How and why the SEO tools industry should develop technical standards
Could SEO benefit from a collaborative effort to establish industry standards for SEO software? Contributor Michael King discusses the value this would have -- as well as the challenges it would present.

The SEO technology space could benefit tremendously from the establishment of technical standards. Implementation of Google’s own specifications is inconsistent within our tools and can lead less-experienced SEOs to believe their sites are in better shape than they are.
In the same way that the W3C rallied around the definition of protocol standards in 1994 and the Web Standards Project (WaSP) standardized coding practices in 1998, it’s our turn to button up our software and get prepared for what’s coming next.
Stop me if you’ve heard this one. On December 4, I received an email from DeepCrawl telling me that my account was out of credits. That didn’t make any sense, though, because my billing cycle had just restarted a few days prior — and, frankly, we haven’t really used the tool much since October, as you can see in the screen shot below. I should still have a million credits.

Logging in, I remembered how much I prefer other tools now. Noting the advancements that competitors like On-Page.org and Botify have made in recent months, I’ve found myself annoyed with my current subscription.
The only reason I still have an account is because historical client data is locked in the platform. Sure, you can export a variety of .CSVs, but then what? There’s no easy way to move my historical data from Deep Crawl to On-Page or Botify.
That is because the SEO tools industry has no technical standards. Every tool has a wildly different approach to how and what they crawl, as well as how data is stored and ultimately exported.
As SEO practitioners, a lot of what we do is normalizing that data across these disparate sources before we can get to the meat of our analyses. (That is, unless you take everything the tools show you at face value.) One might counter that many other disciplines require you to do the same, like market research, but then you’d be ignoring the fact that these are all just different tools storing the same data in different ways.
As far as migrating between platforms, it is only the enterprise-level providers, such as Searchmetrics, Linkdex, SEOClarity, Conductor and BrightEdge that have systems in place for migration between each other. This, however, still requires customized data imports to make it happen.
The precedents for web standards
Every industry has some sort of non-profit governing body that sets the standard. Specific to the web, we have five main governing bodies:
- World Wide Web Consortium (W3C) — They define the open web standard and are responsible for protocols like HTTP and the standardization of HTML, CSS and JavaScript.
- International Organization for Standardization (ISO) — Despite the fact that they don’t seem to understand how acronyms work, the ISO has defined seven specifications for several components of the web.
- The Unicode Consortium — They develop the character encoding standards for Unicode to ensure computability internationally.
- The Internet Engineering Task Force (IETF) — They define the technology standards for the internet protocol suite and have since taken over the HTTP standard from the W3C.
- European Association for Standardizing Information and Communication Systems (ECMA) — They defined the canonical version of JavaScript. Prior to the ECMA’s existence, there were five different versions of JavaScript based on the implementation within each browser.
Yet there is no governing body for SEO software in that way. This means that SEO tools are essentially the Internet Explorer of marketing technology, deciding which standards and features they will and will not support — seemingly, at times, without regard for the larger landscape. Harsh, but true.
If you dig into certain tools, you’ll find that they often do not consider scenarios for which Google has issued clear guidelines. So these tools may not be providing a complete picture of why the site is (or is not) performing.
For instance, Google specifies that JavaScript is fine for redirects between the mobile and desktop versions of a page, and no SEO tool can identify that. Also, irrespective of the recent 302 vs. 301 debate, that same specification says that you should use 302s for these types of redirects. There is no tool that is smart enough to determine whether a page that returns a 302 should return a 302. There’s also inconsistent review of HTTP heads despite the fact that Google will make determinations based on them.
So, why are there no technical standards?
Generally, the development of standards occurs when an organization or group of organizations gets together to decide those standards. If the standard is ultimately deemed viable and software companies move forward with implementation, users tend to gravitate toward that standard and vote with their wallets.
So what’s preventing the SEO tools industry from getting together and issuing technical standards? A few things…
- Proprietary advantages. Much of what SEO tools offer has come out of the vacuum that Google has created. For example, Google never gave us a reliable PageRank value or an easy way to determine if a website is spam, so companies like Moz have developed their proprietary Domain Authority and Spam Score metrics. Meanwhile, Majestic has their own extrapolated metrics based on the PageRank concept, but how do you reconcile Citation Flow and TrustFlow with Moz’s metrics when you have links that one has discovered and not the other? In the case of Moz, they were able to plant their flag quite well, in that Domain Authority has supplanted PageRank as the popular measure that people use to determine link value. In my experience, very few people in the States speak of Majestic or Ahrefs’ metrics when they discuss the value of a link. However, some third-party standardization of these measures that allows the end user to translate Page Authority (Moz) into Citation Flow (Majestic) into URL Rating (Ahrefs) would make all of the data far more usable. The reality is that mindshare around these metrics is, indeed, a proprietary advantage. As indicated in the modern Edison vs. Tesla lawsuit filed by BrightEdge against Searchmetrics, some of these companies seem to care more about those proprietary advantages than delivering the best analysis.
- Relatively young industry. People love to mention how SEO isn’t quite old enough to drink yet. However, the industry is not much younger than the web itself. To put it in perspective, Google is younger than the SEO industry, and it has developed standards across numerous industries. It’s difficult to accept the idea that the youth of the industry is to blame for the lack of standards.
- Industry politics. Perhaps this is something that SEMPO could do, but the organization tried to establish a Code of Ethics for the SEO industry in recent years and was met with a lot of political strife. Far be it from me to know the ins and outs of SEMPO and its political history, but I suspect it would difficult for any one party to plant the flag for web standards. A combination of agencies and brands may need to get together and leverage their collective weight to make this happen.
What is the value?
The establishment of standards benefits the SEO community, as well as the clients and sites that we work on. There is really no benefit to the tool providers themselves, as it will require them to make changes that are otherwise not within their roadmap (or technical changes that they have decided against for any other reasons). It also sets them up to lose customers due to the ease of moving between platforms.
Ultimately, the value of technical standards for SEO tools comes down to better capabilities, better user experience and encouraging more competition around creative features. But more specifically, it helps with the following:
- Working to eliminate miseducation. The SEO industry is plagued by miseducation, much of which is born of passive negligence in keeping up with the latest trends and changes rather than active ignorance. We build tools as shortcuts. In other words, we look to our tools to be calculators, but sometimes they are placed in front of folks that don’t know the underlying math. The implementation of standards will help ensure that those SEOs are pushed to remain up to speed, or at least that their analysis is more likely to be accurate.
- Data portability. The ability to go from one tool to the next is a given that exists in most software. From browsers to email to CRMs to marketing automation platforms, and even Google itself, users can generally download their data in its entirety, upload it into another tool and use it right away. Even though every tool in our space has a different interpretation of how things should be recognized and analyzed, they all use the same inputs to create those outputs, so it should not be difficult to make the move if standards are in place.
- Keeping up with Google’s capabilities. There are many recommendations specified in Google’s webmaster documentation that a lot of SEO software does not follow or implement.
- Minimum feature requirements. While every tool provider has its own subset of features for various reasons, there are some that don’t have the minimum that users have come to expect. For instance, you would expect that any keyword research tool should be able offer you search volume and historical search volume trend on a keyword basis. You would also expect that tool to have an API that allows your analysis to scale. Establishing minimum feature requirements for tool types would ensure that whichever tool you use can, at a minimum, accomplish the same goals. This is exactly what Google does for the AdWords API, and why there was a crackdown on SEO software that used it because they didn’t implement the minimum functionality required to manage AdWords campaigns.
What needs to be standardized?
So where does the standardization process begin? What needs to be consistent across platforms in order for SEO tools to meet these needs? That’s up for debate, of course, but here are my suggestions:
1. Link metrics
Ideally, there would be a common understanding of how all the different link metrics in the space can be translated to one another. The technical hangup here is two-fold.
One, each provider has used its own estimations that follow and then diverge from the original PageRank algorithm, their own proprietary formulae, which are not public. Two, they each crawl a different segment of the web.
The first problem becomes irrelevant if all the link providers were to crawl the Common Crawl and publicize the resulting data.

Home page for Common Crawl
The Common Crawl is a public archive whose latest iteration features 1.72 billion pages. Anyone can download and process it as a means of web analysis. (In the past, I led projects where we used the Common Crawl as a corpus to extract influencer data and to identify broken link opportunities. But I digress.)
If Moz, Majestic and Ahrefs publicly processed the Common Crawl, they could all provide each other’s metrics or, more realistically, users could convert Ahrefs and Majestic metrics into the more widely understood Moz metrics themselves.
One caveat is that Moz now provides seed URL lists to the Common Crawl, and I’m unclear on whether that may create a bias to the study. I suspect not, because all the link indices would be limited to crawling just the Common Crawl URLs in this scenario.
While this open link metrics idea is likely a pipe dream, what may be more realistic and valuable is the establishment of a new set of provider-agnostic metrics that all link indices must offer.
Sure, they all give us the number of linking root domains and total number of links, but new quality measures that can tie all the datasets together after you’ve de-duplicated all the links would make the collective data infinitely more usable.
2. Crawling capabilities
Google’s crawling capabilities have come a long way. Aside from Screaming Frog, to my knowledge, all SEO tools still crawl the way they always have. All SEO tools perform analysis based on downloading the HTML and not rendering the page.
To that point, it’s difficult to trust what your SEO tool is reporting when Google can render the entire page and makes decisions based on initial JavaScript transformations.
Under the Gateway specification, crawling tools would be required to present you with the option of how you’d like to crawl rather than only letting you specify your user agent.
Under the hood, these crawling tools would be required to use Headless Chromium or headless QTWebkit (PhantomJS) in addition to the text-driven crawlers, with the goal of emulating Google’s experience even more closely.
3. Crawl data
No matter what the crawl provides, a standard should be specified that the columns are delivered in a standard order from all crawl providers. They should all export in the same format, potentially called a .CDF file. This would define the minimum specification for what needs to be included in these exports and in what order.
However, we would not want to limit a tool provider’s ability to deliver something more, so the export file could indeed include other columns of data. Rather, all tools would be required to import up to a certain column.
4. Rankings
Personally, I believe we need to rethink rankings as an industry. Rankings report on a context that doesn’t truly exist in the wild and ignores specific user contexts. The future of search is more and more about those specific user contexts and how they dramatically influence the results.
In fact, I’d propose that rankings should be open and available to everyone for free. Since Google is not going to provide that, it’d be up to a group of folks to make it happen.
We’re all stealing rankings from Google through a means that inflates search volume; each tool has its own methodology. What if, instead, there was a centralized data store where rankings were pulled via distributed means or sophisticated botnets that everyone could access, thus allowing anyone access to full SERP data? The tool providers, then, would be challenged to deliver enhancements to make that data more valuable.
STAT used to offer a Codex which gave free rankings on over 200,000 keywords. I believe that was a big step in the right direction toward my ideal. I also believe STAT is a great example of a company that enhances the data and allows you the ability to further customize those enhancements.

STAT interface [click to enlarge]
Nonetheless, I would love to see the minimum specification for rank tracking from all providers account for:
- Granular geolocation. Many rankings tools allow you to target a specific city or perhaps a ZIP code. Google Chrome’s Geolocation Emulator allows you to specify your location down to latitude and longitudinal coordinates, and rankings react to this specificity.
- Specific mobile contexts. Rather than just “smartphone,” the minimum specification should include the ability to choose different browser and phone model variants. For instance, Safari on iPhone 6 rankings vs. Chrome on Android rankings.
- Full SERP measurement. Measuring just the organic components of a search results page (SERP) is misleading at this point. At the very least, there should be some measurement of the interplay between paid and organic, as well as the various SERP features (e.g., news results, local packs, featured snippets) that take away from the visibility of organic rankings. Additionally, pulling CTR data from Google Search Console into this content gives you more actionable details on how you’re performing.
- Segmentation. With both Google and SEOs making the move towards clustering keywords, there is a lot of value in being able to segment keywords within your rankings system. Support for this should be common; users should be able to upload a specific CSV format that allows for easy segmentation, and ideally, the tools would suggest groupings based on standardized taxonomies. Google’s taxonomies may work well here.
5. Content analysis
Despite the fact that Google moved from strings to things years ago, there are still people examining search through the lens of keyword density and H1 tag targeting. Google has announced that entity analysis is where they start the understanding of query.
The following image illustrates how they approach this. In the example, they break the query, “Who was the US President when the Angels won the World Series?” into the entities US President, Angels and World Series, then systematically improve their understanding of the concepts until they can link their relationship and solve the problem.
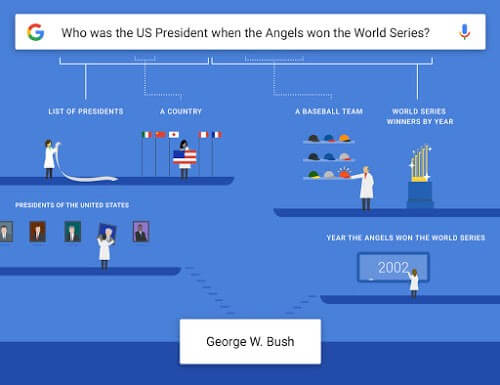
SEO tools are not consistently at this level of sophistication for content analysis. NLP, TF*IDF and LDA tools have replaced the concept of keyword density, but most crawling tools are not weighing these methods in their examinations of pages.
The minimum specification of a crawling tool should be that it extracts entities and computes topic modeling scores. A primary barrier to this happening in the case of TF*IDF is the availability of rankings, as the calculation requires a review of other ranking documents, but the open rankings initiative could support that effort.
Let’s get it started with a draft
Naturally, these are my opinions and, taken another way, this article could be misconstrued as my feature request list for the SEO tools industry. That’s exactly what it should not be.
Rather, this should be a collaborative effort featuring the best and brightest in the space to establish a standard that grows with the needs of modern SEO and the ever-changing capabilities of search engines.
The tool providers could get together to develop standards the same way the search engines came together to develop Schema.org. However, the lack of value for the tool providers makes that unlikely. Perhaps a group of agencies or the search industry media could get together and make this happen. These folks are more objective and don’t have a vested interest in those companies themselves.
Or someone could just start this and see who ends up contributing.
All that said, I have created a draft, called the Gateway Specification, following a similar format to the W3C HTML specification on GitHub. Although there is a bit of a barrier to entry in picking Git to manage this, I’ve decided that it’s the better way to go to start. A specification of this sort will need to be discussed in depth, and GitHub provides the facilities to do so.
To get involved, you’ll need to fork the repository, make whatever edits or additions to the document, and then submit a pull request. All those steps are outlined here. Please submit your pull requests, and let’s get the standards party started!
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
About the author