Advanced SEO Analysis – Part 1: SEO Research & Wisdom Of The Crowd
A couple of years ago, I was invited to speak at the SMX Advanced conference in Seattle on the topic of SEO and competitive intelligence. It is an area of SEO I’m passionate about, not only because it is one of the most difficult things in SEO to scale and do right, but also because […]
A couple of years ago, I was invited to speak at the SMX Advanced conference in Seattle on the topic of SEO and competitive intelligence. It is an area of SEO I’m passionate about, not only because it is one of the most difficult things in SEO to scale and do right, but also because it is one of the foundations of a good SEO program.
Before I dive into outlining one of the advanced approaches to SEO analysis that I shared at the conference, it’s important to understand the genesis of the approach.
Before I was building the machine-learning algorithms behind our Enterprise SEO platform, I spent a number of years building and running an Enterprise SEO consulting firm and agency. We were a small team (less than 15 people at the time), but we were growing quickly.
One of the biggest challenges we faced was being able to scale the task of conducting in-depth research into a client’s situation as quickly and as consistently as possible — irrespective of the team member working on it. From learning about the client’s business lines and the terminology used in their industry to understanding the key industry players/competitors/influencers in the space, research formed the basis of all our planning and tactics for the client.
When running an agency (in-house or external), you have to figure out processes that are repeatable and scalable. This is the hallmark of teams that excel at delivering stellar results versus those that fail despite a tremendous amount of effort. Since research forms the bedrock of any good SEO team, getting good at doing it right was essential to our growth and success.
Research (and analysis) is a complex and time-consuming task, whether it’s keyword research, influencer research or even competitive research. The problem with any kind of research is that the quality of research “depends.” It depends on:
- The quality of the data sources used
- The researcher (or the “human element”)
The depth and breadth of coverage offered by the data sources (or lack thereof) has a significant impact on the quality of the research. Too many data sources can lead to unnecessary noise (as anyone who has used the keyword planner tool can attest to), while too little data depth means that important information may be missed in the consideration set.
When it comes to the “human element,” the quality of research is highly dependent on the researcher’s experience, education, knowledge base, vocabulary, understanding of the industry, level of involvement, attitude and a variety of other hard and soft factors.
While there are plenty of good sources for data nowadays for keyword research, influencer research and so on, there are still not many good systems or methods to help reduce the impact of the “human element” in research.
This is where we developed a methodology that we termed “wisdom of the crowds.” The name was no accident — the theory we leveraged was influenced by methods used in the stock markets for many decades and by a book published in 2005 by James Surowiecki, The Wisdom of Crowds: Why the Many Are Smarter Than the Few and How Collective Wisdom Shapes Business, Economies, Societies and Nations.
If you’ve heard about consensus estimates in the stock markets, or Delphi methods of forecasting, you’re already familiar with the basic concept. If you haven’t heard of these methods, don’t worry — we’ll cover in just a second.
Wikipedia defines “wisdom of the crowds” as:
…the process of taking into account the collective opinion of a group of individuals rather than a single expert to answer a question. A large group’s aggregated answers to questions involving quantity estimation, general world knowledge, and spatial reasoning has generally been found to be as good as, and often better than, the answer given by any of the individuals within the group. An intuitive and often-cited explanation for this phenomenon is that there is idiosyncratic noise associated with each individual judgment, and taking the average over a large number of responses will go some way toward canceling the effect of this noise.
Essentially, when the wisdom of the crowds is applied to SEO, it leverages data on multiple competitors in order to surface the most important data points. It allows you to focus in a way that eliminates noise that occurs due to any specific competitor’s data or the researcher’s personal background.
This is best understood with an example. Take the instance of keyword research. Typically, keyword research would involve the following tasks:
- Identify a few root keywords that relate to the client’s industry and products/services offered.
- Navigate to Google keyword planner.
- Type in the keyword related to the client.
- Download the list of keywords returned.
- Identify all the slightly longer, more specific versions of the keyword from the list.
- Repeat the process.
- Put all keywords in Excel and follow your own process for cleaning up the list (removing irrelevant keywords, filtering out based on search volume, etc.).
This process is an incredibly huge waste of time — you could spend tens of hours on it and still completely miss the most effective keywords. Why? First, there is a tremendous amount of “noise” or irrelevant data returned by the data source. Second, there is no validation of the relevance of the keyword(s) to the client’s industry — the researcher’s knowledge and experience in the industry play a huge part in what is kept and what is thrown out in the analysis.
Consider this alternative approach, which leverages wisdom of the crowd:
- Identify the page on your (or your client’s) site that you wish to research for keywords.
- Identify at least 3 (the more the better) pages from various competitor sites that rank for the core product or service name that the page is relevant for. For example, if you have a page about “New York hotels,” look for the top ranking pages from different competitor sites for that keyword.
- Take your pick of your favorite keyword intelligence tool — SEMrush, KeywordSpy, SpyFu or a more targeted, industry-specific index such as what we offer at seoClarity (shameless plug!). Remember that a data source that offers significant breadth and depth is critical to a good analysis.
- Download the keywords that each of the competitor pages rank for.
- Compile the downloaded data for all competitors into a single Excel workbook and create a pivot table to quickly view how many competitors rank for the same keyword.
- Pick the keywords where two or more competitors rank for a keyword but your page doesn’t.
That’s it! By ensuring that you look at the keywords that two or more competitors are ranking for and you aren’t, you eliminate a tremendous amount of the noise associated with traditional keyword research.
Here is a Venn diagram that will help visualize the process. The keywords that are part of the overlapping sections are the ones that are common among the two competitor pages and are strong candidates for your own keyword set to focus on.
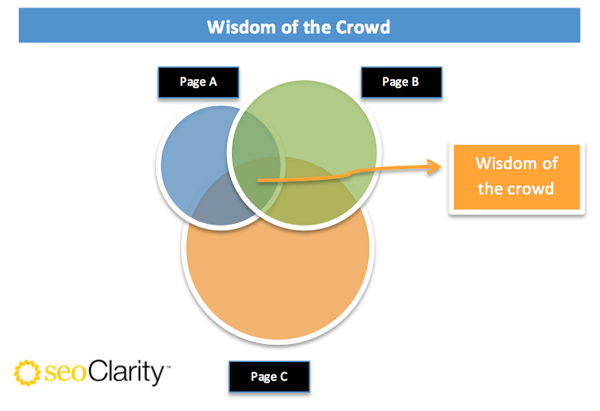
With this research methodology you can be confident that:
- You’re picking keywords that Google finds relevant to pages directly competing with you.
- The keywords highlighted have a very high probability of being relevant to your page, too (as long as your page and your competitor pages are targeting the same audience with relatively similar services).
- You have eliminated unnecessary noise due to company-specific (brand or product name) keywords.
One of the other things I love about this methodology is that it can be equally well employed for nearly any kind of research. Looking for influencers in the industry? Repeat the same process, but simply change the data source to MajesticSEO or another source. Looking for social outreach? Repeat with Twitter follower information. Looking for content ideas? Leverage what topics multiple sites are publishing in your industry. The list is endless!
Try it out!
Some Cautionary Notes
- This methodology is not for all situations — if you have a very unique product and competitors that are not very clearly defined (or competitors that don’t have well-targeted pages), this will not work.
- If you don’t have a good competitive landscape (meaning you are the dominant player and everyone else is sub-par), this will not yield quality results.
- If your data source is not reliable, the insights you gain will be limited.
- This methodology won’t necessarily find keywords that no one has thought of optimizing for, but it will buy you time and get you started with low hanging fruit while you research the hard-to-find gems.
- Following only this methodology is a recipe for M.A.D — Mutually Assured Destruction.
Stay tuned for Part 2 as we continue with Advanced SEO Analysis.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
About the author