()
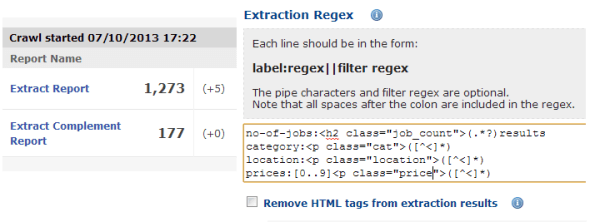
4. Content Extraction
This advanced feature allows you to analyse the code of the raw HTML of the scanned pages and check for specific values. This will add extra depth to your data.
As an example, you could collect the social signals for each page in order to prioritize optimization. You can learn more about this process here.
I hope this gives you a good idea on the capabilities and features of server-side auditing tools. To be honest, in my job, I could not live without it anymore. I think that is where truly the innovation lies — how to leverage existing tools and technologies to make a better impact and drive stronger results.
If you are using a tool like this, I would like to hear about some other creative use cases you’ve discovered for it.
Stock image used by permission of Shutterstock.com
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
About the author