Syndicated Content: Why, When & How
Done correctly, syndication can be a very effective way to help develop your reputation and visibility online. To many, this is a controversial topic, but it really shouldn’t be. You just need to know why it can help you, when to do it and how to do it the right way. And that’s what I […]
Done correctly, syndication can be a very effective way to help develop your reputation and visibility online. To many, this is a controversial topic, but it really shouldn’t be. You just need to know why it can help you, when to do it and how to do it the right way.
And that’s what I am going to take on today in this column. Yes, there are potential SEO issues with this, and we will discuss that later on in this post.
Content Syndication Vs. Guest Posting
First, let’s get clear on the difference between content syndication and guest posting, as they are not the same thing at all.
- Guest Posting is creating content for publication on a third-party website. We call it guest posting when you do not publish that content on more than one site, including your own site.
- Syndication is when you take content which is already published on your own site, and you give one or more other parties permission to post a copy of that content on their site. Note that the syndicated content can be a complete copy of the content on your site, or only a part of it.

Why Syndicate?
The reason you should consider syndication is that it gets you exposure to another website’s audience — I refer to this as “Other People’s Audiences” (OPA). Wherever you are in growing your business, exposure to OPA should be of interest to you. A key point here, however, is that you should only syndicate to sites that have an audience (or audience segment) that is relevant to your business.
You should also only syndicate to sites that are of higher authority than your site. Exposure to their audience brings obvious reputation and visibility benefits; and if the site is a respected authority, then some of the luster of that authority will reflect back on you. That’s a good thing!

When To Syndicate
You probably don’t want to syndicate every piece of content from your site. That will create a situation where there is nothing unique left for users to find when they visit. (You may also be worried about duplicate content issues, but we discuss that more below.)
This means you need to decide on the right time and place to do it. Here are some questions to consider when evaluating when and whether to syndicate a piece of content:
1. What Content Do You Syndicate?
In general, the rule of thumb here is that the content must be of interest to the site’s audience — so make sure that you are selecting topically relevant content for syndication. Additionally, you don’t want to waste the opportunity to build your reputation on a high authority site — so, scary as it may seem, you want to syndicate some of your best stuff.
2. How Much Of Your Content Do You Syndicate?
There is no clean formula for how much of your content to syndicate. It’s all about finding a balance. As mentioned above, you want to syndicate some of your best stuff so that you can build a good reputation with a larger audience — however, you’ll also want to ensure that there is a lot of high quality content which is unique to your site because the reputation-building benefit of syndication will give you the best results if people have an incentive to visit your site for more.
How much content to syndicate may also depend on your circumstances. If you are just starting out, you might be more aggressive with syndication in the near term just to get your name out there — especially if an opportunity presents itself to syndicate your content to a very high-authority site. If your reputation is more established, you might be more selective and sparing about content syndication.
How To Syndicate Safely
No doubt, many of you have been thinking that syndicating content creates duplicate content, and it does — but, if handled correctly, the search engines will have no problem with this at all. Here are the four best ways for dealing with that problem:
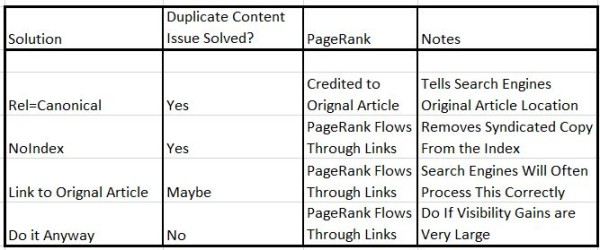
1. rel=canonical: The best solution is to have the site syndicating your content place a rel=canonical tag on the page with your article, and have that tag point back to the original article on your site. This tells the search engines that the syndicated copy is in fact just a copy, and that you are the original publisher. Better still, any links to the syndicated copy will accrue to the benefit of the original article.

2. NoIndex: The second best choice is to have them NoIndex their copy of the article. By telling the search engines to keep the syndicated copy out of the index, the duplicate content is also solved. In addition, links from the syndicated article copy back to your site will still pass PageRank.

However, this solution is not as good as the rel=canonical tag; with NoIndex, it is likely that much of that PageRank will be passed out of the copy of the article to sites other than yours, and the rel=canonical passes nearly all of it back to the original.
3. Direct Attribution Link: You should only use the third best choice when you are not able to get the publishing site to accept one of the first two. If that happens, make sure you get a link directly from the syndicated copy to the original article (not to your home page).
Most of the time, this is still a good enough signal for the search engines to figure out which version is the original. There is some risk that they will not get this right, but that risk is low.
4. Screw It, Do It Anyway: There are times where you might want to syndicate content, but the publisher is not willing to implement any of the above three solutions. For example, they may only want to link back to your home page as attribution. This scenario can lead to the higher authority site being seen as the original publisher, with your copy seen as a duplicate. If this happens, the other site will rank for your content and not you.
While that may sound pretty harsh, sometimes it still makes sense to do it anyway. When the exposure and reputation-building benefits are high enough, syndication without ideal attribution could still be a good move. Unless traffic to your own site simply does not matter, you should only do this very rarely (if ever).
Let’s take a look at all our options in a simple chart:
Summary
There are definitely times when syndication makes sense. It is all about understanding the reputation and visibility benefits, and also assessing how it fits into your long-term plans for your own website and business. There is no one formula here, and you will need to apply your own critical thinking to make decisions as to how this might fit into your longer-term strategy.
Syndication is not for everyone, and for many that use it, it will be done rarely. I did syndicate one piece of content last year, for example. When I released the results of my study on the impact of Google Plus on SEO, I published a shorter summary of that same study here on Search Engine Land.
The SEL copy garnered more than 1,200 social signals, which is pretty good visibility. The version on the Stone Temple (STC) website obtained over 600 more. What attribution method was used? The third one, a direct link from the SEL version to the one on the STC website. I’d do the same thing again.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author