A guide to web crawlers: What you need to know
Your website is being crawled right now. Find out which bots are helping your SEO, which ones are hurting it, and how to take control.
Understanding the difference between search bots and scrapers is crucial for SEO.
Website crawlers fall into two categories:
- First-party bots, which you use to audit and optimize your own site.
- Third-party bots, which crawl your site externally – sometimes to index your content (like Googlebot) and other times to extract data (like competitor scrapers).
This guide breaks down first-party crawlers that can improve your site’s technical SEO and third-party bots, exploring their impact and how to manage them effectively.
First-party crawlers: Mining insights from your own website
Crawlers can help you identify ways to improve your technical SEO.
Enhancing your site’s technical foundation, architectural depth, and crawl efficiency is a long-term strategy for increasing search traffic.
Occasionally, you may uncover major issues – such as a robots.txt file blocking all search bots on a staging site that was left active after launch.
Fixing such problems can lead to immediate improvements in search visibility.
Now, let’s explore some crawl-based technologies you can use.
Googlebot via Search Console
You don’t work in a Google data center, so you can’t launch Googlebot to crawl your own site.
However, by verifying your site with Google Search Console (GSC), you can access Googlebot’s data and insights. (Follow Google’s guidance to set yourself up on the platform.)
GSC is free to use and provides valuable information – especially about page indexing.
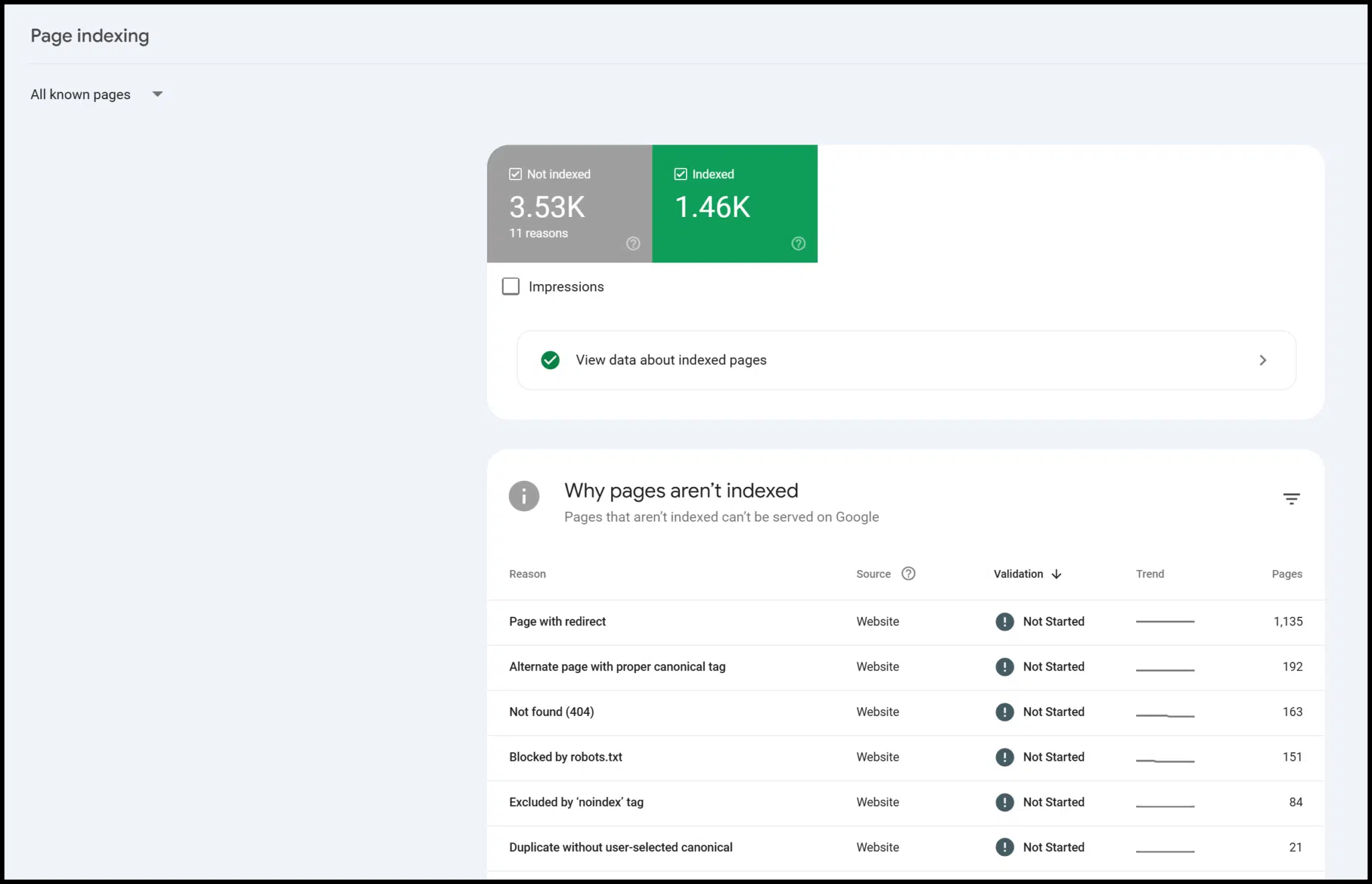
There’s also data on mobile-friendliness, structured data, and Core Web Vitals:
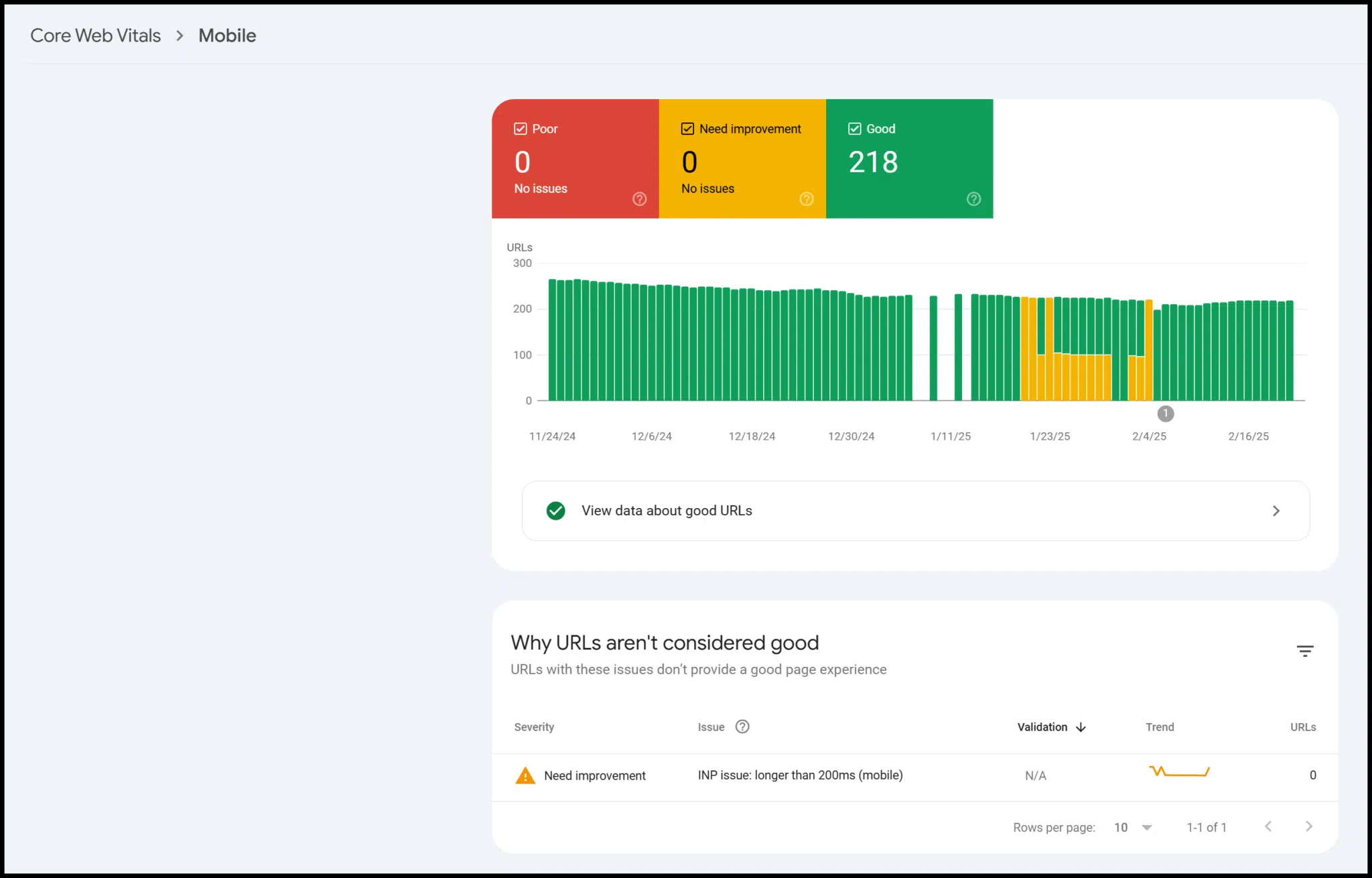
Technically, this is third-party data from Google, but only verified users can access it for their site.
In practice, it functions much like the data from a crawl you run yourself.
Screaming Frog SEO Spider
Screaming Frog is a desktop application that runs locally on your machine to generate crawl data for your website.
They also offer a log file analyzer, which is useful if you have access to server log files. For now, we’ll focus on Screaming Frog’s SEO Spider.
At $259 per year, it’s highly cost-effective compared to other tools that charge this much per month.
However, because it runs locally, crawling stops if you turn off your computer – it doesn’t operate in the cloud.
Still, the data it provides is fast, accurate, and ideal for those who want to dive deeper into technical SEO.
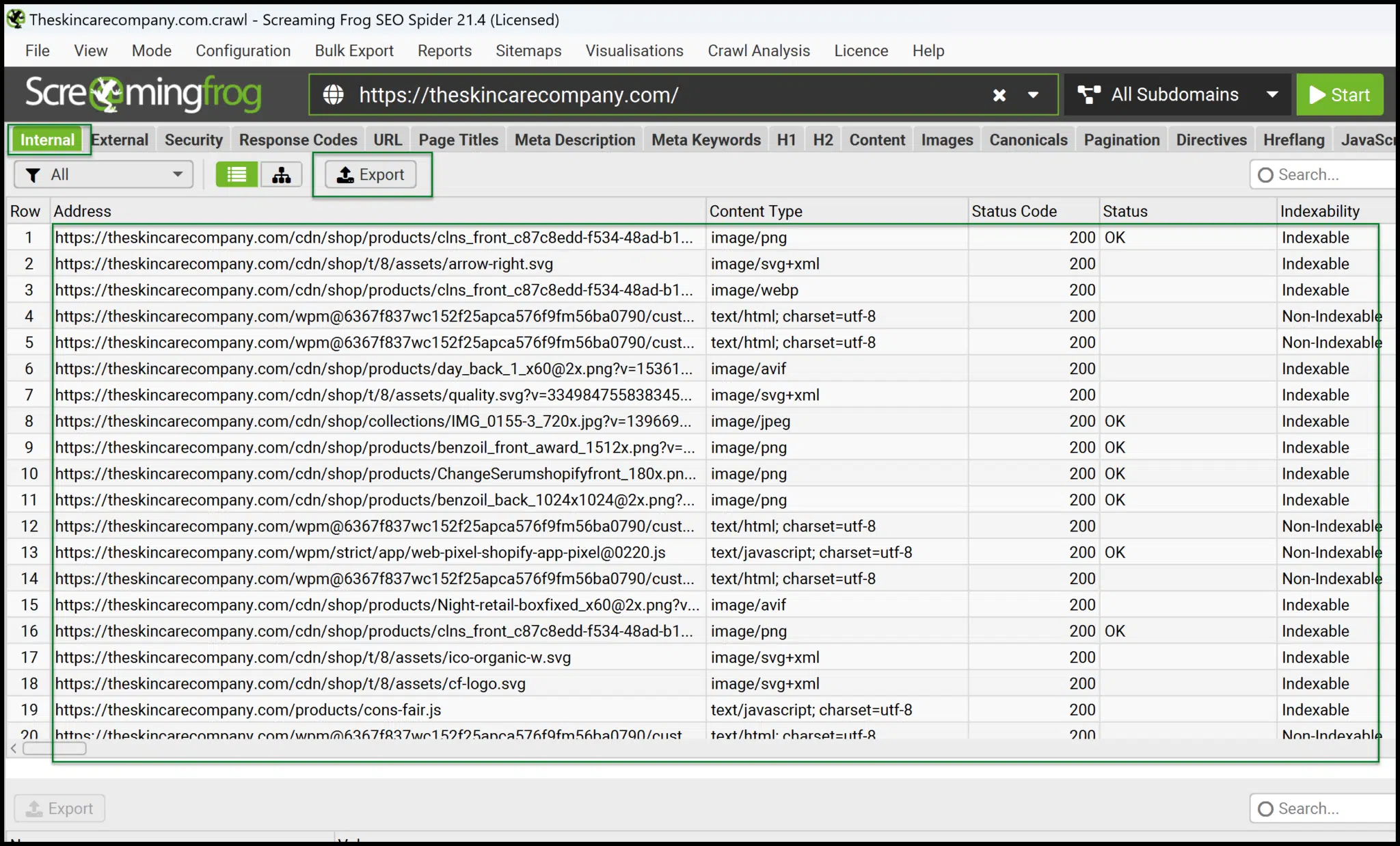
From the main interface, you can quickly launch your own crawls.
Once completed, export Internal > All data to an Excel-readable format and get comfortable handling and pivoting the data for deeper insights.
Screaming Frog also offers many other useful export options.
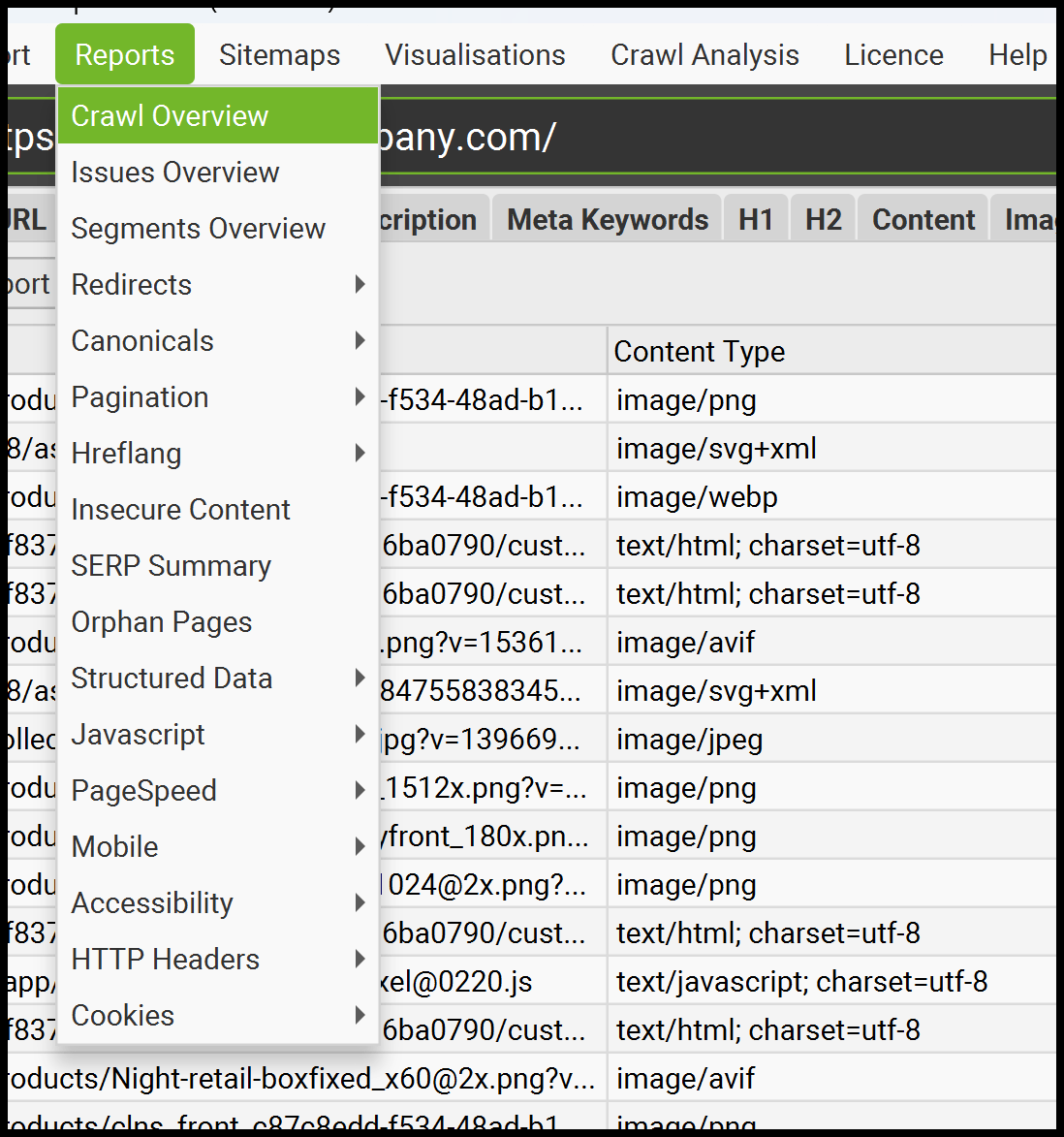
It provides reports and exports for internal linking, redirects (including redirect chains), insecure content (mixed content), and more.
The drawback is it requires more hands-on management, and you’ll need to be comfortable working with data in Excel or Google Sheets to maximize its value.
Dig deeper: 4 of the best technical SEO tools
Ahrefs Site Audit
Ahrefs is a comprehensive cloud-based platform that includes a technical SEO crawler within its Site Audit module.
To use it, set up a project, configure the crawl parameters, and launch the crawl to generate technical SEO insights.
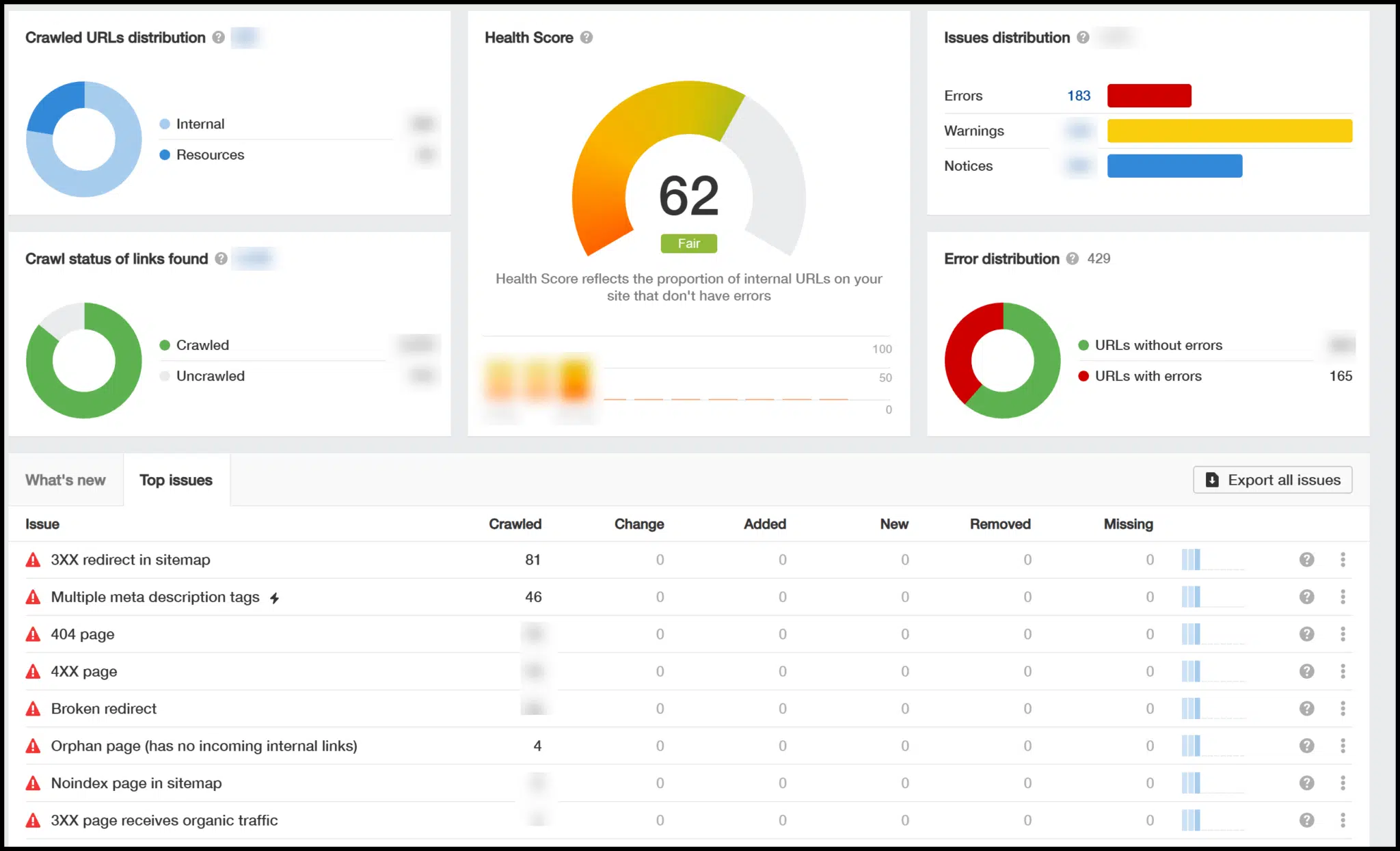
Once the crawl is complete, you’ll see an overview that includes a technical SEO health rating (0-100) and highlights key issues.
You can click on these issues for more details, and a helpful button appears as you dive deeper, explaining why certain fixes are necessary.
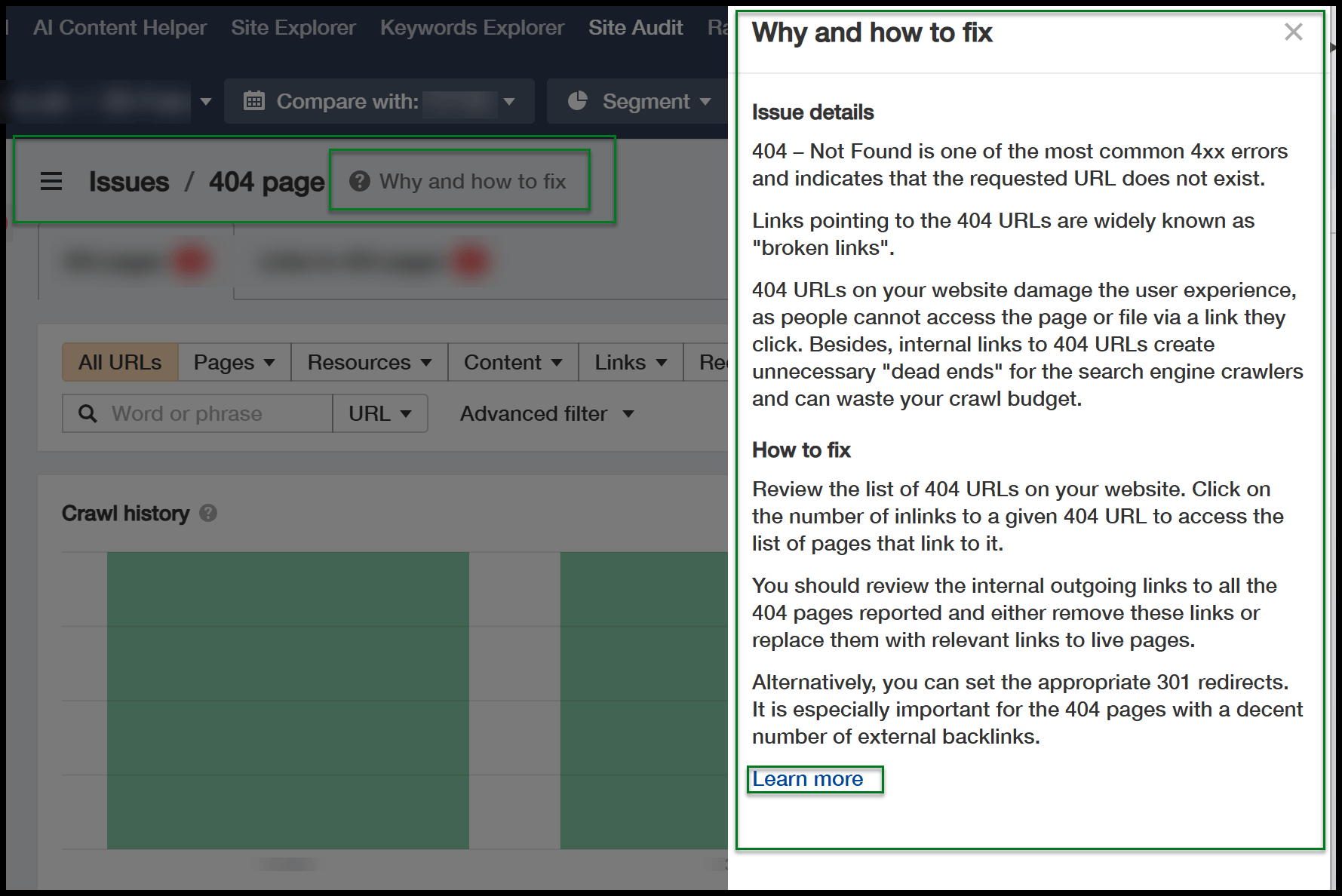
Since Ahrefs runs in the cloud, your machine’s status doesn’t affect the crawl. It continues even if your PC or Mac is turned off.
Compared to Screaming Frog, Ahrefs provides more guidance, making it easier to turn crawl data into actionable SEO insights.
However, it’s less cost-effective. If you don’t need its additional features, like backlink data and keyword research, it may not be worth the expense.
Semrush Site Audit
Next is Semrush, another powerful cloud-based platform with a built-in technical SEO crawler.
Like Ahrefs, it also provides backlink analysis and keyword research tools.
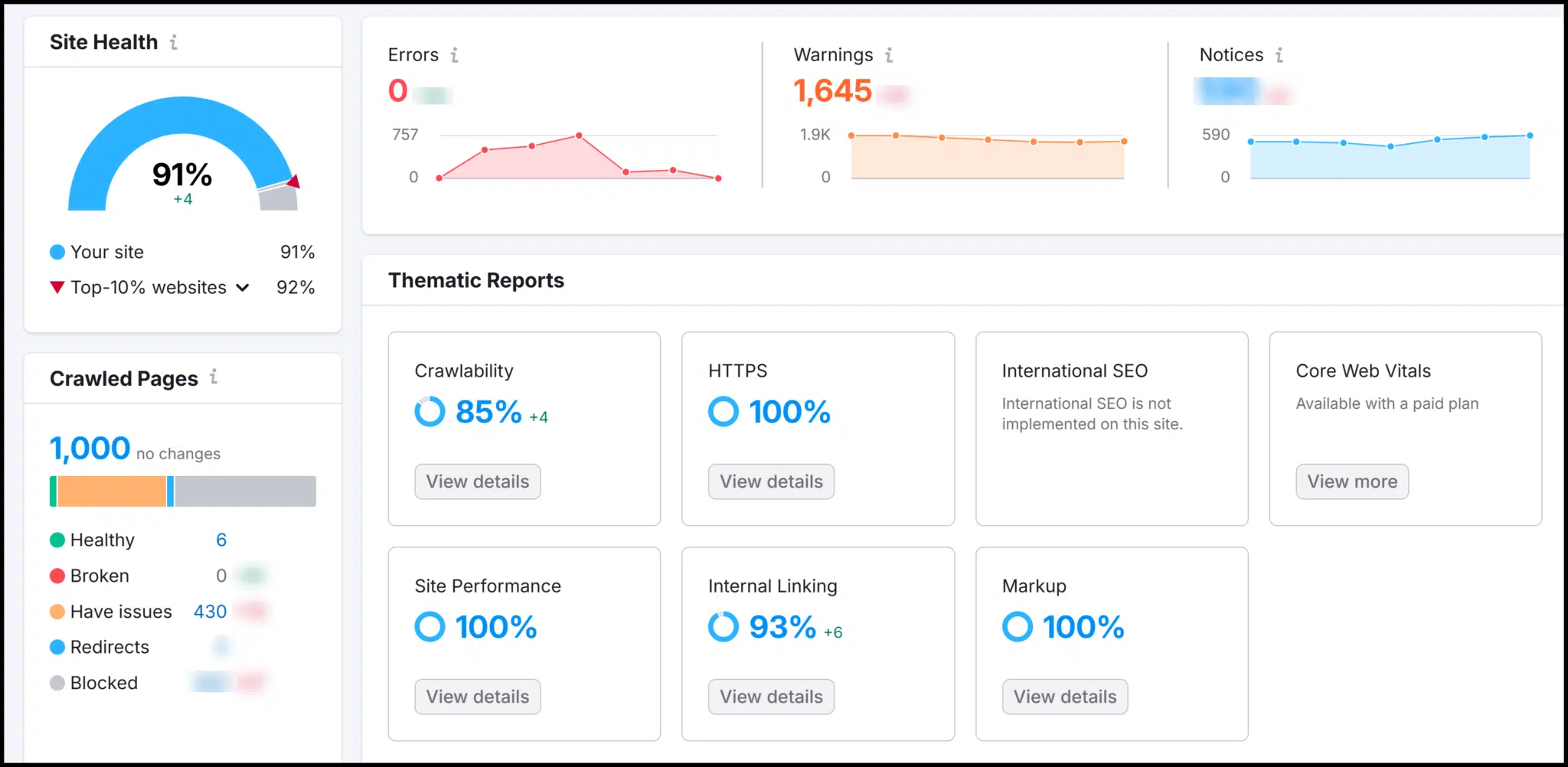
Semrush offers a technical SEO health rating, which improves as you fix site issues. Its crawl overview highlights errors and warnings.
As you explore, you’ll find explanations of why fixes are needed and how to implement them.
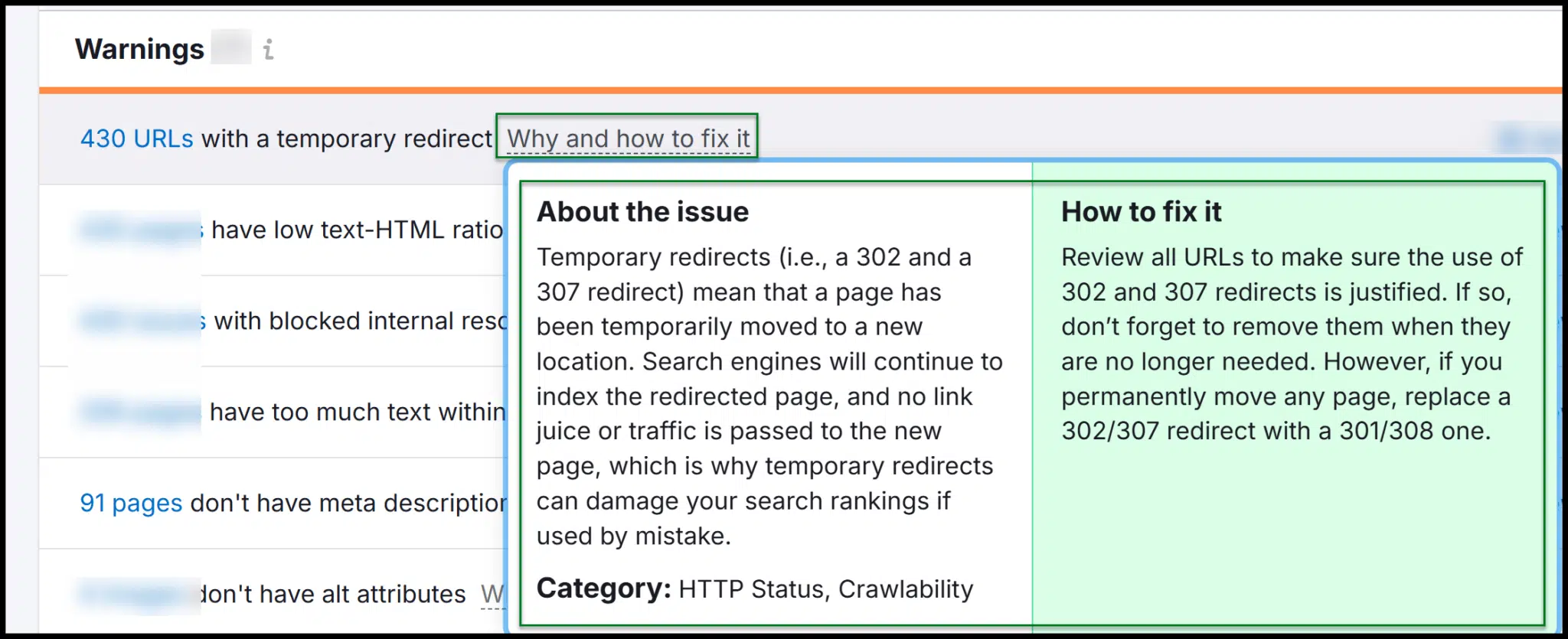
Both Semrush and Ahrefs have robust site audit tools, making it easy to launch crawls, analyze data, and provide recommendations to developers.
While both platforms are pricier than Screaming Frog, they excel at turning crawl data into actionable insights.
Semrush is slightly more cost-effective than Ahrefs, making it a solid choice for those new to technical SEO.
Third-party crawlers: Bots that might visit your website
Earlier, we discussed how third parties might crawl your website for various reasons.
But what are these external crawlers, and how can you identify them?
Googlebot
As mentioned, you can use Google Search Console to access some of Googlebot’s crawl data for your site.
Without Googlebot crawling your site, there would be no data to analyze.
(You can learn more about Google’s common crawl bots in this Search Central documentation.)
Google’s most common crawlers are:
- Googlebot Smartphone.
- Googlebot Desktop.
Each uses separate rendering engines for mobile and desktop, but both contain “Googlebot/2.1” in their user-agent string.
If you analyze your server logs, you can isolate Googlebot traffic to see which areas of your site it crawls most frequently.
This can help identify technical SEO issues, such as pages that Google isn’t crawling as expected.
To analyze log files, you can create spreadsheets to process and pivot the data from raw .txt or .csv files. If that seems complex, Screaming Frog’s Log File Analyzer is a useful tool.
In most cases, you shouldn’t block Googlebot, as this can negatively affect SEO.
However, if Googlebot gets stuck in highly dynamic site architecture, you may need to block specific URLs via robots.txt. Use this carefully – overuse can harm your rankings.
Fake Googlebot traffic
Not all traffic claiming to be Googlebot is legitimate.
Many crawlers and scrapers allow users to spoof user-agent strings, meaning they can disguise themselves as Googlebot to bypass crawl restrictions.
For example, Screaming Frog can be configured to impersonate Googlebot.
However, many websites – especially those hosted on large cloud networks like AWS – can differentiate between real and fake Googlebot traffic.
They do this by checking if the request comes from Google’s official IP ranges.
If a request claims to be Googlebot but originates outside of those ranges, it’s likely fake.
Other search engines
In addition to Googlebot, other search engines may crawl your site. For example:
- Bingbot (Microsoft Bing).
- DuckDuckBot (DuckDuckGo).
- YandexBot (Yandex, a Russian search engine, though not well-documented).
- Baiduspider (Baidu, a popular search engine in China).
In your robots.txt file, you can create wildcard rules to disallow all search bots or specify rules for particular crawlers and directories.
However, keep in mind that robots.txt entries are directives, not commands – meaning they can be ignored.
Unlike redirects, which prevent a server from serving a resource, robots.txt is merely a strong signal requesting bots not to crawl certain areas.
Some crawlers may disregard these directives entirely.
Screaming Frog’s Crawl Bot
Screaming Frog typically identifies itself with a user agent like Screaming Frog SEO Spider/21.4.
The “Screaming Frog SEO Spider” text is always included, followed by the version number.
However, Screaming Frog allows users to customize the user-agent string, meaning crawls can appear to be from Googlebot, Chrome, or another user-agent.
This makes it difficult to block Screaming Frog crawls.
While you can block user agents containing “Screaming Frog SEO Spider,” an operator can simply change the string.
If you suspect unauthorized crawling, you may need to identify and block the IP range instead.
This requires server-side intervention from your web developer, as robots.txt cannot block IPs – especially since Screaming Frog can be configured to ignore robots.txt directives.
Be cautious, though. It might be your own SEO team conducting a crawl to check for technical SEO issues.
Before blocking Screaming Frog, try to determine the source of the traffic, as it could be an internal employee gathering data.
Ahrefs Bot
Ahrefs has a crawl bot and a site audit bot for crawling.
- When Ahrefs crawls the web for its own index, you’ll see traffic from
AhrefsBot/7.0. - When an Ahrefs user runs a site audit, traffic will come from
AhrefsSiteAudit/6.1.
Both bots respect robots.txt disallow rules, per Ahrefs’ documentation.
If you don’t want your site to be crawled, you can block Ahrefs using robots.txt.
Alternatively, your web developer can deny requests from user agents containing “AhrefsBot” or “AhrefsSiteAudit“.
Semrush Bot
Like Ahrefs, Semrush operates multiple crawlers with different user-agent strings.
Be sure to review all available information to identify them properly.
The two most common user-agent strings you’ll encounter are:
- SemrushBot: Semrush’s general web crawler, used to improve its index.
- SiteAuditBot: Used when a Semrush user initiates a site audit.
Rogerbot, Dotbot, and other crawlers
Moz, another widely used cloud-based SEO platform, deploys Rogerbot to crawl websites for technical insights.
Moz also operates Dotbot, a general web crawler. Both can be blocked via your robots.txt file if needed.
Another crawler you may encounter is MJ12Bot, used by the Majestic SEO platform. Typically, it’s nothing to worry about.
Non-SEO crawl bots
Not all crawlers are SEO-related. Many social platforms operate their own bots.
Meta (Facebook’s parent company) runs multiple crawlers, while Twitter previously used Twitterbot – and it’s likely that X now deploys a similar, though less-documented, system.
Crawlers continuously scan the web for data. Some can benefit your site, while others should be monitored through server logs.
Understanding search bots, SEO crawlers and scrapers for technical SEO
Managing both first-party and third-party crawlers is essential for maintaining your website’s technical SEO.
Key takeaways
- First-party crawlers (e.g., Screaming Frog, Ahrefs, Semrush) help audit and optimize your own site.
- Googlebot insights via Search Console provide crucial data on indexation and performance.
- Third-party crawlers (e.g., Bingbot, AhrefsBot, SemrushBot) crawl your site for search indexing or competitive analysis.
- Managing bots via robots.txt and server logs can help control unwanted crawlers and improve crawl efficiency in specific cases.
- Data handling skills are crucial for extracting meaningful insights from crawl reports and log files.
By balancing proactive auditing with strategic bot management, you can ensure your site remains well-optimized and efficiently crawled.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
About the author