Robots.txt File Case Study: How Third-Party Directive Changes Led To Leaking URLs And Lost SEO Traffic
Columnist Glenn Gabe shares his troubleshooting process for identifying issues with robots.txt that led to a long, slow drop in traffic over time.

I’ve written many times in the past about how technical SEO problems can lead to a serious drop in rankings and traffic. From the meta robots tag to rel=canonical to cloaked 404s, a number of problems can lie below the surface, causing serious damage to your website, SEO-wise.
Well, I unfortunately came across yet another situation recently that I’m going to cover in this post. The problem resulted in a slow leak of rankings and traffic, which made it hard for the business owner to notice. Before the company knew it, important pages had vanished from Google’s index.
What Happened? And The Importance Of Controlling Your Robots.txt File
When speaking with clients about SEO dangers, I often cover the robots.txt file. It’s a simple text file, but it can have a catastrophic impact on your SEO efforts if not handled correctly.
It reminds me of the “noisy cricket” from Men In Black. Small in stature, but powerful as heck.

Although most SEOs understand that a blanket disallow in robots.txt will cause massive issues, there are many other situations that can cause problems, as well.
Some can occur slowly and cause important URLs to leak from Google’s index — and if those URLs are important, then you’ve got a big problem on your hands. (And by the way, you won’t know it unless someone actually catches the problem.)
Traffic Drop, Rankings Gone & URLs DEINDEXED
A company reached out to me this fall after realizing it no longer ranked for some important category keywords. They were extremely concerned, to say the least.
But with many changes going on with Google, the drop in rankings could be anything, right? Maybe it was an algorithm update, maybe the competition upped its game, or maybe, just maybe, there was a technical problem causing the drop in rankings. So I jumped in to perform some detective work.
Upon digging into the situation, I quickly checked the URLs that were once ranking for category keywords. It was interesting to see that some URLs still ranked well, while others could not be found at all. Yes, some of the URLs had disappeared from Google’s index.
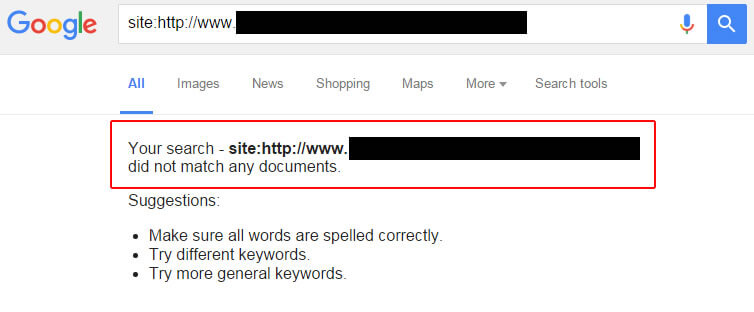
So I checked the meta robots tag. Not present. I checked the x-robots header to ensure noindex wasn’t being issued in the header response. Nope, that wasn’t the case.
Then it hit me. The category URLs I was checking were non-descriptive, complex and used mixed case. Basically, the CMS did not employ “pretty” URLs for a large percentage of pages on the site (based on how the CMS is set up).
I knew that in situations like this, it’s easy for URLs to get caught by greedy robots.txt directives. (“Greedy” simply means they can block more than they are supposed to.)
I fired up the robots.txt Tester in Google Search Console (GSC) and began testing category URLs. Bingo. Some URLs were showing as blocked, while others were allowed.
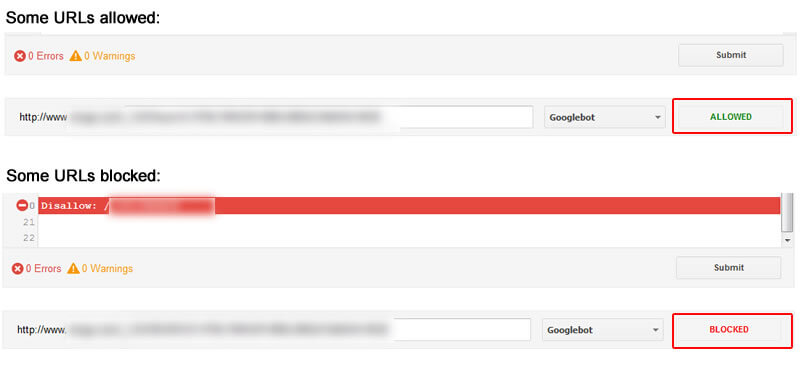
I also exported a list of URLs that previously received traffic from Google organic and crawled them. That enabled me to view any URL that was currently being blocked by robots.txt (in bulk). Again, some were blocked and some allowed. After heavily analyzing the situation, it ended up being two problems.
Surfacing 2 Important Problems: Case-Sensitivity & Third-Party Directive Changes
Reviewing the robots.txt file over time, I saw two major issues that were troubling.
First, new directives were being added to robots.txt by the CMS provider, and the website owner had no idea that was going on. The site has tens of thousands of URLs indexed, so even a minor change in robots.txt directives could be dangerous.
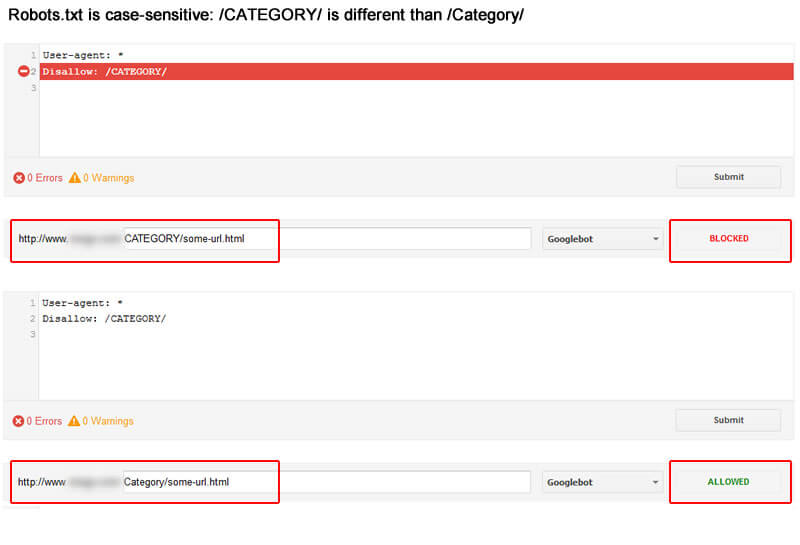
Second, directives had changed case slightly. That means those directives could mistakenly pick up or miss URLs on the site.
For example, if you were targeting the directory /Category/ but the directive is /CATEGORY/, then you would not disallow URLs that resolve in the /Category/ directory, as directives are case-sensitive. That’s an important point to note for every SEO, webmaster and business owner. See the screenshot below.
The Danger Of A Slow Leak
Between directives being added/deleted over time and case sensitivity changing, the company had important category URLs unknowingly getting disallowed. When URLs are disallowed, Google cannot crawl the pages to determine the content they contain, and this caused some of those URLs to drop from Google’s index over time. Not good.
But here’s the rub: URLs often do not drop from the index immediately — so the problem became very hard for the company to detect. There wasn’t a big drop on one day; instead, they experienced a slow leak of important URLs from Google’s index. As you can guess, rankings and traffic leaked as the URLs dropped from the index.
John Mueller On Robots.txt
In August of this year, Google Webmaster Trends Analyst John Mueller recorded an entire webmaster hangout dedicated to robots.txt. For people involved with technical SEO, it’s a must-watch.
One thing that stood out was John explaining how disallowed URLs are handled by Google, indexation-wise. For example, will disallowed URLs remain in the index, will they drop out, and how long will it take for them to drop out?
At 32:34 in the video, John explained that Google will drop information about disallowed URLs from previous crawls, and it might index the URLs with just basic information.
In addition, Google can drop those URLs from the index over time. There’s no guarantee the URLs will be dropped, but that can definitely happen. See the video here:
So when you have a situation where you are mistakenly disallowing URLs from being crawled, they might remain in the index for a while until Google decides to drop them. And when Google finally drops them, you won’t have any sign they are gone (other than a drop in traffic to those URLs). Beware.
And if you want to hear John speak about case sensitivity, you can watch 13:50 in the video. He covers some important points about directives, case sensitivity and character matching.
How To Avoid Leaking URLs Due To Robots.txt Changes
So how can you avoid this happening on your own site? I’ll provide several bullets below that can help you understand when changes are being implemented to your robots.txt file and how to uncover if URLs that used to drive traffic are being disallowed by robots.txt.
This is by no means a final list of recommendations, but the bullets below can definitely help you avoid SEO disaster due to robots.txt issues.
- Crawl and audit your site regularly. I’ve been saying this a lot recently. The more you can crawl your site, the more you can understand its strengths, weaknesses and risks. And as part of the crawl, you can view disallowed URLs via a number of tools (including Screaming Frog, DeepCrawl, and other crawling tools). You might just pick up important URLs being blocked. If so, dig in and root out the problem.
- Robots.txt change history. You can request notifications from your CMS provider whenever changes are made to your robots.txt file. If they can email or message you about those changes, then you can quickly check them out. And you can move quickly to fix any problems.
- Auto-detect changes to robots.txt. You can also use a service that pings your robots.txt file daily. Whenever it picks up a change, it will email you. Then you can review and make changes, where necessary. It’s like a Google Alert for technical SEO. For example, Robotto can detect a number of important changes and notify you.

- Audit Google Search Console (GSC) continually. You should continually audit Google Search Console reports. There are several reports that can help you identify new problems with your site from a technical SEO standpoint. For this situation, using the robots.txt Tester on important URLs would help. You can also check Index Status for “blocked by robots,” which could reveal an increase in the number of URLs blocked by robots.txt (which could raise red flags). And then you can check Smartphone Crawl Errors for “Blocked.” This can be found in the Smartphone tab but can absolutely relate to desktop URLs, as well.
- Use the Wayback Machine to check robots.txt. Yes, you can use the wayback machine to review your robots.txt file over time. For many sites, you will see the various versions of robots.txt picked up over the life of the website. It might provide important clues about a drop in pages indexed.


Summary: Checking “Under The Hood,” SEO-Wise
As you can see with this case, technical SEO changes can have a big impact on rankings and traffic. Although robots.txt is a simple text file, the directives it holds can block important URLs from being crawled (which can result in those URLs being dropped from Google’s index).
And if those pages are dropped from the index, they have no chance at ranking. And with no chance at ranking, they can’t drive traffic. This means you lose, while the greedy robots.txt file wins. Don’t let it win. Follow my recommendations above and avoid leaking URLs.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. Search Engine Land is owned by Semrush. Contributor was not asked to make any direct or indirect mentions of Semrush. The opinions they express are their own.
