What is semantic search: A deep dive into entity-based search
Semantics = theory of meaning, yet most define semantic search with a focus on intent. “Meaning” is not the same as “intention.” Learn more.
Since 2013, Google has been gradually developing into a 100% semantic search engine.
What exactly is semantic search? You can find plenty of explanations when you search Google for an answer to that question – but most of those are imprecise and create misunderstandings.
This article will help you comprehensively understand what semantic search is.
Google’s road to becoming a semantic search engine
Google’s efforts to develop a semantic search engine can be traced back to 1999 (as seen in this post by the late Bill Slawski). This became more concrete with the introduction of the Knowledge Graph in 2012 and the fundamental change in its ranking algorithm in 2013 (popularly known as Hummingbird).
All other major innovations such as RankBrain, E-A-T, BERT and MUM either directly or indirectly support the goal to become a fully semantic search engine.
By introducing natural language processing (NLP) to search, Google is moving at an exponential rate toward this goal.
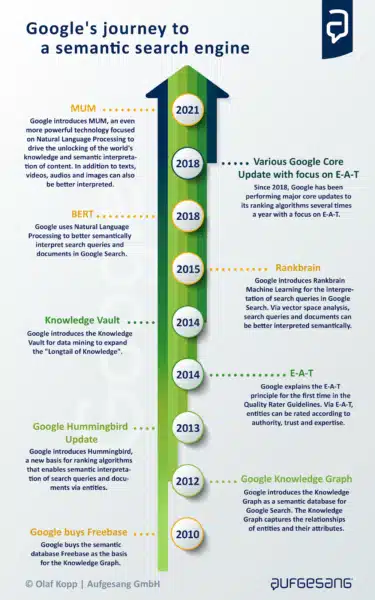
Hummingbird: ‘Not strings, but things’ = entities
Hummingbird is the starting signal of Google’s evolution into a semantic search engine.
It was the biggest search query processing and ranking change ever made by Google, affecting over 90% of all searches as early as 2013. Hummingbird fundamentally replaced much of the existing ranking algorithms.
Through Hummingbird, Google was immediately able to include entities recorded in the Knowledge Graph for query processing, ranking and the output of SERPs.
An entity describes the essence or identity of a concrete or abstract object of being. Entities are uniquely identifiable and therefore uniquely meaningful.
Basically, a distinction can be made between named entities and abstract concepts.
- Named entities are real-world objects, such as people, places, organizations, products, and events.
- Abstract concepts are physical, psychological, or social in nature, such as distance, quantity, emotions, human rights, peace, etc.
Before Hummingbird, Google primarily did keyword document matching for ranking and could not recognize the meaning of a search query or content.
What is a semantic search engine?
A semantic search engine considers the semantic context of search queries and content to better understand meaning. Semantic search engines also consider the relationships between entities for returning search results.
In contrast, purely keyword-based search systems only work on the basis of a keyword-text match.
What is semantic search?
Many definitions of semantic search focus on interpreting search intent as its essence. But first and foremost, semantic search is about recognizing the meaning of search queries and content based on the entities that occur.
Semantics = theory of meaning.
But “meaning” is not the same as “intention.” The search intent describes what a user expects from the search results. Meaning is something else.
Identifying meaning can help recognize search intent, but is more of an additional benefit of semantic search.
The role of the Knowledge Graph in Google’s semantic search
Entity-based ranking also requires entity-based indexing. The Knowledge Graph is Google’s entity index that takes into account relationships between entities.
Classic indices are organized in tabular form and, therefore, do not allow for mapping relationships between datasets.
The Knowledge Graph is a semantic database in which information is structured in such a way that knowledge is created from the information. Here, entities (nodes) are related to each other via edges, provided with attributes and other information and placed in thematic context or ontologies.
Entities are the central organizational element in semantic databases, such as Google’s Knowledge Graph.
In addition to the relationships between the entities, Google uses data mining to collect attributes and other information about the entities and organizes them around the entities.
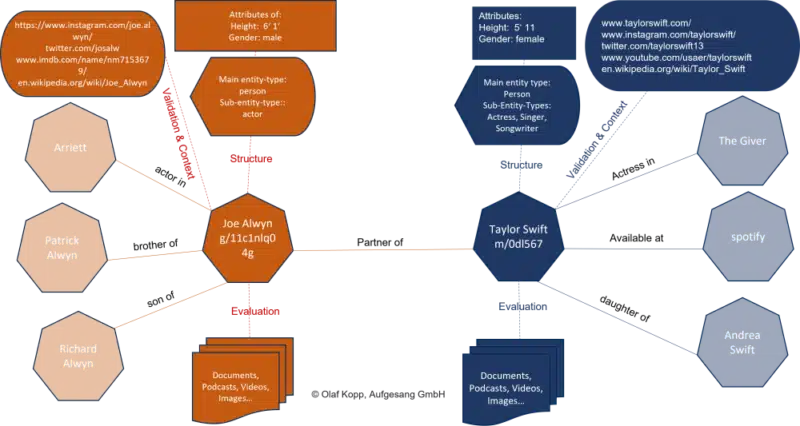
You get an impression of which sources and information Google considers for an entity when you search for it.
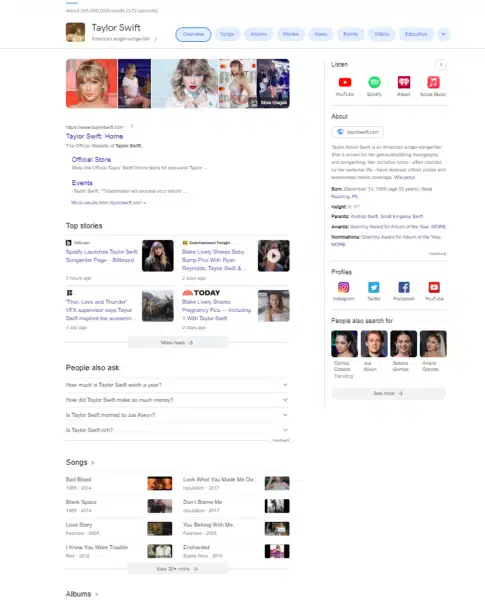
The preferred sources, attributes and information vary depending on the entity type. A person entity’s sources are different from an event entity or organizational entity. This impacts the information displayed in a knowledge panel.
The structure of an entity-based index allows for answers to questions that search for a topic or entity that is not mentioned in the question.
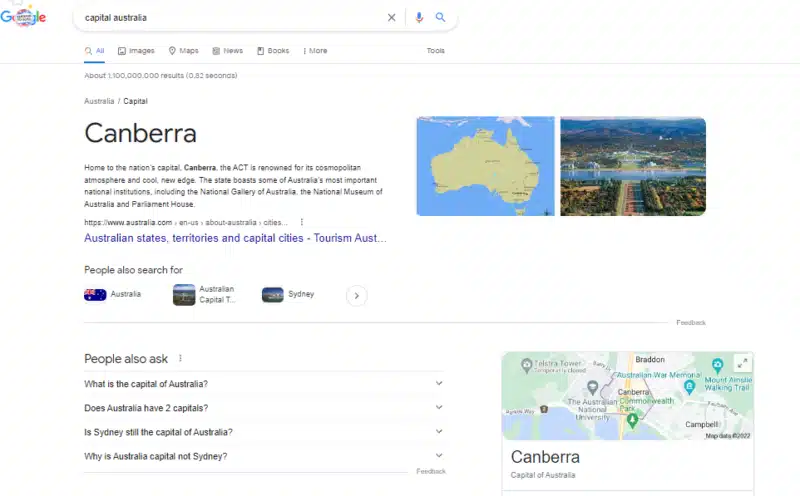
In this example, “Australia” and “Canberra” are the entities and the value “capital” describes the nature of the relationship. A keyword-based search engine could not have returned this answer.
Three levels serve as the basis for a Knowledge Graph:
- Entity catalog: All entities that have been identified over time are stored here.
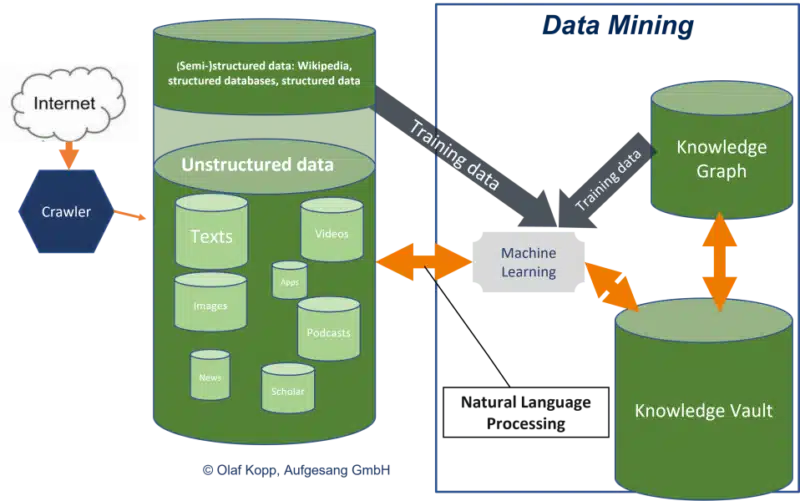
- Knowledge repository: Entities are brought together in a knowledge depot with information or attributes from various sources. This is primarily about merging and storing descriptions and creating semantic classes or groups in the form of entity types. Google generates the data via the Knowledge Vault, where it operates data mining from unstructured sources.
- Knowledge Graph: Entities are linked to attributes and relationships are established between entities.
Google can use various sources to identify entities and their associated information.
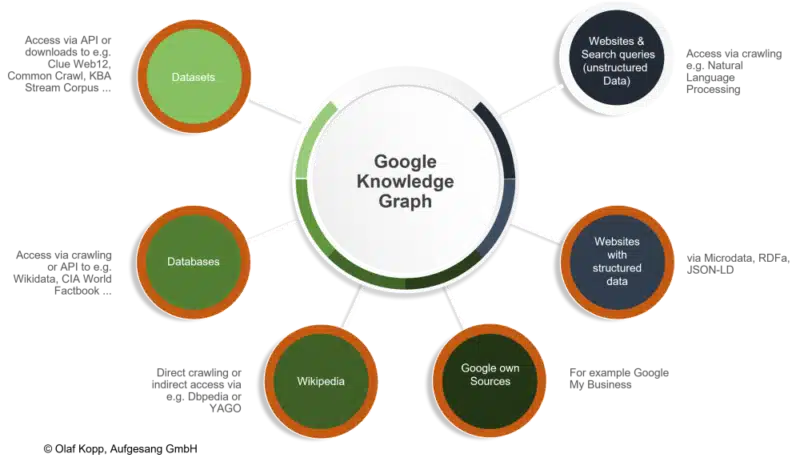
Not all entities captured in the knowledge repository are included in the Knowledge Graph. The following criteria could influence inclusion in the Knowledge Graph:
- Sustainable social relevance.
- Sufficient search hits for the entity in the Google index.
- Persistent public perception.
- Entries in a recognized dictionary or encyclopedia or in a specialist reference work.
It can be assumed that Google has recorded significantly more long-tail entities in a knowledge repository such as the Knowledge Vault than in the Knowledge Graph and uses it for semantic search.
By crawling the open internet and through natural language processing, Google is able to carry out scalable entity and data mining independently of structured and semi-structured databases. This provides the Knowledge Vault with more and more information, including on long-tail entities. You can find more about this here.
How does Google work as a semantic search engine?
Google uses semantic search in the following areas:
- Understanding search queries or entities in search query processing.
- Understanding content about entities for ranking.
- Understanding content and entities for data mining.
- Contextual classification of entities for later E-A-T evaluation.
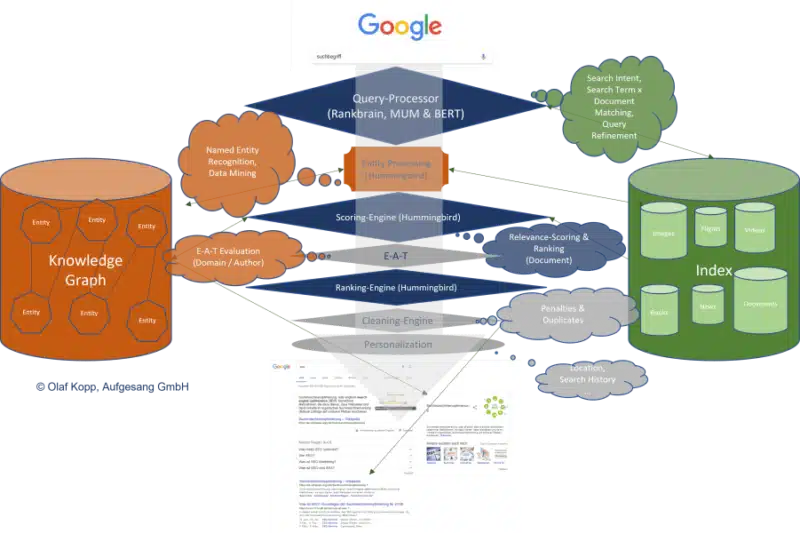
Google search is now based on a search query processor for the interpretation of search queries and the compilation of corpuses from documents relevant to the search query. This is where BERT, MUM and RankBrain may come into play.
In search query processing, the search terms are compared with the entities recorded in the semantic databases and refined or rewritten if necessary.
In the next step, the search intent is determined and a suitable corpus of X content is determined.
Google uses the classic search index as well as its own semantic database in the form of the Knowledge Graph. It is probable that an exchange takes place between these two databases via an interface.
There is a scoring engine consisting of different algorithms based on Hummingbird’s core algorithm. It is responsible for evaluating content and then putting it in an order based on the scoring. Scoring is about the relevance of content in relation to the search query or search intent.
Since Google also wants to evaluate the quality of content in addition to relevance, an evaluation according to E-A-T criteria must also be carried out. You can find out which criteria these could be in 14 ways Google may evaluate E-A-T.
For this E-A-T evaluation, Google must assess the expertise, authority and trustworthiness of the domain, the publisher, and/or author. The semantic entity databases can be the basis for this.
Search results are then freed of duplicates via a cleaning engine and any penalties are taken into account.
What does this mean for semantic SEO?
I read a lot about structured data, the semantic optimization of content and the structure of semantic topical worlds when it comes to semantic SEO.
Yes, it makes sense to show Google that you completely cover certain topics with your content and, therefore, show expertise.
Some patents deal with the comparison of documents’ internal knowledge graphs with the Google Knowledge Graph. The theory here is that a high level of correspondence between the entities used in a text and the relationship structures of the main entity in Google’s semantic database leads to better rankings.
That sounds logical. But let’s be honest, in the end, keyword-based optimization does not differ significantly from entity-based content optimization.
The structure of topical worlds also makes sense, although it has to be said that in times of passage ranking, the following should be considered:
- Up to what extent is a theme broken down into various sub-themes?
- Is separate content produced for each sub-theme?
- Is there only a holistic content asset created?
And structured data…
Yes, structured data can help Google understand semantic relationships, but only until they no longer need it. And that will be soon.
In my opinion, Google is so good at machine learning that they are using structured data to train the algorithms faster.
Let’s take markups for social media profiles as an example. It took only about a year from the time Google recommended its use until they announced they can automatically see social profiles without structured data.
It’s just a matter of time before Google no longer needs structured data.
Structured data is also not a good basis for an evaluation. You either have them or you don’t.
You can count all of this to semantic SEO. However, what I often miss is the global view of entities as publishers and authors. More off-page than on-page signals play a role here. Based on the relationships between authoritative and credible entities, Google wants to determine which domains and authors are the best quality sources for a topic according to E-A-T.
- Who is related to whom?
- Who recommends whom?
- Who hangs out with whom?
Links and co-occurrences from Google can be used as factors for this proximity between authority entities. And by semantic SEO, I also mean optimizing them.
While we’re on the subject of co-occurrence, you should also consider how NLP works when optimizing content. Google uses NLP to identify entities and their context. This works via grammatical sentence structures, triples and tuples made up of nouns and verbs.
That is why we should also pay attention to a grammatical simple sentence structure in semantic SEO. Use short sentences without personal pronouns and nesting. This is how we serve users in terms of readability and search engines.
The future of semantic search: When can a 100% entity-based Google search be achieved?
I think that in the future there will be an increasing exchange between the classic Google search index and the Knowledge Graph via an interface.
The more entities are recorded in the Knowledge Graph, the greater their influence on the SERPs. However, Google still faces the major challenges of reconciling completeness and accuracy.
For Hummingbird’s actual scoring, the document-level entities do not play a major role. Rather, they are an important organizational element for building unweighted document corpuses on the search index side.
The actual scoring of the documents is done by Hummingbird according to classical information retrieval rules. However, on the domain level, I see the influence of entities on ranking much higher. Enter E-A-T.
In the next years, we’ll most likely see the increasing impact of entities in Google search. The new appearance of entity-based searches clearly shows how Google is gradually organizing the indexing of information and content around an entity. This indicates how strongly innovations like MUM follow the idea of a semantic search.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. Search Engine Land is owned by Semrush. Contributor was not asked to make any direct or indirect mentions of Semrush. The opinions they express are their own.


