How Trust & Unique Identification Impact Semantic Search
Is your content trustworthy, and does that matter? Columnist Barbara Starr explores how Google might be using trust as a signal when displaying search results.

There are many factors that are key to the notion of semantic search. Two that are critical to understand that have not been written about much from an SEO point of view are trust and unique identification.
These two factors lie at the core of the many changes we see happening in search today, alongside Google’s ever-growing knowledge graph and their move in the direction of semantic search.
The Semantic Web Stack
The notion of trust is a key component in the semantic web. Below is an illustration that depicts the semantic web stack, with trust sitting at the top.

Semantic Web Stack (Source: https://en.wikipedia.org/wiki/Semantic_Web_Stack)
Trust is achieved through ascertaining the reliability of data sources and using formal logic when deriving new information. Computers leverage or mimic this factor in human behavior in order to derive algorithms that provide relevant search results to users.
Search Result Ranking Based On Trust
Search Result Ranking Based on Trust is, in fact, the name of a Google patent filed in September 2012. The patent describes how trust factors can be incorporated into creating a “trust rank,” which can subsequently be used to alters search result rankings in some fashion.
People tend to trust information from entities they trust, so displaying search results to users from entities they trust makes a lot of sense (and also brings in a personalization component).
A group at Google recently wrote a paper titled, Knowledge-Based Trust: Estimating the Trustworthiness of Web Sources. The paper discusses the use of a trustworthiness score — Knowledge-Based Trust (KBT) — which is computed based on factors they describe therein.
Below, I have extracted some salient features from the paper that I believe are worth understanding from an SEO POV:
We propose using Knowledge-Based Trust (KBT) to estimate source trustworthiness as follows. We extract a plurality of facts from many pages using information extraction techniques. We then jointly estimate the correctness of these facts and the accuracy of the sources using inference in a probabilistic model. Inference is an iterative process, since we believe a source is accurate if its facts are correct, and we believe the facts are correct if they are extracted from an accurate source.
The fact extraction process we use is based on the Knowledge Vault (KV) project [10]. KV uses 16 different information extraction systems to extract (subject, predicate, object) knowledge triples from webpages. An example of such a triple is (Barack Obama, nationality, USA). A subject represents a real-world entity, identified by an ID such as mids in Freebase [2]; a predicate is predefined in Freebase, describing a particular attribute of an entity; an object can be an entity, a string, a numerical value, or a date.
I also most definitely enjoyed the introduction here:
Quality assessment for web sources is of tremendous importance in web search. It has been traditionally evaluated using exogenous signals such as hyperlinks and browsing history. However, such signals mostly capture how popular a webpage is. For example, the gossip websites listed in [16] mostly have high PageRank scores [4], but would not generally be considered reliable. Conversely, some less popular websites nevertheless have very accurate information.
What can be garnered from this is that SEO practitioners should ensure that all statements written on any website or blog are factual, as this will enhance trustworthiness (which may one day impact rankings).
When it comes to searching for entities in Google, it is clearly evident that they use some form of a trust-based mechanism. Users tend to trust online reviews, so reviews and review volumes are useful to users when they search for a specific product. As a case in point, a search for the product “La Roche Posay Vitamin C eyes” yields the following result in organic SERPs:
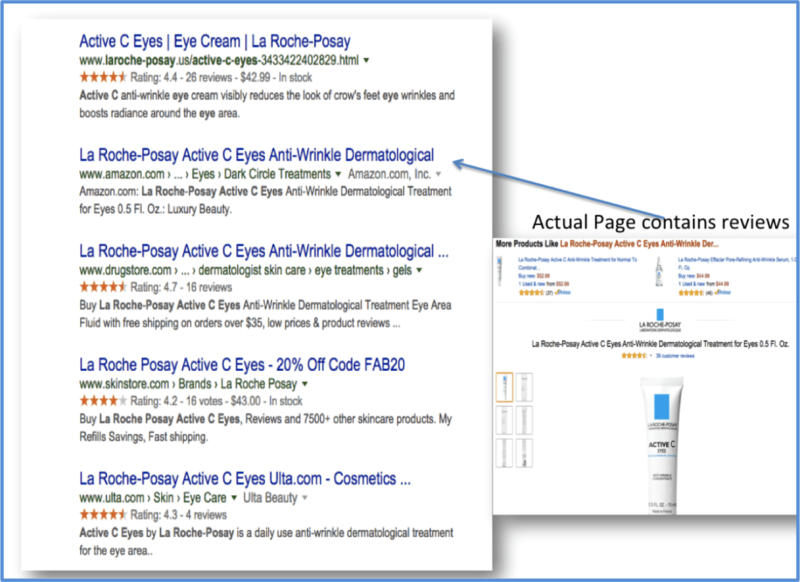
Google Search for “La Roche Posay Vitamin C eyes” — Organic Results
The only example that shows up without the enhanced displays associated with reviews (rich snippets) is a page that, when selected, does in fact contain reviews from an authoritative and trusted source (Amazon).
The “most trusted” result is given first, as that comes from the official website of the brand and the reviews page associated with that product. This is a pattern that seems to be quite prevalent in a large majority of product searches at this point in time.
I have written in the past about how another Google patent may utilize reviews in search results in such a manner, and I will quote a relevant portion of the referenced patent here:
The search system may use the awards and reviews to determine a ranking of the list, and may present the search results using that ranking.
Unique Identifiers In E-Commerce
In addition, I have also described in the past how unique identifiers may be leveraged to aggregate reviews by search engines.
Why is this important in the context of reviews in e-commerce?
If a search engine or e-commerce site cannot uniquely identify a product, multiple pages can be created for the same product. This causes those pages to effectively have diluted their “trust rank” and/or link equity in terms of impacting those signals they send to the search engines.
For example, you can see below, in the case of the marketplace eBay, that there are many cases where the same product is listed many times, and hence the reviews are not aggregated on one unique URL:
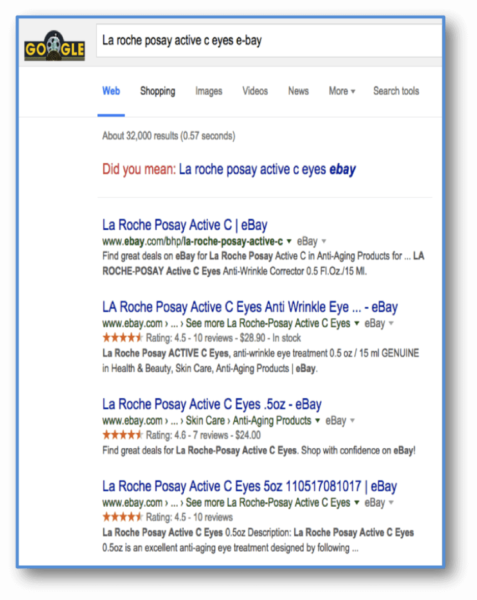
Search for results “La Roche Posay Active C eyes ebay”
This means that it is critical for merchants to be able to uniquely disambiguate their products internally, if they want to send strong signals in order to rank in organic SERPs for a specific URL.
Ensuring your product listings are correctly and uniquely identified provides this benefit, as it will aggregate the reviews for that product onto the same page/product listing, thereby strengthening the “trust rank” of that page. It ought to have a corresponding effect in terms of avoiding link dilution for that page.
Until recently, this was also an issue on Amazon, but one that appears to have recently changed. Compare a recent product search on Amazon for the same product search a few weeks ago:
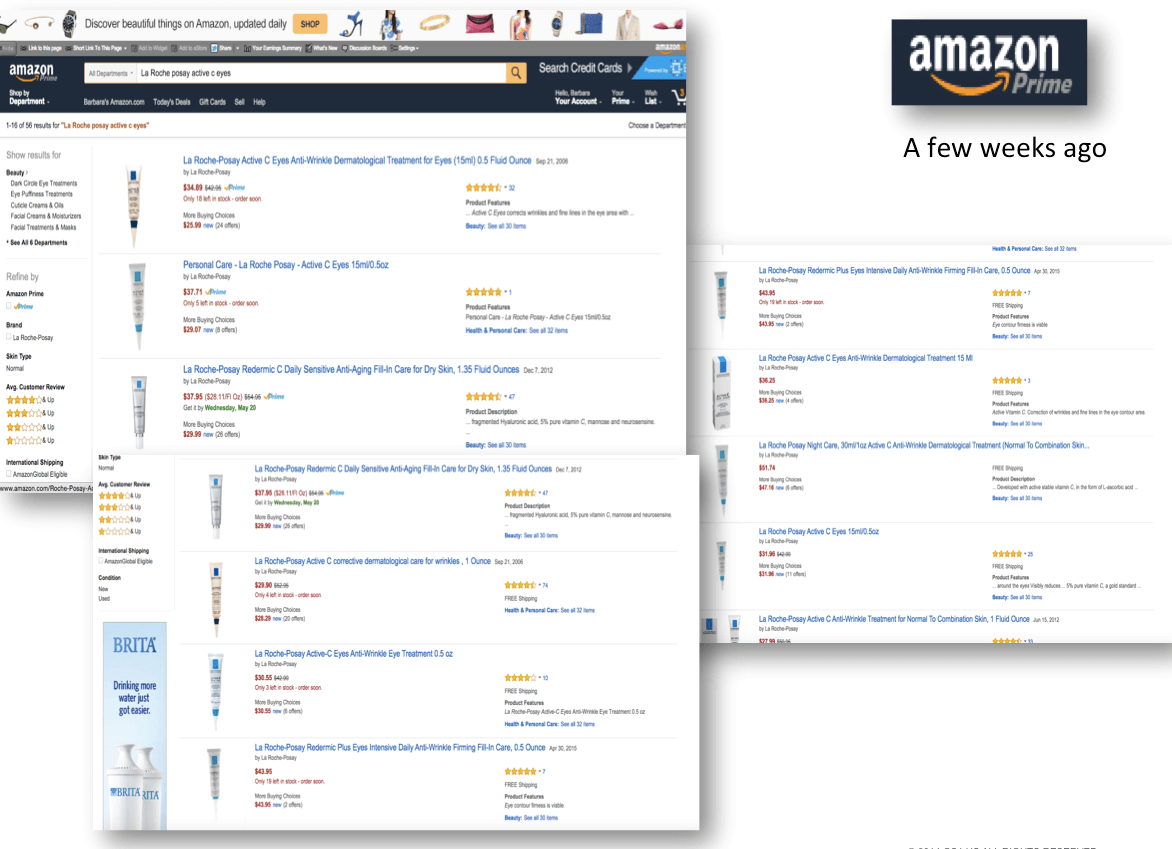
In this product search from several weeks ago, you can see many separate listings of the same product. [click to enlarge]
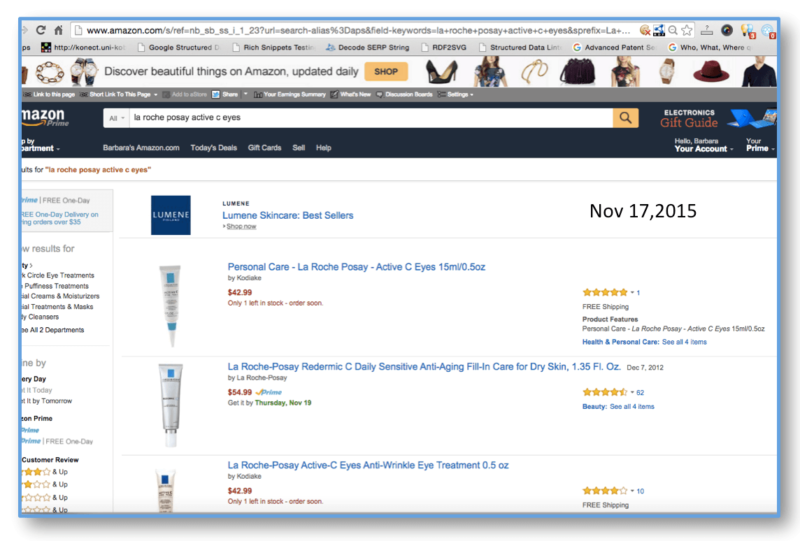
In a more recent search for the same product, only one listing appears. From that page, you can select other sellers to purchase from.
Amazon very recently altered this (a couple of weeks ago), and now only displays the one (correct) product at the top of their search results; however, this also appears to give a strong and exclusive bias to the brand owner of the product.
This is unfortunate as I now only seem to get one price (from the brand itself), and it is clearly not the best price. For me, it degrades the user experience, as I don’t seem to be able to get the best price or many options from other sellers (which is my understanding of the definition of a marketplace).
As local business are all entities and have associated products or services, the impact of trust clearly has an equivalent effect and plays a strong role here. An example is depicted below for a search for a specific product.
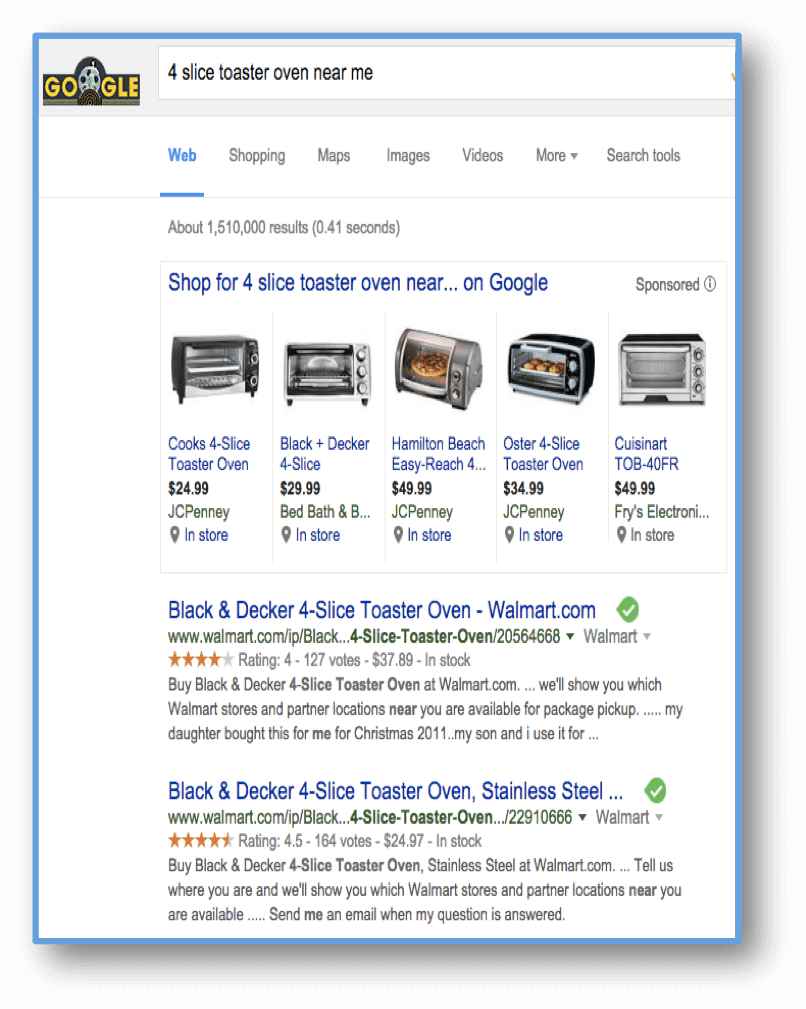
Search for “4 slice toaster oven near me”
It is also very well known that results from trusted review sites often dominate organic SERPs in local search today, with Yelp as a well-known example. This means this applies to professional services and all other kinds of local businesses, forming the basis for a large part of the user’s “trust” in that business entity and/or the products or services they offer.
Critic Reviews And Trust
Looking at this in another vein, Google recently started advising users to promote their content using Critic Reviews, and they suggest adding review markup to any of the following pages:
“The page can be any of the following:
- The website’s home page
- A page linked from the home page that provides a list of available reviews
- A page that displays an individual review.“
They provide an example for promoting Critic Reviews for the movie “Gravity” and specify that the preferred format is JSON-LD (although they do state that they accept microdata and RDFA as alternative syntaxes). For examples of the microdata format, they recommend looking at schema.org/review.
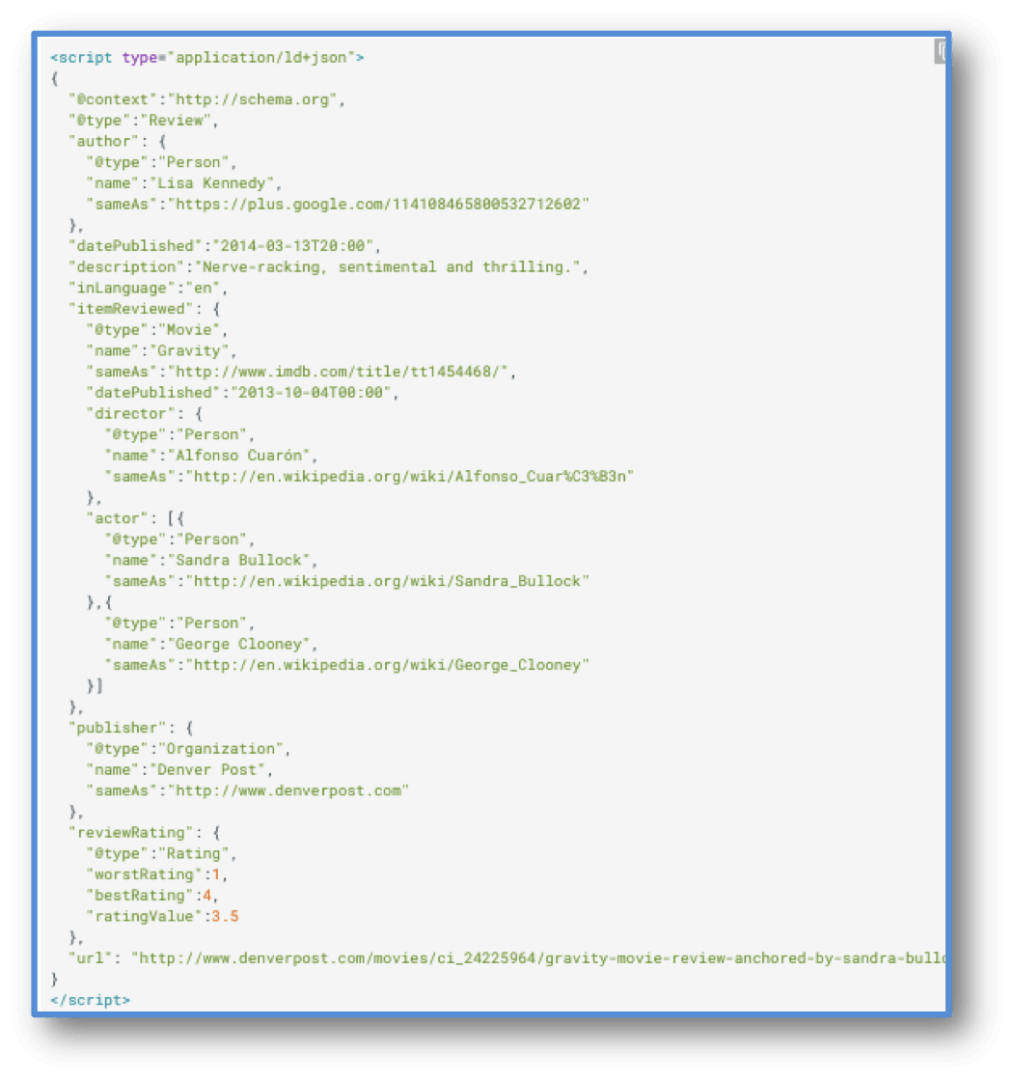
Critic reviews – Sample markup in json-ld for the movie Gravity
Google in fact put out a terrific video on the topic of Critic Reviews. A snapshot below illustrates how the schema.org markup added for these reviews appears on your mobile device.
As Google clearly states here, these snippets help users make decisions and also introduces them to new, authoritative sources (whom they now presumably trust).
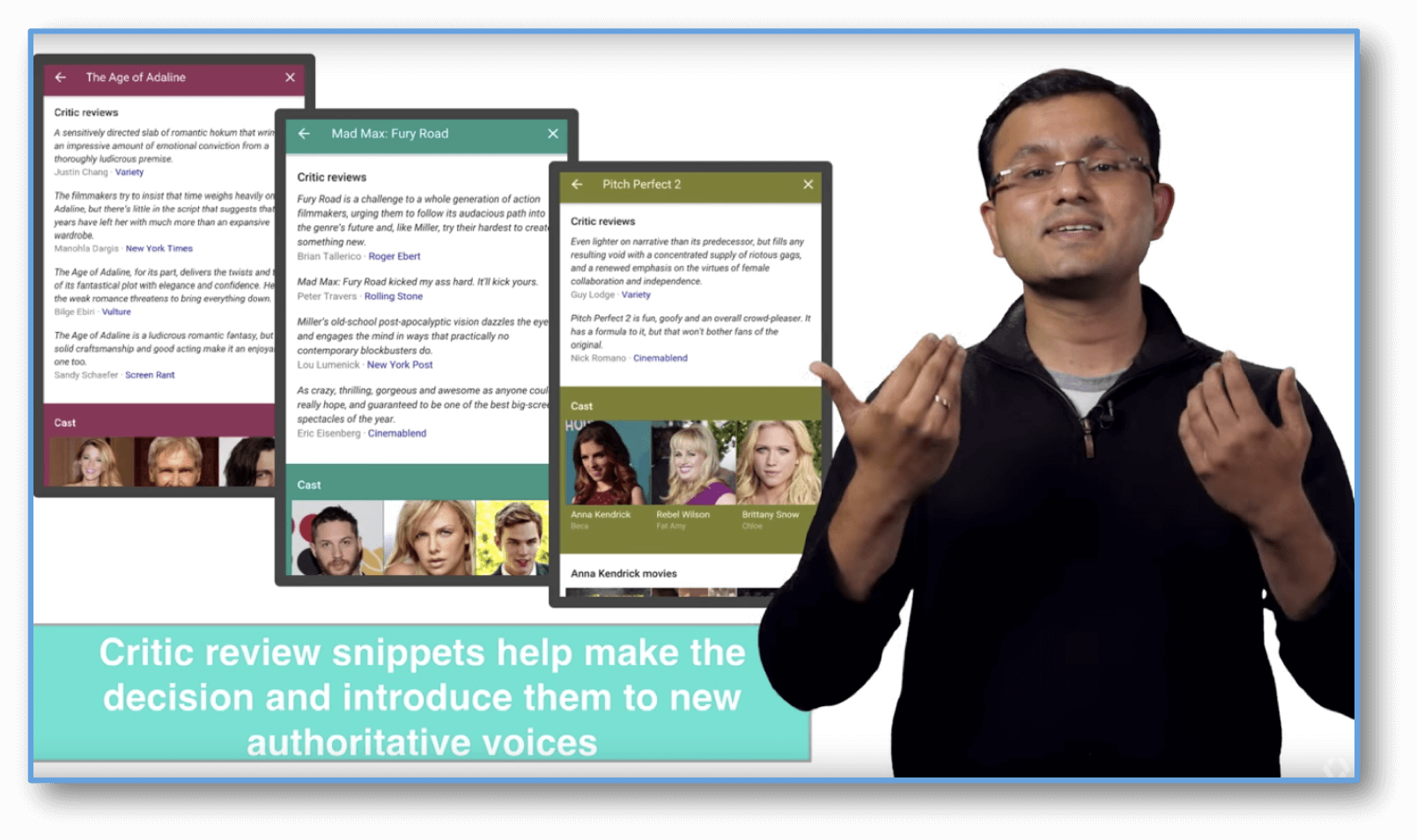
Crtitial Review Snippets on mobile
The standard set of attributes for Critic Reviews is well defined on the post, and there are also additional requirements for four specific Critic review types: movies, books, music albums and cars.
Promote Your Content With Structured Data
As an SEO, you should work to make your code “machine-friendly” and add relevant structured data to your pages using schema.org where applicable. As Google states very clearly here, doing so will give you a better chance of achieving enhanced displays (rich snippets) in search results, as well as a presence in the knowledge graph.
If you can, go one step further than specified in the blog by adding identifiers where possible. Focus primarily on Freebase and Wikidata IDs. I illustrated how to find a freebase ID in a previous article by locating the “MID” (Machine Identifier), and I also discussed how to facilitate the search engines disambiguating your content using the “sameAs” predicate in schema.org.
I would also recommend obtaining the wikidata identifier (or “QID”), which you can find quite easily on Wikipedia by going to the URL of the entity and then clicking “wikidata item” in the left-hand navigation.

I would like to end this article with a screenshot from the video that I could not resist, as it makes a very clear statement. Structured Data allows Google to answer some really hard questions, and Google clearly loves the ability to do so. This means if you want to make Google happy, be sure to add structured data to your web pages.

Structured Data Lets Google answer some really hard questions.
Takeaways
- Mark up all your pages with relevant schema.org markup; if reviews apply, make doubly sure to mark them up, since they add a trust indicator.
- Add identifiers wherever possible (MIDs and QIDs).
- If you are running an e-commerce-type marketplace and are interested in “landing pages,” make sure you uniquely identify your products to ensure that your review volumes are maximized and that you do not lose link equity for those pages.
- If you are a brand site, make sure to add reviews to your product page, along with your unique identifier, to ensure your appropriate recognition as the “official website,” typically in position 1 in organic SERPs (Other factors may alter this, of course).
- If you are promoting some form of media that supports critical reviews (video, movies or music, or a product like cars), be sure to add markup to those pages.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author