Newspapers Amok! New York Times Spamming Google? LA Times Hijacking Cars.com?
Back in March, Google warned that allowing your internal search results to be listed in Google might be considered spamming. Today, there’s some buzz that one of the top listings for a search for sex on Google turns out to be an internal search results page from the New York Times. In looking at that, […]
Back in March, Google warned that allowing your internal search results to be listed in Google might be considered spamming. Today, there’s some
buzz that one of the top listings for a search for sex on Google turns out to be an internal search results page from the New York Times. In looking at that, I also came across an example of the LA Times "hijacking" the listing of Cars.com for a search on cars, thought the fault for that lies with Google.
Let’s start with the New York Times:
John Andrews wrote
yesterday
that internal search pages from the query.nytimes.com domain were ranking well for various
terms. Threadwatch started
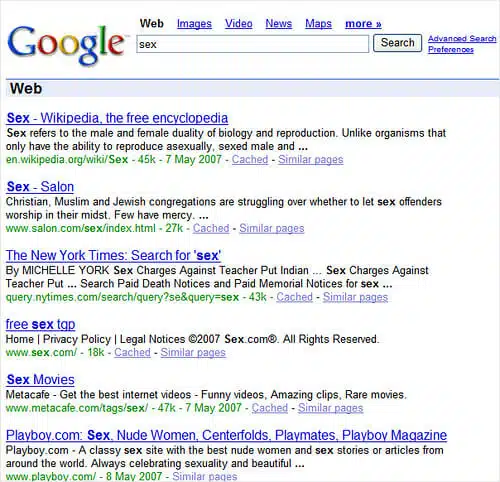
checking around and came up with the money shot today, that the New York Times
grabbed a top spot for "sex" with
this page.
Threadwatch headlined it "the web’s freshest spam." Search Engine Journal
picked up on the spamming charge, which got
exposed to those over at Digg.
So is it spamming? Yep. As my earlier article,
Google Warning Against
Letting Your Search Results Get Indexed, explains, Google’s
guidelines on inclusion of search results content say:
Use robots.txt to prevent crawling of search results pages or other
auto-generated pages that don’t add much value for users coming from search
engines.
This means that the New York Times ought to block any pages within the
query.nytimes.com domain. They don’t, so technically, they’re spamming.
What’s uncertain is whether these query pages have been crawled from before
the guidelines change or not. IE: internal queries from the New York Times may
have long been opened to crawling from before the recent change but only now
becoming visible perhaps due to an algorithm change.
My article points out that many sites are now
technically spamming, because of this little publicized change. Heck, I’ve yet
to block our own search results from being crawled by Google. I just haven’t
gotten around to it. I’m sure I’m not the only one.
John’s article also notes that the New York Times has an entire
Times Topics area that is accessible to
search engines. He describes these as:
The re-published, re-purposed, New York Times Archives. Each “article” is
re-purposed on a clean, CSS-driven text page, clearly dated TODAY and
not-co-clearly labeled as “originally published” back in 1997, 1998, or
whatever all the way back to 1981. Of course cross-referenced, categorized,
sub-categorized, ad-infinitum.
I know Marshall Simmonds who does oversees the SEO work at the New York Times
well, and I’ll throw him a break on this one. "Re-published, re-purposed"
material sounds pretty bad, devious and spam like. Now how about if I say the New York Times is making
categorized lists of its stories available to search engines, in the way that
literally millions of blogs do? Bad then?
For example, here’s John’s republished, repurposed information on
link building
that is clearly dated today, at least according to the most important date that
search engines examine — what’s in the http header information. That
page is John’s category page for posts he’s done on link building. The last post
was from July 9, 2006 — but the http header info reports the page as having a
"fresh" date of May 8, 2007.
John’s doing absolutely nothing wrong. As I said, it’s common for sites to
have category pages for stories they’ve written. It’s GOOD for them to have
these, in most cases. As for the header, it’s also
common that sites don’t provide last modified dates or that they reports
the current date as the document’s authored date. That’s why search engines
typically depend on their own internal comparison processes to determine if a
document has changed or other means to assign actual dates to them. The visible
date shown to human often means little.
Given this context, I find it hard to see how the New York Times is spamming with the
Times Topics pages, any more than I’d say the Topix news search site is spamming with its long-standing
topics pages.
Moreover, if you go back to that sex search, ranked above the NYT is a Salon
category page on sex. And in the
same first page of results, I also get category pages from the
Village Voice
and Metacafe. Spammers? No.
Smart SEO? In some cases, yes, for the forethought in having optimized category
pages.
Should category pages be treated the same as search results pages — IE, be
seen as something that should be blocked? If so, many blogs will be facing
difficulties. In addition, the line between "search results" and "category
results" can be unclear. As I noted when the policy was added to the Google
guidelines:
In contrast, the new policy is a can of worms that’s been opened for
shopping and other sites that have learned to turn product search results into
crawlable content. At the moment, I think we’re in watch-and-see mode as to
how aggressively or selectively Google applies removal. If you’re concerned,
start looking at your robots.txt files now. If you’re a long-term thinker,
understand the writing is clearly on the wall for sites that pretty knowingly
have milked their search results to pull in Google traffic.
While the policy has been in place for several months, I still see plenty of
search results and category results showing up. Valleywag recently
highlighted how Technorati turns up often for generic Google searches. In
addition, my
From The Isn’t It Ironic
Dept: Google Product Search’s Results Show Up In Google article focused on
how Google Product Search results were showing up in Google, despite the policy. That was an understandable oversight — but the screenshots also show how plenty
of other shopping results remain in Google, despite supposedly being a bannable
offense.
Finally, in checking on the New York Times, I plugged in
cars to see if it was ranking
for that term. It wasn’t, but the Los Angeles Times was — and that listing
caught my eye. See it at the bottom here:
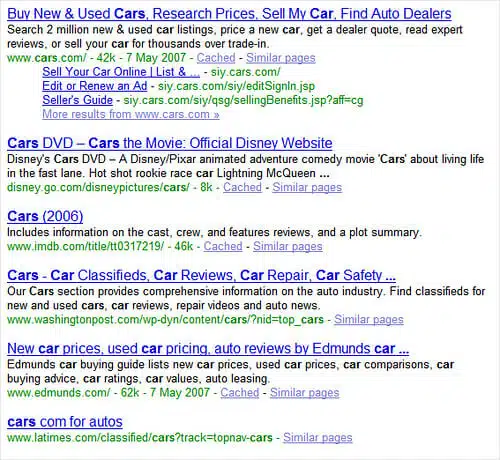
The title is all in lower-case, and there’s no cached version. That’s the a
sign that Google is listing a "partially-indexed
URL," one that it can’t crawl for some reason.
As it turns out, the title is in lower-case and without a cached version for
a different reason. That listing is actually just a link from the navigation you’ll
find at the top of Los Angeles Times pages, like this:

The link does a 302 temporary redirect to Cars.com. This is causing Google to
think that the LA Times is somehow the owner of the listing that formerly showed
Cars.com in that spot. Cars.com is still getting the traffic at the moment, but the LA Times
controls it — has technically hijacked it. If it wanted, it could redirect that
URL to anyplace else other than its Cars.com partner.
Google had largely fixed this hijacking problem. Threadwatch
noted last month that it
looked to have returned. Indeed, the cars search shows it in action big time.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author