The benefits of dynamic rendering for SEO
Google is getting better at crawling JavaScript, but there are still limitations. At SMX Next, Nati Elimelich explained how dynamic rendering can overcome those limitations while avoiding potential cloaking issues.
JavaScript frameworks have been growing in popularity over the last few years, thanks in no small part to the flexibility they offer. “JavaScript frameworks allow for rapid development. It offers better user experience. It offers better performance and it offers enhanced functionality that traditional frameworks — non-JavaScript ones — sort of lack,” said Nati Elimelech, tech SEO lead at Wix.
“So, it’s no surprise that very large websites or complex UIs with complex logic and features usually tend to use JavaScript frameworks nowadays,” he added.
At SMX Next, Elimelech provided an overview of how JavaScript works for client-side, server-side and dynamic rendering, and shared insights for auditing gained from rendering JavaScript on over 200 million websites.
Client-side vs. Server-side rendering
Different rendering methods are suitable for different purposes. Elimelech advocated on behalf of dynamic rendering as a means to satisfy search engine bots and users alike, but first, it’s necessary to understand how client-side and server-side rendering work.
Client-side rendering
When a user clicks on a link, their browser sends requests to the server that site is hosted on.
“When we’re talking about JavaScript frameworks, that server responds with something that’s a bit different than what we’re used to,” Elimelech said.
“It responds with a skeleton HTML — just the basic HTML, but with a lot of JavaScript. Basically, what it does is tell my browser to run the JavaScript itself to get all the important HTML,” he said, adding that the user’s browser then produces the rendered HTML (the final HTML that is used to construct the page the way that we actually see it). This process is known as client-side rendering.
“It’s very much like assembling your own furniture because basically the server tells the browser, ‘Hey, these are all the pieces, these are the instructions, construct the page. I trust you.’ And that means that all of the hard lifting is moved to the browser instead of the server,” Elimelech said.
Client-side rendering can be great for users, but there are cases in which a client doesn’t execute JavaScript, which means it won’t get the full content of your page. One such example may be search engine crawlers; although Googlebot can now see more of your content than ever before, there are still limitations.
Server-side rendering
For clients that don’t execute JavaScript, server-side rendering can be used.
“Server-side rendering is when all of that JavaScript is executed on the server-side. All of the resources are required on the server-side and your browser and the search engine bot do not need to execute JavaScript to get the fully rendered HTML,” Elimelech explained. This means that server-side rendering can be faster and less resource-intensive for browsers.

“Server-side rendering is like providing your guests with an actual chair they can sit it on instead of having to assemble it,” he said, continuing his previous analogy. “And, when you do server-side rendering, you basically make your HTML visible to all kinds of bots, all kinds of clients . . . It doesn’t matter what the JavaScript capabilities are, it can see the final important rendered HTML,” he added.
Dynamic rendering
Dynamic rendering represents “the best of both worlds,” Elimelech said. Dynamic rendering means “switching between client-side rendered and pre-rendered content for specific user agents,” according to Google.
Below is a simplified diagram explaining how dynamic rendering works for different user agents (users and bots).
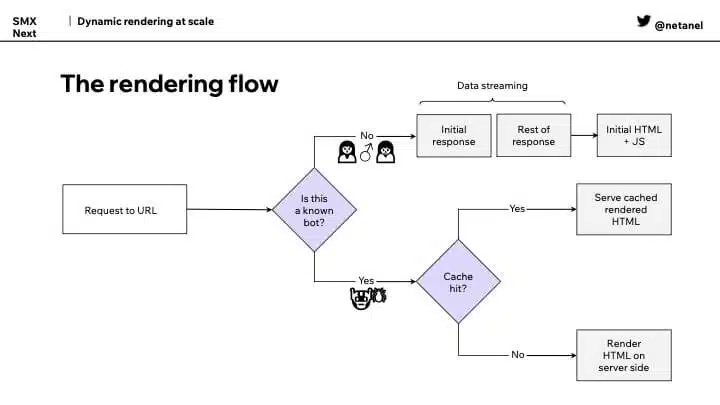
”So there’s a request to URL, but this time we check: Do we know this user agent? Is this a known bot? Is it Google? Is it Bing? Is it Semrush? Is it something we know of? If it’s not, we assume it’s a user and then we do client-side rendering,” Elimelech said.
In that case, the user’s browser runs the JavaScript to get the rendered HTML, but still benefits from the advantages of client-side rendering, which often includes a perceived boost in speed.
On the other hand, if the client is a bot, then server-side rendering is used to serve the fully rendered HTML. “So, it sees everything that needs to be seen,” Elimelech said.
This represents the “best of both worlds” because site owners are still able to serve their content regardless of the client’s JavaScript capabilities. And, because there are two flows, site owners can optimize each to better serve users or bots without impacting the other.
But, dynamic rendering isn’t perfect
There are, however, complications associated with dynamic rendering. “We have two flows to maintain, two sets of logics, caching, other complex systems; so it’s more complex when you have two systems instead of one,” Elimelech said, noting that site owners must also maintain a list of user agents in order to identify bots.

Some might worry that serving search engine bots something different than what you’re showing users can be considered cloaking.
“Dynamic rendering is actually a preferred and recommended solution by Google because what Google cares about is if the important stuff is the same [between the two versions],” Elimelech said, adding that, “The ‘important stuff’ is things we care about as SEOs: the content, the headings, the meta tags, internal links, navigational links, the robots, the title, the canonical, structured data markup, content, images — everything that has to do with how a bot would react to the page . . . it’s important to keep identical and when you keep those identical, especially the content and especially the meta tags, Google has no issue with that.”
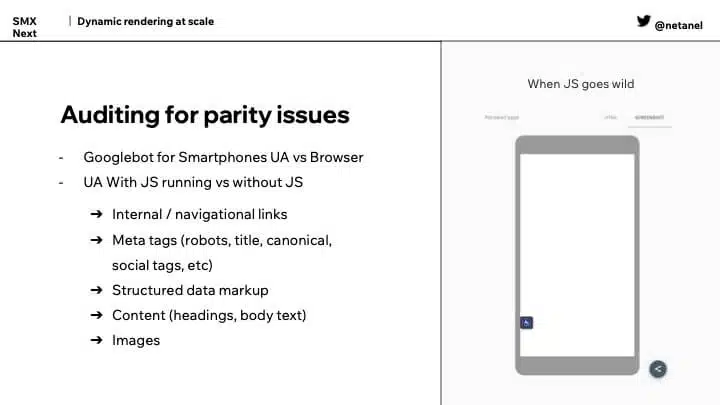
Since it’s necessary to maintain parity between what you’re serving bots and what you’re serving users, it’s also necessary to audit for issues that might break that parity.
To audit for potential problems, Elimelech recommends Screaming Frog or a similar tool that allows you to compare two crawls. “So, what we like to do is crawl a website as Googlebot (or another search engine user agent) and crawl it as a user and make sure there aren’t any differences,” he said. Comparing the appropriate elements between the two crawls can help you identify potential issues.

Elimelech also mentioned the following methods to screen for issues:
- Visual inspection by switching the user agent in the browser and/or turning off JavaScript to see if anything changes between the versions.
- Google Search Console can be used to see what kind of HTML is returned to Google and how it can render it.
- Testing tools, such as Google’s mobile-friendly test, the rich results test and Schema.org’s schema markup validator tool (formerly the structured data testing tool).
“Remember, JavaScript frameworks aren’t going anywhere,” he said. “Chances are you’re going to meet one of them soon, so you better be prepared to handle them.”
Watch the full SMX Next presentation here (free registration required).
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. Search Engine Land is owned by Semrush. Contributor was not asked to make any direct or indirect mentions of Semrush. The opinions they express are their own.


