DIY SEO: How To Check On-Page Ranking Factors Using Google Docs
My kids and I really enjoy watching the MAKE Magazine video podcasts together. It’s one of those rare and happy things that a ten-year-old girl, an eight-year-old boy, and an adult can watch together and find interesting. Inspired by these podcasts, I thought it would be a good idea to create a do-it-yourself SEO project. […]
My kids and I really enjoy watching the MAKE Magazine video podcasts together. It’s one of those rare and happy things that a ten-year-old girl, an eight-year-old boy, and an adult can watch together and find interesting.
Inspired by these podcasts, I thought it would be a good idea to create a do-it-yourself SEO project. So today, we’ll make a Google Spreadsheet that checks a web page for various on-page factors that can affect SEO.
Getting Started
What you need:
- A Google Account for logging into Google Spreadsheets
- A URL that you want to check.
In this article, I’ll be checking https://searchengineland.com/. The spreadsheet that we will create in this article is here.
Once you are signed in to Google Spreadsheets, you will be able to make your own copy to work with by opening the spreadsheet and selecting File -> Make A Copy…
If you would rather start with a blank spreadsheet and fill it in as you go through this article, select File -> New -> Spreadsheet.
How It Works
Our on-page checking spreadsheet uses the importXML() function in Google Spreadsheets. This very useful function takes two arguments, a URL to a document to be parsed and an Xpath query that tells it which information to import into the spreadsheet.
More information about the importXML() function can be found in Google’s documentation.
Xpath is a query language that is used to match elements (better known to those of us who are more familiar with HTML as “tags,” as in “title tag” or “H1 tag.”) and the attributes of these elements (for example, “alt“ or “href“) in an XML document and to tell it what information to extract.
For example, the Xpath query “//a[@href=”index.htm”]/text()” will return the anchor text for any link pointing to the file index.htm. Don’t worry if this doesn’t make any sense yet. As you work with a few examples, it will become clearer.
A good resource for Xpath queries can be found here.
Testing The Basics
Let’s get started. First we will do a simple query to extract the title from an HTML document. To do this, follow these steps:
- Enter the URL you are checking in the cell A1.
- Put “Title” in cell A2.
- In cell B2 enter this exact text: =importXML(A1, “(//title|//TITLE)”)

The parts that are “//title” and “//TITLE” will match all elements (tags) that are either “title” or “TITLE.” (Xpath queries are case-sensitive by default, so we are matching all uppercase or all lowercase.) The parentheses and vertical bar “|” tell Xpath to return elements that match either of the two.
Once you hit return, the text should change to the title of the page you are checking. You may see “Loading…” for a few seconds while Google retrieves and parses the page.

If something went wrong, check the following things:
- Does the page at your URL have a title tag?
- Does the URL redirect anywhere?
- Is the title tag written as “Title” in the HTML? Remember that Xpath queries are case sensitive, so the query above will only match “title” and “TITLE.”
- Did you type the URL correctly?
It’s also possible that the HTML in the page you are checking is too badly formed to be correctly parsed by the importXML() function. In this case, either pick a new URL or validate and tidy the page’s HMTL and try again.
Checking Header Tags
If everything is working up to this point, we are now ready to run more queries against our pages.
Let’s check for the header tags H1 and H2.
Follow these steps:
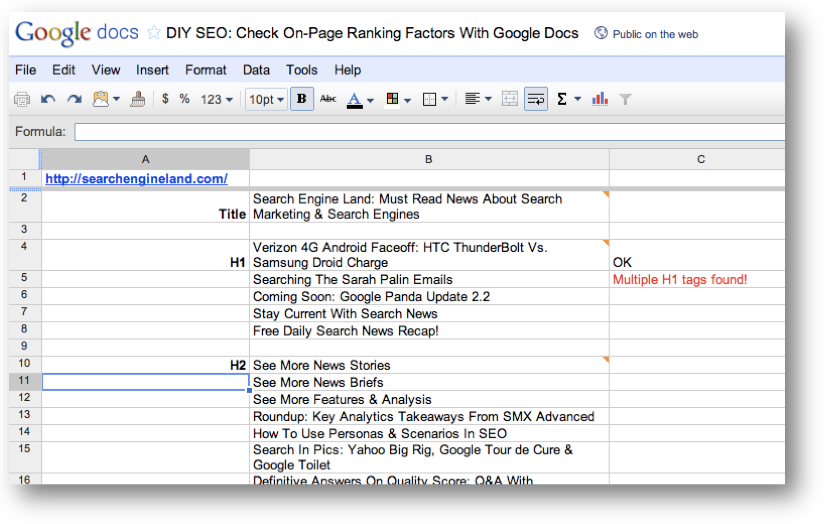
- Put “H1” in cell A4
- In cell B4 enter this text: =importXML(A1, “(//h1|//H1)”)
- Put “H2” in cell A10
- In cell B10 enter this text: =importXML(A1, “//h2|//H2)”)
At this point, you should see the text of the H1 and H2 tags of your page. Notice how a cell is filled out for each matching tag. It’s important to leave enough room for additional cells so that you can see all matching values.
Creating Alerts & Testing The Results
Another useful thing we can do with Google Spreadsheets is write tests that check the output of importXML() and flag any problems or deviations from best practices.
In this webmaster help video, Matt Cutts says that more than one H1 is okay for some pages, but he also recommends not to over do it. So let’s write two alerts, one to make sure there is at least one H1 tag and another one to alert us if there is more than one H1 tag. Follow these steps:
- In cell C4 enter this text: =IF(ISERR(B4),”No H1 tag found!”,”OK”)
- In cell C5 enter this text: =IF(COUNTA(importXML(A1,”(//H1|//h1)”))>1,”Multiple H1 tags found!”,”OK”)
The ISERR() function will check for an error in a cell, including “#N/A” which is the result of an Xpath query that doesn’t match anything.
The COUNTA() function counts the number of elements in an array, which is what is returned by importXML(). This is the most efficient way to get the number of matches for a particular Xpath query.
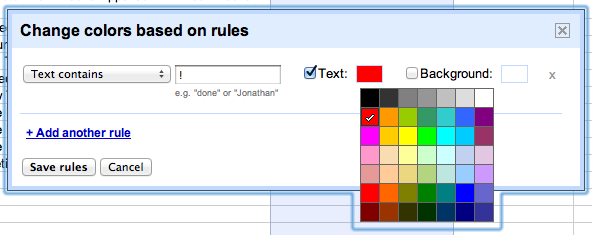
If you want to make the alerts stand out more, use conditional formatting in column C to turn the alerts red if they don’t pass.
To do this, select column C, go to Format > Conditional formatting… and set the text to red when the text contains an exclamation point.
Xpath queries are also useful for extracting the value of attributes within a tag, which means that we can check the usual SEO-related meta tags.
For example, let’s look for the link canonical tag and meta robots tags on the document. Follow these steps:
- Put “Robots meta” in cell A30
- In cell B30 enter this text: =importXML(A1, “//meta[@name=’robots’]/@content”)
- Put “Link canonical” in cell A31
- In cell B31, enter this text: =importXML(A1, “//link[@rel=’canonical’]/@href”)
The “[@foo=”bar”]” syntax that we have added is a way of restricting the matching tags to only elements containing that attribute-value pair. The /@content and /@href in each Xpath query returns the values for those attributes.
Note that attribute and value matching is also case-sensitive. So if any of the elements, attributes, or values being matched contain an upper-case letter then our Xpath query won’t match it. You may need to adjust the Xpath queries to match the style of HTML that your CMS outputs.
You should now see the meta robots directives and link canonical values for the page you are checking. If you see “#N/A” in the cell after hitting return then the page doesn’t have these meta tags, you typed the Xpath query incorrectly, or there are case-sensitivity problems.
Checking Links & Anchor Text
Let’s finish with some queries that count the number of links on the page and lists the anchor text and outbound links.
Because pages usually have many links, let’s do this on a new tab so we will have enough room for the output. Follow these steps:
- Go to Insert > New Sheet to create a new tab for the spreadsheet.
- In cell A1 enter the URL you are checking
- In cell A2 enter the following: =COUNTA(importXML(A1,”//a”)) & ” links”
- In cell A3 enter the following: =importXML(A1,”(//a/text()|//a/img/@alt)”)
- In cell B3 enter the following: =importXML(A1,”//a/@href”)
Remember that the parentheses and vertical bar (or “|”) in the Xpath query for cell A3 matches either one of the Xpath queries separated by a “|”. So in this example, we are returning any anchor text or alt text of an image within that link.
The ampersand (or “&”) in the query for cell A2 combines text into one string.
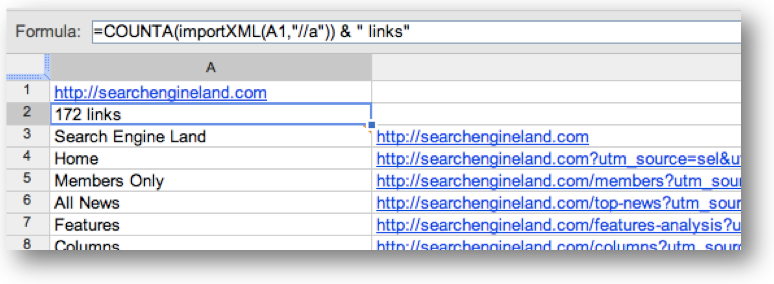
If everything was entered correctly, you should see the number of links on the page in cell A2 with a list of all anchor text and image alt text listed below that. In column B, you should see a list of all the links on the page.
Ideally, the list of anchor text and links will match up. But it is possible that some of the links won’t have any anchor text and will be skipped. If the text and the links don’t match up, then it is very likely that not all links have consistent anchor text.
Extra Credit
If you want to continue exploring the use of Google Spreadsheets to check on page factors, I created another spreadsheet with more examples here.
This spreadsheet contains a few more advanced examples that can check things like:
- The meta description tag
- The Safe browsing diagnostics page for a domain
- Whether or not the page is in Google’s index
- Images and their alt text
- Images that don’t contain alt text
The Xpath queries are in the “Queries” tab, and you can double click on the cells to see the underlying formulas.
Make a copy for yourself and start exploring. Feel free to share any interesting Xpath queries or formulas you come up with in the comments. Happy hacking!
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author