Take Back Your Lost Links
Lost traffic after a website relaunch? Columnist Patrick Stox provides a handy guide on how to reclaim your lost links with redirects.

It’s a familiar story for many in the industry: A company just launched a new website, and their traffic has dropped! Now, we have to figure out what went wrong.
If we’re lucky, the new website will have an obvious problem — the company eliminated a lot of content, something is affecting the indexing, or the on-page optimization has some issues. Other times, we’ll see an obvious drop in inbound links and realize someone probably didn’t implement the redirects correctly. Perhaps the company who built the website skipped doing redirects, which creates a problem in that we likely don’t have a list of the old URLs or site structure to properly map and implement the redirects.
When There’s No Obvious Culprit
In rare cases, the site structure may be the same, URLs the same, redirects from the previous website are done, content is the same, there are no indexation issues, and on-page optimization is just as good as the previous version; yet somehow, the traffic, rankings, and links still drop.
It’s possible the problem is still redirects, but from previous versions of the website that haven’t existed in years. 301 redirects are meant to pass the value of links and the user from one page to another or one website to another. Rarely are redirects from previous versions of the website carried over and updated when a new website is launched.
Part of the problem comes from the fact that a 301 redirect is called a “Permanent Redirect,” so there is a common misconception that they are in fact permanent. In actuality, the 301 redirects are permanent only as long as the redirects are still in place.
I often see companies who have changed domains, and a few years later, when their old domain expires, it causes a drop in rankings and traffic. This is because they have lost the links from the old website that they thought had been permanently redirected. Anyone who has ever had an .htaccess file with a lot of redirects accidentally overwritten will tell you quickly that 301s are not actually permanent.
[pullquote]301 redirects are permanent only as long as the redirects are still in place.[/pullquote]
Google Webmaster Tools seems to keep data about a website and its content and links forever. I’ve seen crawl errors where the page is linked from another old page on a version of the website that hasn’t existed in 15+ years. Google still knows the content that existed, as well as internal links and external links to those pages, after all that time!
Why Should A Business Care?
If a business had been paying for SEO or naturally acquiring links throughout the years, some of the value they had built may be lost in a website relaunch. The pages where those links pointed now probably return a “404 – Not Found” status code, and those links no longer pass value to their website. Sometimes, we’re so focused on getting new links that we forget to keep all of the old ones!
The below example shows a website with stable organic traffic. After a website design, redirects were not implemented correctly, and I was brought in about a week later to fix the issue.
Within a couple weeks, the redirects were in place; within a month, the organic traffic had doubled from previous levels. Redirects were done not just from the previous version of the website (which contained the same content with a different URL structure), but also through five generations of this website.

With Screaming Frog and the Wayback Machine, we can gather most of the URLs from previous generations of the website. Then, using Screaming Frog and Microsoft Excel, we can verify all redirects are done and reclaim those precious lost links!
Screaming Frog Setup
To crawl the Wayback Machine with Screaming Frog to gather our old URLs, we need to configure the spider correctly. In Screaming Frog, under “Configuration” > “Spider” we can adjust the settings based on our needs.
Below is a screenshot with recommended settings. Depending on the vertical and how much traffic images drive to our website, we may want to grab image URLs as well.
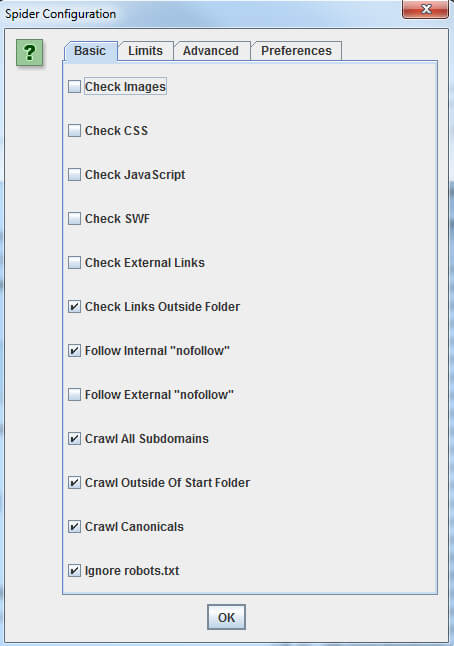
In “Configuration” > “Include,” add .*domain.com.* with domain.com being our domain. This will help with the crawler resources by only including links that include our domain name. To save time, we should also increase the number of threads which makes the crawl faster. The number of threads can be changed under “Configuration” > “Speed.”
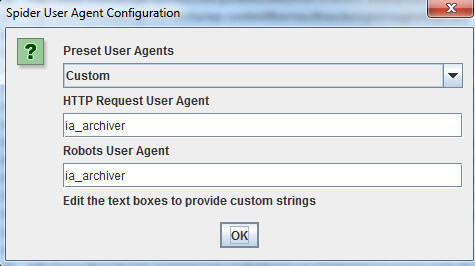
To be able to crawl the Web Archive, we need to also go to “Configuration” > “User Agent” and set the agent to “Custom” and as ia_archiver which is the crawler that is used by the Internet Archive.
Now that we have the settings, enter the URL https://web.archive.org/web/*/www.domain.com where www.domain.com is replaced with our website. If our website is very large or has had many versions archived, we may want to increase the memory from the default of 512mb (see a tutorial here).
Once the crawl is completed, go to the “Internal” tab, use the “Export” option, and save as an Excel document.
Free Alternative For Gathering URLs
The Wayback Machine has a way to list all the URLs for a domain in their index. Go to https://web.archive.org/web/*/https://www.domain.com/* replacing www.domain.com with our own domain, of course.
The problem with this is that we still need to scrape the data from the page. A better alternative might be to use their JSON API and convert the JSON output to a CSV file. There are a number of tools that can make this conversion, but web based ones may have upload limits or time-out issues depending on the size of our file.
To output our links in JSON format, go to https://web.archive.org/cdx/search/cdx?url=domain.com/*&output=json&limit=99999999. Once again, replace domain.com with our domain. We can adjust the output limit as well depending on the size of the website and how many times it has been archived.
Cleaning The URLs In Excel
We’ve gathered the data from the Wayback Machine with Screaming Frog, so now we need to use Excel to get the data in the format we need.
- Once we have the data in Excel, click the first URL (which should be Cell A4) and hit CTRL+SHIFT+DOWN.
- Copy all the URLs and paste them into another sheet.
- Hit CTRL+F and go to the “Replace” tab.
- Type *domain.com into the “Find what:” field with domain.com being our website, and leave the “Replace with:” field blank to get rid of all domain extensions as well as anything dealing with the Internet Archive.
- Select the column and go to “Data” > “Remove Duplicates,” which will leave us with a cleaned list of all the old URLs.
There are a few pages to watch out for here such as /, index.html, any special characters in the URL, and of course any pages that currently exist.
These will need to be removed from the list or they may have special conditions required for successful rewrites. Be warned that improper implementation can cause a redirect loop that may make your website unusable.
Crawl The Current Website And Compare The URLs
We need to crawl the current website with Screaming Frog and gather the current URLs. We wouldn’t want to redirect pages that already exist. We need to clean the current URLs as before using “Replace” to strip the domain.
- Place the URLs harvested from the Wayback Machine in column A and the current URLs in column B.
- In column C, enter =VLOOKUP(A1,B:B,1,FALSE) and copy the formula down. This is going to check the value in column A and compare it to column B and if there isn’t a match, the formula will return a value of “N/A.” It is the “N/A” values that we want.
- Add a new row at the top of the sheet so that when we filter, the first value is not ignored.
- Go to the “Data” tab in Excel and select the “Filter” option.
- Select column C and hit “Filter.”
- In the dropdown that appears, hit “Select All” to deselect everything and select the “N/A” value at the bottom of the list.
- What should be left are the values in column A that were not matched to current URLs. Select and copy these values.
Writing Our Redirects
- In a new sheet, paste the URLs into column B. These are the URLs we need rewrites for.
- In column A, enter “Redirect 301” (without the quotes) in a couple of the rows and select both rows so you are able to copy this value down without it counting 301, 302, 303, etc.
- The most time-consuming part of this process is filling out column C, where you will enter the full path to the most relevant current URLs.
- In a new column, enter the formula =A1&” “&B1&” “&C1 and copy this down. This should now write standard 301 redirects for page to page level redirects.
- Copy the column and use “Paste Special” to paste as “Values” rather than formulas, and you will have text that can be copied into your .htaccess file or a text document.
As mentioned earlier, there are many cases such as index pages or URLs containing special characters or spaces that need to be written differently so be aware of those.
Checking Our Work
We need to recreate the full URLs of our old pages in order to check that they are redirecting properly. A CONCATENATE function can help us add the domain back to our URL list.
- Use the formula =CONCATENATE(“https://www.domain.com”,A2) for example in cell B2 to add the URL path back to the domain.
- Copy the formula down to recreate all of our old URLs.
- These URLs are currently in formulas, so select and copy them and “Paste Special” as “Values” to get a usable list.
- Copy the new values to a .txt document or in newer versions of Screaming Frog we can paste them in directly.
- In Screaming Frog, go to “Mode” and select “List.”
- Load the .txt document that you just made with the “From a File…” option or if you prefer you can choose “Paste” to load the values from the clipboard.
- Screaming Frog will now crawl the old URLs.
Assuming we have placed the rewrites in .htaccess, the information returned can be sorted by status code to determine if there are any problems with the redirects. You can also go to “Reports” > “Redirect Chains” to see if any of the URLs are being redirected more than once. Ideally, all older URLs will point directly to the most relevant new URL, and none of the URLs should return a 404 status code.
I recommend crawling the website using Screaming Frog both before and after the redirects are placed to make sure no new errors are being caused by the redirects. If you left in an index page or redirected an existing page or category, your website may be unusable or part of the website may not be accessible.
That’s A Lot Of Rewrites
Too large of an .htaccess file can slow down your website. Redirects involving regular expressions may be more appropriate than individual page redirects.
The .htaccess file can also be split into multiple files based on the directory structure, which will make sure that the rewrites are only checked when someone tries to access that directory.
A better way for a very large number of redirects would be to avoid the use of .htaccess at all, and use the httpd server config file. There are times where a Rewrite Map may be the appropriate solution as well. Consult with your server expert to figure out what solution best fits your needs.
Can This Get You Penalized?
If the links to a site were less than clean in the past, restoring these lost links could result in a penalty for the website. Old links from article websites, guest posts, press releases, or deep link directories may have many keyword rich links to some of these pages and could trigger an algorithmic or even a manual penalty.
I would recommend that incoming links in Google Webmaster Tools should be monitored after implementing the redirects and the Disavow Tool used to get rid of any spammy links that may appear.
Don’t let your links be lost! Make sure someone at the business has control of all domains and is in charge of renewals. Have procedures in place to implement and maintain redirects in order to preserve the value of the links obtained over time.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author