Tricks For Taming Keywords With Regular Expressions
So far my articles about technical SEO have focused on how to adjust a site’s configuration or architecture to make it more crawlable and indexable. In this post, I’m writing about the other end of the technical SEO process: using analytics data to analyze traffic and user behavior by keywords. When looking at keyword data, […]
So far my articles about technical SEO have focused on how to adjust a site’s configuration or architecture to make it more crawlable and indexable. In this post, I’m writing about the other end of the technical SEO process: using analytics data to analyze traffic and user behavior by keywords.
When looking at keyword data, it’s important to group them by type. Looking at individual keywords is not only inefficient, but it will generally lead to information that is either misleading or worse, can’t be acted on.
The most precise way to group keywords is by using regular expressions. Regular Expressions are strings containing letters, numbers, and special characters that match a specific word or group of words.

Excellent tutorials for regular expressions are all over the Web, so I’m not going to include an overview here. Instead, I’ll present a few common recipes that I hope people will find useful and instructive. (Besides, because it has been scientifically proven that people learn mainly by imitation.)
If you’d like to see some tutorials, this is an excellent one, and the Google Analytics help page for regular expressions is here. SEOMoz recently posted a good overview here.
Using Regular Expressions Within Google Analytics
I’m going to focus on search keywords using Google Analytics because it has the best support for regular expressions. Other analytics packages I have worked with support most of these concepts if not exactly the same syntax. Excel’s support for matching keywords out of the box is pretty thin, but it appears to be possible to configure it to use regular expressions.
I didn’t want to show any data from my clients, so I asked my friends at Google to give me access to Search Engine Land’s Google Analytics account.* I’ll be using searchengineland.com data in my examples below.
To get to the organic keywords in the new interface, search for “organic” in the Find A Report… box:
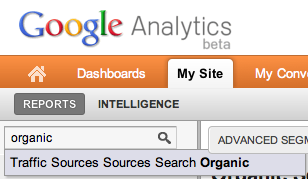
Or, browse to Traffic Sources > Sources > Search > Organic:
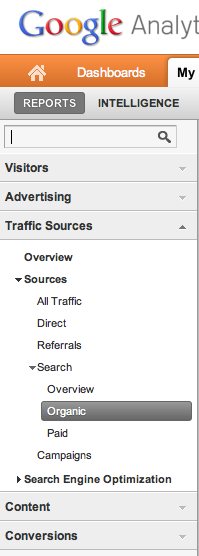
Branded Keywords
The most important regular expression to nail down is the pattern for branded keywords. User behavior for queries involving brand terms is going to be quite different than other queries. Branded search traffic tends to have a lower bounce rate, fewer new users, and a longer time on site.
So metrics for a group of keywords will be much more meaningful if you can exclude (or only include) queries containing branded terms.
To create the branded terms regular expression, I like to bring up the organic keyword report and try out a bunch of regular expressions, iterating slightly with each try.
The new Google Analytics interface doesn’t accept regular expressions by default, so it’s necessary to click on the “advanced” link next to the search box and select “Matching RegExp” from the drop down:
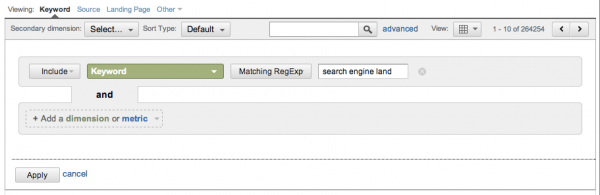
Now we are ready to start testing keywords, starting with “search engine land”.
This gets a lot of queries, but when I exclude that pattern, selecting “Exclude” from the dropdown to the left of Keyword, I see that I have missed a lot of other branded keywords.
The next iteration is:
“search ?engine ?land”
The ? means “0 or 1 of the previous character.” Now, the pattern matches whether or not spaces are included. This change nets an additional 15k visits for the time period that I selected.
I notice that many people are spelling search “serach,” so the next iteration is:
se(ar|ra)ch ?engine ?land
The parentheses/bar combination will match either option. This matches 118 more visits.
Unfortunately, my pattern is matching the website address searchengineland.com, which I want to exclude because that traffic is basically direct traffic.
First, I try to exclude a period at the end of the pattern with search ?engine ?land[^.], but this is no good because it excludes 99% of the visits that I wanted to include.
(Square brackets will match any of the characters listed, but if the first character is ^ then it will match anything but those characters.)
What I am trying to do is to match “any character that isn’t a period or the end of the query.” I can express this with search ?engine ?land([^.]|$).
- $ is a special character meaning “the end of the string.”
This matches fewer visits, but I am now able to exclude queries for the website URL.
When excluding branded queries in combination with other regular expressions, se(ar|ra)ch ?engine ?land is probably a better choice.
Now it is possible to compare the behavior of users who come to Search Engine Land from a branded versus an unbranded query. What I see is pretty typical for the sites that I work with.
Compared with visits from unbranded queries, visits from branded queries:
- Are three times more likely to be new visitors
- Spend five times as much time on site
- Have one-half the bounce rate
- View about twice as many pages per visit
In a pinch for tools with less sophisticated search, such as the Google Webmaster Tools query report or Excel, I would just use land to get a rough approximation.
Next, I’m curious about queries for search engines. This is easy to do with something like google|yahoo|bing. It isn’t always necessary to spell out the entire word if people are likely to misspell it.
For example, Baidu is searched for via three spellings (which I got by searching for ^b.*d[ou]$):
baidu, bai du, bidu
I can easily match any of those with ba?i ?du. So, I update my regex to:
google|yahoo|bing|ba?i ?du
Oops! I forgot Blekko!
google|yahoo|bing|ba?i ?du|blek
Another useful group of searches is for stock symbols. But the problem with goog is that it will match both “Google” and “GOOG.”
Here, it is necessary to use the very handy but somewhat obscure \b, which means “blank space, but only at the boundary of a word” or more simply “word break.”
So, I could use \b(goog|yhoo|msft|bidu)\b to match a group of stock symbols.
I would also track metrics for social networking-related queries with a regular expression like google ?(\+|plus)|face ?book|twitter|social net and exclude branded queries from the search.
- Note that + is a special character, so I had to escape it with a \.
Of course, I would track \bnemet\b, which resulted in 25 visits this year, half of which bounced.
Other Useful Patterns
These are a few regular expression patterns that I use for every site or certain types of sites.
Long unbranded tail
The “long unbranded tail,” which I define as queries containing three or more terms, excluding branded terms, is always important to track. I have seen sites for which this accounts for over half of organic traffic.
There are several ways to write this regular expression, but .+\b.+\b.+\b.+ is the way I do it.
- + means “one or more of any character” and \b means “word break.”
The entire expression could be interpreted as “at least three word breaks inside the query string.”
Because the query [search engine land] makes up most of the three word queries, excluding the branded pattern is important:

Unbranded queries with three or more terms make up almost 70% of the organic traffic to Search Engine Land. Search features like Google Instant and autocomplete have definitely increased the average number of words per query.
Queries From Google Finance
The Google Finance page for a particular stock, like Yahoo, has a URL like this: https://www.google.com/finance?client=ob&q=NASDAQ:YHOO.
Traffic from Google.com with “q=” in the URL will get treated as query traffic by Google Analytics.
A search using the regex (nasdaq|nyse|amex):[a-z]{1,4} will match these queries. [a-z] means “any character from a to z” and {1,4} means “repeated one, two, three, or four times.”
This doesn’t include the traffic from Google Finance for arbitrary queries, of course. And depending on what types of stocks your site covers, you may need to include more indexes like ftse.
To get a more accurate sense of traffic from Google Finance, be sure to include the referring traffic from www.google.com/finance/…
Addresses
Sometimes it isn’t possible to list out all of the possible query keywords. In that case, the best you can do is write a regular expression that captures enough of the queries to get meaningful data for trending, even if the absolute numbers aren’t so reliable.
For example, it’s not possible to list every possible street address. But limiting the regex to typical elements in a street address does a surprisingly good job.
I generally use \b(road|\rd|drive|dr|lane|way|ave|avenue|st|street)\b, which probably matches about 80% of the queries for a specific address.
It would further improve the accuracy to exclude branded terms or exclude another regex like:
sale|estate|pending
Another thing to try is putting a number in front of it like this:
[0-9].*\b(road|\rd|drive|dr|way|ave|avenue|st|street)\b
- The .* means “match any number (including zero) of any character,” so there could be any number or type of characters between the number and the rest of the regex.
The need to match queries containing a state abbreviation is pretty common. This regex assumes that only the two letter abbreviations are being used and that they appear at the end of the query:
\b(a[klrz]|c[aot]|d[ce]|fl|ga|hi|i[adln]|k[sy]|la|m[adeinost]|n[ehjmv]|n[cdy]|o[hkr]|pa|ri|s[cd]|t[nx]|ut|v[at]|w[aivy])$
It gets a few false positive matches (like “LA” meaning Los Angeles versus Louisiana or “CT” meaning court instead of Connecticut), but it brings back enough meaningful data for tracking metrics on these types of queries.
Other Resources
For testing or debugging regular expressions I generally use this handy dashboard widget (for Mac) or the Python interactive shell. There are many regular expression testers on-line and even Chrome extensions and Firefox add-ons.
I hope this post gave you some ideas for grouping and tracking keywords. If you have interesting regular expressions that you commonly use and want to share, please feel free to include them in the comments below.
* This is obviously a joke. My friends would want money before giving me access to someone’s Google Analytics account. ;)
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author