Study Shows No Clear Evidence That Google+ Drives Ranking
At SMX Advanced, I presented results from a study we had done that convinced me that links in shares from Google Plus and Facebook behave like traditional web-based links. My statements at SMX Advanced were later disputed by Matt Cutts during his keynote interview by Danny Sullivan, leading to a live discussion — Matt even […]
At SMX Advanced, I presented results from a study we had done that convinced me that links in shares from Google Plus and Facebook behave like traditional web-based links. My statements at SMX Advanced were later disputed by Matt Cutts during his keynote interview by Danny Sullivan, leading to a live discussion — Matt even invited me up on stage during the keynote:

Image Credit: BruceClay.com
As a result of my keynote visitation, Matt and I agreed that I would rerun the study, this time with some guidance from him on potential problems. While this input was limited in nature, it did lead to some ideas on how to improve the testing. As a result of that dialogue, I determined that there were flaws in the original study we did, and therefore we would need to run another one. This has proven to be a very difficult process, but the results are now in. So without further ado, let’s dig in!
Study Design & Methodology
We picked three different sites, all of which have been on the web for at least two years or more, and we wrote two different, relevant articles for each site. One of these was used as a “Test Page,” and the other was used as a “Baseline Page.” Both pages were implemented without any links to them from any source whatsoever. Both of them received an initial set of Google+ shares on July 19th, 2013. The Test Pages received 6 shares each, and the Baseline Pages received at least 30 shares on that date.
From there, the paths diverged. We provided the Baseline Page no further attention other than to monitor indexing and ranking behavior. For the Test Page, we sent additional shares in two waves, as follows:
- At least 25 shares on August 4th, 2013
- Four more shares from very authoritative profiles between August 28th and September 1st.
Throughout the process, we monitored ranking behavior for the pages on a number of different long tail search terms. The August 4th and late-August burst of shares are particularly important, because if Google+ shares are, in fact, a direct ranking factor, there should be noticeable changes in ranking after those shares occur. This is the basic premise of the entire study.
Goals & Objectives: What Makes Our Study Different
Plain and simple, this is not a correlation study. For the record, I believe that correlation studies are extremely valuable — but as we know, correlation is not causation, and the study results presented here were directly targeted at measuring causation.
To accomplish this, we restructured the study from the one we presented at SMX Advanced, and set the following goals:
- Eliminate accesses to the Test Pages and Baseline Pages by humans or 3rd party tools prior to discovery of the pages by Google.
- We took a great deal of care to minimize the risk of the Test Pages and Baseline Pages receiving links.
- We then checked at every major step to see if there were any links implemented to the site (in spite of our efforts to prevent them).
- We used a panel of hand-picked participants to work with us on the study. The reason we did this was so we could have better control over their behavior.
Click here to see the complete study methodology, additional data and analysis.
Possible Sources Of Error
There are three main possible sources of error:
1. Missing Links: It is possible that links were implemented to the pages that did not show up in our monitoring tools. This is not an insignificant potential problem, as by my estimate the cumulative links found by Open Site Explorer, Majestic SEO, Webmaster Tools, and Ahrefs is probably at best 50% of the total links to a site, and it may be as low as 30%.
I base this statement on my experiences with helping sites recover from link penalties. At Stone Temple Consulting, we have helped more than 50 sites recover from penalties this year, and it has happened over and over again that we would help these sites by cleaning out bad links, only to have Webmaster Tools report lots of new links the next time it was queried. The reported new links were not new, and I have no doubt that Google knew about them before but simply did not choose to include them in the Webmaster Tools report. However, once we cleaned out some of the bad ones, we got exposed to some more of the links residing in their database.
2. Ranking Churn: The study was vulnerable to general ranking movement and algo adjustments that our Baseline Pages did not enable us to perceive. This is also a pretty significant risk. In fact, our results suggest that the scope of changes we saw were less than the general churn and movement of overall rankings.
3. Other Environmental Factors: Let’s face it — what Google uses to rank search results involves hundreds of factors. There are lots of variables that could impact the results. In spite of our attempts to minimize people accessing the content, a small number of people chose to do so anyway. We nonetheless believe that the results have validity for reasons you will see explained below.
Detailed Results
As mentioned, we tested articles on 3 different websites. What follows is a representative sample of the results from two of the sites: the Stone Temple Consulting site and New England travel website.
Stone Temple Consulting Results
The Test Page and Baseline Page tested on this site were articles written by two different users about notable search engine experiences they had. For the Test Page, we monitored the results for 11 different search phrases.
There was one search phrase that showed pretty dramatic movement. Here is the detail of the rankings of that phrase over time:
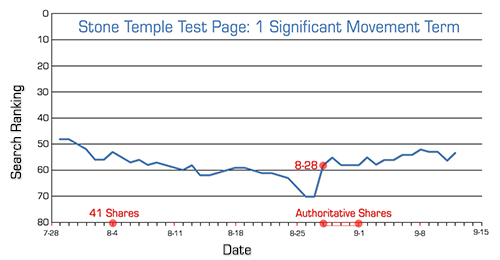
While there is significant movement, it does not occur until 24 days after the burst of shares on August 4th. This also happens to be just a few days after a lot of SEO community chatter occurred about a possible Google update (the chatter began on August 21st).
The behavior of the Baseline Pages is also pretty interesting to examine:
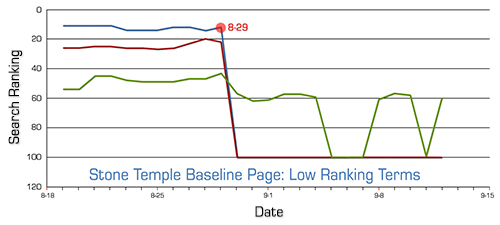

The movement of rankings on the Baseline Page occurs on the 29th of August, one day after the movement on the Test Page, and it moves in the opposite direction — the rankings get worse.
Travel New England Results
The Test Page and Baseline Page tested on this site were articles written by two different users about notable experiences they had traveling in New England. For the Test Page, we monitored the results for 10 different search phrases.
For this site, there was no material movement at all during the entire test:
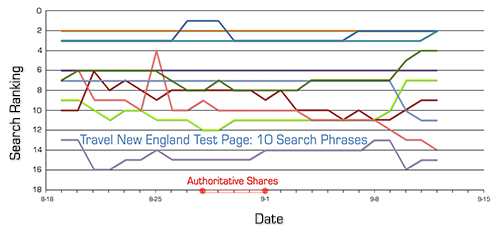
For completeness, this is what we saw on the Baseline Pages:
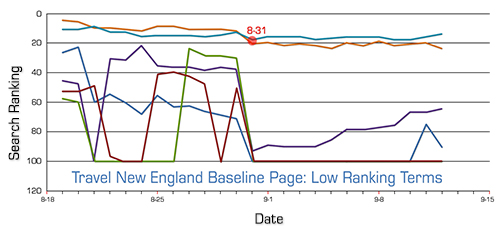
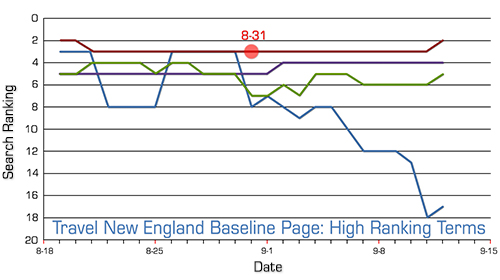
No major movement was seen at any time during the monitoring of the results for the test on this site. The Baseline Pages actually show more movement around August 31st than the Test Page terms do at any time.
Analysis
Our study had 3 major goals: to see if Google Plus would drive discovery, indexing, and ranking. So, I will comment on that in three independent sections as follows.
Discovery
In my opinion, it is highly likely that Google Plus drove discovery of the content. Here is a sequence of accesses to one piece on the Test Pages extracted from the log file on one of the sites:

The line items that refer to “+https://developers.google.com/+/web/snippet/” are Google Plus sharing events taking place to the content in question. And, of course, +https://www.google.com/bot.html is GoogleBot. Notice how it takes less than 6 minutes for GoogleBot to come to the page after the first share of the page, and there is a visit by GoogleBot to the site for each share. There are no other accesses of any kind to the content in this time period.
In addition, note that the Google Developers page for implementing +1 buttons states the following:
By using a Google+ button, Publishers give Google permission to utilize an automated software program, often called a “web crawler,” to retrieve and analyze websites associated with a Google+ button.
Indexing
Initial shares of all six articles occurred on July 19th. All of the articles initially appeared in the index on July 29th — 10 days later.
After a detailed review of data from Google Webmaster Tools, Majestic SEO, Open Site Explorer and Ahrefs, we found no links to any of the three pages using the available tools as outlined above. This does not mean that the content received no links, only that the available tools did not have those links, and this is a possible source of error.
One other point of discussion is that the long delay between the shares and the initial indexing does raise some concerns. Clearly, this G+ share data was not leveraged in real-time. Why did it take 10 days?
But, in summary, with the information available to me, I don’t see any other signals that would have caused the posts to be indexed.
Ranking
Once we saw that a page was indexed, we were immediately able to find search queries for which the page ranked. However, this does not mean that the shares were driving ranking. As per the original Sergey Brin/Larry Page thesis, each page on the web has a small amount of innate PageRank. This PageRank by itself might cause an ability to rank for certain types of long tail queries, even in the absence of any other signals.
In addition, a page with no links may also gain some benefit from the overall authority of the domain on which it resides. How this works exactly is not known outside of Google. However, it is clear that we need more data to be able to conclude that we would see potential ranking benefits from G+ shares. This is the reason we sent two additional waves of shares in the direction of the pages being tested.
To me, the most remarkable thing about the data in this part of the test is how unremarkable it is. Based on this data, my interpretation is that this study did not show material evidence of Google Plus shares driving rankings movement for the Test Pages. Read more on my thoughts on this in the summary below.
Analysis Summary & Commentary
Here is how I would sum it up:
- Google+ shares do drive discovery.
- Google+ shares appear to drive indexing, but there is some possibility of error if the pages received links we are not aware of.
- We saw no material evidence of Google+ shares driving ranking.
Our test was designed to eliminate distracting signals, and hence we did something that, in its own way, was a bit unnatural: we attempted to minimize (and, in fact, eliminate) reshares. The text description used in the shares of the articles was not normal — it was a warning to others to not look at the content. We needed to do that to try and get as pure a measurement as possible. These constraints could possibly impact the validity of the findings.
(Note: Behaviors such as organic reshares, comments, and other social activity could help improve rankings, but ordinary Web links do not depend on comments and reshares to carry weight.)
My opinion is that if there is any impact from links in Google Plus shares, that they do not get treated the same way a regular link does, even though we can see that links in Google Plus pass PageRank. Google can filter link signals, including those in Google+, at many levels. Why would they allow shared links to pass PageRank if they did not want to use that PageRank in some manner? Perhaps they want to use it to help them identify more authoritative profiles. There are already many who believe that the posts of more authoritative Google Plus profiles get indexed by Google faster and are shown in their followers’ Google results more often.
I acknowledge that there are many ways to point at the holes in this study, and I have offered my interpretation of it. Let the debate begin. What do you think?
Click here if you want to see additional study data, the complete study methodology, and additional analysis.
If you want to see a panel of industry experts discuss the results in this study, and the other studies on this topic, I will be hosting a Google Plus Hangout on Air event (a live broadcast discussion) on September 19th at 4 PM ET (Boston time) with Mark Traphagen of Virante, Inc, Joshua Berg of RealSMO, Pete Myers from Moz, and Marcus Tober of Searchmetrics.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author