Priorities for diagnosing JavaScript-powered websites
Contributor Maria Cieslak digs into JavaScript and some of the chaos associated with it and compiles a detailed checklist you can use as a starting point for deeper analysis.

In the last 20 years, Google’s search engine has changed a lot. If we take a look at technology and web development as a whole, we can see the pace of change is pretty spectacular.
This website from 1998 was informative, but not very attractive or easy to use:
Modern websites not only look much better, but they are equipped with powerful features, such as push notifications, working partially offline and loading in a blink of the eye.
But if we want to be accurate, we should use the term “apps” instead of “websites,” since websites are interactive, dynamic and built with JavaScript.
JavaScript as a game-changer
For the longest time, Google couldn’t execute JavaScript, but then in 2015, the company took a giant step forward in processing JavaScript.
It needs to be stressed that the evolution of a search engine is much slower than what happens in the web development niche, which may be why Google is still the ONLY search engine which can execute JavaScript.
At the very beginning, when the World Wide Web was built with websites made up of only static hypertext markup language (HTML), Google had a simple task to complete:
Make a request to the server → get the static HTML response → index the page
I know this is a super-simple description of the process, but I want to show the differences between processing websites back when and processing websites today.

The problem arose when developers started using JavaScript (JS) for adding interactivity on websites and then accelerated when dependencies on JavaScript became bigger when Javascript was used to create an entire website.
JavaScript apps and websites are challenges for Google because, after the initial request is sent to the server, Googlebot receives an empty or almost-empty HTML file. The content, images and links are added after JS’s execution.
Google solved the issue by trying to render almost all the pages they visit. So now ,the process looks more or less like this:
Make a request to the server → GET the static HTML response → Send it to the indexer → Render the page →
Index and send the extracted links to Googlebot → Googlebot can crawl the next pages.
JavaScript execution added a lot of inefficiency and delays to the process of crawling, rendering and indexing because:
- Googlebot’s crawling is slowed down. It doesn’t see hyperlinks in the source code of a JS website so it needs to wait for the indexer to render the page and then sends the extracted URLs back.
- Executing JavaScript needs many resources. It’s exhausting even for Google’s data centers.
Despite these obstacles, we need to be prepared for a big boom in developing dynamic JS applications as interest in open-source frameworks such as React, Vue.js or Angular continues to skyrocket. More and more websites will be built with JavaScript. so as SEOs, we need to be able to spot problems on websites using it.

The proper approach
Before we start digging deeper into JavaScript and some of the chaos associated with it, let’s look at three aspects which will adjust our approach to analyzing the websites:
A. What’s the scale of the problem?
We need to understand and make a clear delineation between websites (apps) built with JavaScript, like Single-Page Apps (SPA) and partial dependencies on JavaScript. Here are some possible scenarios and how to tell what is built with SPA and what are partial dependencies:
- No JavaScript dependencies. Visit our website and switch JS off in the browser — nothing changes.
- Partial JS dependencies. Visit the Angular.io website and switch JS off in the browser — the main navigation doesn’t work (but links are available in the document object model [DOM], which I’ll talk about later).
- Meaningful JS dependencies. Visit the AutoZone and switch JS off — the main navigation might not work, and the links might not be available in the DOM.
- Complete JS dependencies. Visit YouTube, switch JS off and notice all of the content disappears!
As you probably guessed, if you have partial dependencies on JavaScript, you have fewer problems to solve.
B. Where is the website built?
Static HTML websites are built on your server. After an initial request from Googlebot (and users, too), it receives a static page in response.
Dynamic web apps (DWA) are built in the browser, so after an initial request, we receive an empty or almost empty HTML file, and the content is loaded in an asynchronous way with JavaScript. Looking at the bigger picture, we can assume that client-side rendering is the real villain when it comes to problems with JS and search engine optimization (SEO).
C. What limits does Google have?
Some time ago, Google revealed how it renders websites: Shared web rending services (WRS) are responsible for rendering the pages. Behind them stands a headless browser based on Chrome 41 which was introduced in 2015, so it’s a little out of date. The fact that Google uses a three-year-old browser has a real impact on rendering modern web applications because it doesn’t support all the current features used by modern apps.
Eric Bidelman, an engineer at Google, confirmed that they are aware of the limits Google has with JS. Based on unofficial statements, we can expect that Chrome 41 will be updated to a more recent version at the end of 2018.
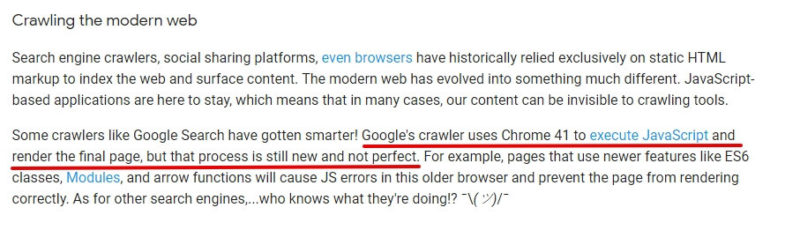
To get significant insight into what is supported and not supported, visit Caniuse.com and compare Chrome 41 with the most recent version of Chrome. The list is long:

Processing resources
Timeouts are the next thing that makes JS and SEO a difficult match.
JavaScript apps are usually extremely heavy, and Google has limited resources. Imagine that, in JavaScript’s case, Google needs to render each page to see the content. The example below shows how heavy JS execution is.
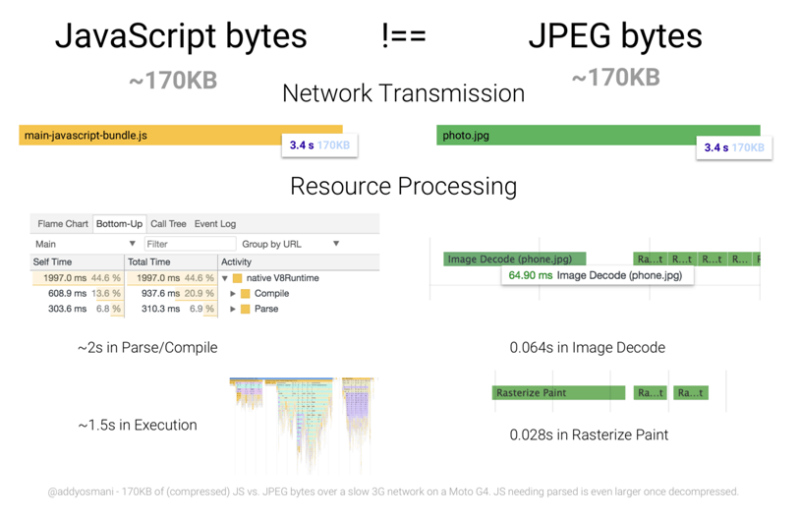
If you have a JS file and an image file of the same size, you will see that it takes approximately 2 seconds to parse, and then approximately 1.5 seconds to execute JavaScript.
Google needs to reasonably manage its processing resources because of the massive amount of data it needs to process. The World Wide Web consists of over a billion websites, and it’s growing every day. The chart below shows that the median size of the desktop version of the pages increased by almost 100 percent in the last five years. The adequate metric for the mobile version of the website increased by 250 percent!

The natural consequences of JavaScript sites are delays in the crawling, indexing and, finally, ranking of those websites.
Preparation and helpful resources
SEOs working on technical SEO need to pay attention to details. In the case of JavaScript websites, we need to be prepared for tricky problems we will need to solve, and we must understand we can’t always rely on the common and well-known rules.
Google knows SEOs and developers are having problems understanding search behavior, and they are trying to give us a helping hand. Here are some resources from Google you should follow and check to help with any JS issues you may have:
- Webmaster trends analyst John Mueller.
- Webmaster trends analyst Gary Illyes.
- Engineer Eric Bidelman.
- JavaScript Sites in the Google Search Forum.
- Video: “SEO best practices and requirements for modern sites” with John Mueller.
- Video snippet: “Deliver search-friendly JavaScript websites” from Google I/O 2018.
Diagnosing JavaScript-powered site problems
Now that we know the limits Google has, let’s try to spot some of the problems on a JavaScript website and look for workarounds.
What does Google see?
Three years ago, Google announced that it is able to render and understand websites like modern browsers. But if we look at the articles and the comments on rendering JS websites, you will notice they contain many cautionary words like: “probably,” “generally” and “not always.”
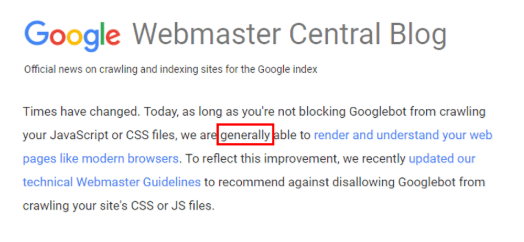
This should highlight the fact that while Google is getting better and better in JS execution, it still has a lot of room for improvement.
Source code vs. DOM
The source code is what Googlebot sees after entering the page. It’s the raw HTML without JS integration into the code. An important thing to keep in mind is the fact that Googlebot does not render the pages.
Googlebot is a crawler, so its job is to navigate through pages, extract the elements from the source code and send them to the indexer. A document object model (DOM) is the rendered version of the website, and it means that the raw HTML was altered by JavaScript, structured and organized.
The “Inspect Element” shows the document object model. Rendering is done by Web Rendering Service, which is a part of Google’s Indexer. Here are some important points to keep in mind:
- Raw HTML is taken into consideration while crawling.
- DOM is taken into consideration while indexing.
JavaScript websites are indexed in two waves, which puts the whole process of indexing in a totally different light:
- First wave: Google extracts only the metadata and indexes the URL based on this information.
- Second wave: If Google has spare resources, it renders the page to see the content. It can reindex the page and join these two data sources.
Bear in mind that in the second wave of indexing, Google doesn’t update the originally indexed elements if they were altered by JavaScript. If you add a rel=”canonical” tag with JavaScript, it will not be picked up by Google.
However, recently John Mueller said if Google gets stuck during the rendering of pages, a raw HTML might be used for indexing.
Even if you see that a particular URL is indexed, it doesn’t mean the content was discovered by the indexer. I know that it might be confusing, so here’s a small cheat sheet:
- To see the HTML sent to Googlebot, go to Google Search Console and use the Fetch and Render tool. Here you have access to the raw HTTP response.
- To see the rendered version of the page, you can use the Fetch and Render tool as well.
- To see the DOM built by the web rendering service (WRS) for desktop devices, use the Rich Results Test. For mobile devices, use the Mobile-Friendly test.
Google officially confirmed we can rely on these two methods of checking how Google “sees” the website:
and

Compare the source code with DOM

Now, it’s time to analyze the code and the DOM.
In the first step, compare them in terms of indexability, and check if the source code contains:
- Meta robots instructions like indexing rules.
- Canonical tags.
- Hreflang tags.
- Metadata.
Then see if they are compliant with the rendered version of the website.
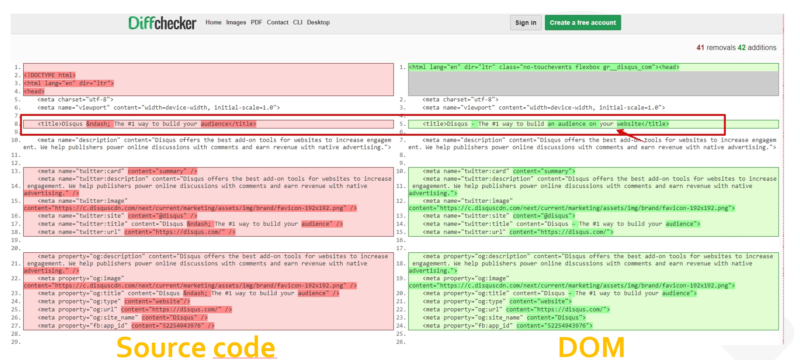
To spot the differences, you can use a tool like Diff Checker, which will compare text differences between two files.
Using Diff Checker, grab the raw hypertext transfer protocol (HTTP) response from the Google Search Console and compare it with the DOM from the tools mentioned in Point 3 above (the Rich Results test and the Mobile-Friendly test).
It may happen that JavaScript will modify some elements, and Google could have two different instructions to follow.
Googlebot doesn’t scroll
While looking at the DOM, it’s also worth verifying the elements dependent on events like clicking, scrolling and filling forms.
JavaScript allows for the loading of additional content, links and images after the user’s interaction. Googlebot does not scroll or click, so if something needs an action to be displayed, it won’t be discovered by Google.
Two waves of indexing and its consequences
Going back to those two waves I mentioned earlier, Google admits that metadata is taken into consideration only in the first wave of indexing. If the source code doesn’t contain robots instruction, hreflangs or canonical tags, it might not be discovered by Google.

How does Google see your website?
To check how Google sees the rendered version of your website, go to the Fetch as Google tool in Google Search Console and provide the URL you want to check and click Fetch and Render.
For complex or dynamic websites, it’s not enough to verify if all the elements of the website are in their place.
Google officially says that Chrome 41 is behind the Fetch and Render tool, so it’s best to download and install that exact version of the browser.
Once installed on your personal computer (PC), you can interact a little bit with the website, navigate to other sections and check the errors in the console triggered by JavaScript. A new feature in the Mobile-Friendly Test also makes it possible to see the errors with JavaScript in the JavaScript Console.
I’d like to mention some common and trivial mistakes to avoid:
- While diagnosing problems with rendering websites rich in JavaScript, never look into the cache in Google. It doesn’t provide meaningful information because the cache shows the RAW HTML seen by Googlebot which is rendered by your browser. The source code of JS websites consists of only a few lines of code, some hyperlinks to the scripts; the real content is loaded after JavaScript execution.
- Don’t block JavaScript resources in robots.txt; it prevents correct rendering (I know that this is obvious, but it still happens).
Internal links
Internal linking is the only way to make a website crawlable. Since the source code of JavaScript websites (in general) do not contain links, the whole process of crawling is delayed. Googlebot needs to wait to render the page by the Indexer and send the discovered links back.
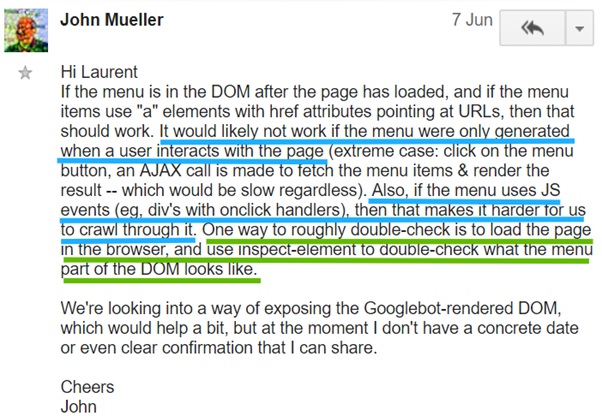
The crucial element of diagnosing JS websites is checking if links are placed in the DOM. The source code doesn’t have to contain links, but if the DOM doesn’t have them, the links won’t be discovered. This may have dramatic effects if the main navigation is built with JavaScript.
Be careful while analyzing mega menus. Sometimes they are packed with fancy features which are not always good for SEO. Here is a tip from John Mueller on how to see if the navigation works for Google:
Also be careful with “load more” pagination and infinite scroll. These elements are also tricky. They load additional pieces of content in a smooth way, but it happens after the interaction with the website, which means we won’t find the content in the DOM.
At the Google I/O conference, Tom Greenway mentioned two acceptable solutions for this issue: You can preload these links and hide them via the CSS or you can provide standard hyperlinks to the subsequent pages so the button needs to link to a separate URL with the next content in the sequence.
The next important element is the method of embedding internal links. Googlebot follows only standard hyperlinks, which means you need to see links like these in the code: (without the spacing)
text /a>
If you see OnClick links instead, they look like this and will not be discovered:
text
So, while browsing through the source code and the DOM, always check to be sure you are using the proper method on your internal links.
URLs — clean & unique
The fundamental rule to get content indexed is to provide clean and unique URLs for each piece of content.
Many times, JS-powered websites use a hashtag in the URL. Google has clearly stated that in most cases, this type of URL won’t be discovered by the crawler.
While analyzing the website, check to see that the structure is not built with URLs like these:
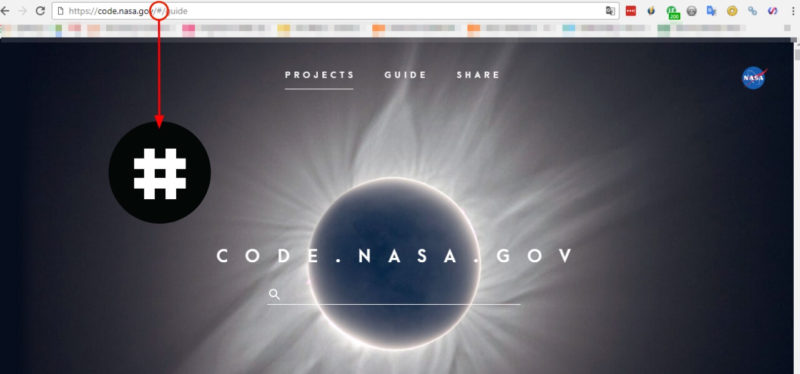
Everything after the # sign in the URL will be trimmed and ignored by Google, so the content won’t be indexed!
Timeouts
Nobody likes delays in rendering, even Google. It’s said that Google waits up to 5 seconds to get and execute JavaScript (Please note that the 5-second rule is based on observations and has not been confirmed by Google). I think Google must limit the maximum time for execution because rendering is a very resource-consuming process.
Unfortunately, diagnosing problems with timeouts is not easy. If we don’t serve the content fast enough, we can fail to get the content indexed.
In the case of JavaScript websites, you need to wait a while to load the additional elements, or even entire sections. The loader shows that something new will appear:

If JavaScript was executed on time, the web rendering service could render the page correctly and the content could be indexed loaded with JavaScript. However, if we look into the search results, we’ll see that the loader was indexed. Ugh!
How can we spot these problems? We can crawl the website with a tool like Screaming Frog with the delays set to 5 seconds. In rendering mode, you can see if everything is fine with the rendered version.
Don’t rely on checking delays in the Fetch and Render tool. It can wait up to 2 minutes for JavaScript, so it’s much more patient than Google’s Indexer.
John Mueller suggests we can check if Google rendered the page on time in the Mobile-friendly test, and if the website works it should be OK for indexing.
While analyzing the website, look to see if the website implements artificial delays like loaders, which forces waiting for content delivery:

There is no reason for setting similar elements; it may have dramatic effects in terms of indexing the content which won’t be discoverable.
Indexing
You gain nothing if the content is not indexed. It’s the easiest element to check and diagnose and is the most important!
Use the site:domain.com command
The most useful method of checking indexation is the well-known query:
Site:domain ‘a few lines of the content from your website’
If you search for a bit of content and find it in the search results, that’s great! But if you don’t find it, roll up your sleeves and get to work. You need to find out why it’s not indexed!
If you want to conduct a complex indexation analysis, you need to check the parts of the content from different types of pages available on the domain and from different sections.
Lazy-loading images
Google says there may be issues with loading “lazy” images:
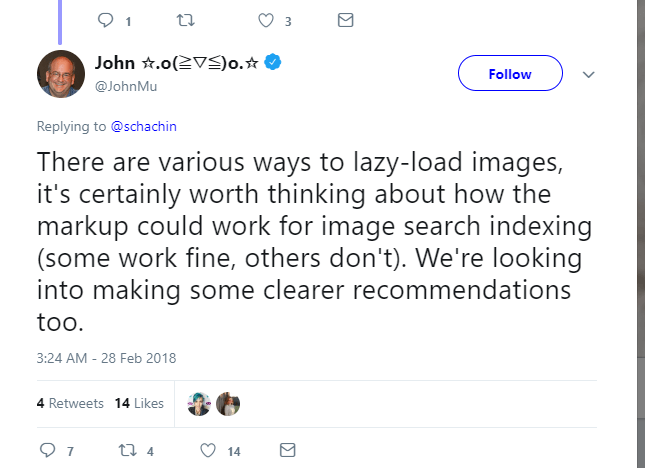
If your images are slow-loading, add a markup to the images you are serving which would make them visible if JavaScript is switched off.
The second option which makes lazy content discoverable to Google is structured data:

Wrapping up
Don’t use this article as the only checklist you’ll use for JS websites. While there is a lot of information here, it’s not enough.
This article is meant to be a starting point for deeper analysis. Every website is different, and when you consider the unique frameworks and individual developer creativity, it is impossible to close an audit with merely a checklist.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
About the author