What’s new with markup & structured data
Contributor Eric Enge recaps a session from SMX Advanced on structured data markup in its many forms.

Structured data makes certain types of web content highly accessible and understandable by search engines and other third-party programs. Because the data on the page is tagged with standardized identifying code, it’s far easier to process and interpret than a regular webpage.
For that reason, people refer to this type of data as “Linked Data” (similar to the way that the World Wide Web links billions of documents together).
At June’s SMX Advanced, Aaron Bradley did an awesome job in his presentation, “What’s New With Structured Data Markup?,” providing a detailed update of what’s going on in this area.
If you’re interested in a really detailed timeline of all the major happenings in the world of structured data markup, you can get access to that here.
The overview
In the SEO world, the most common form of structured data we speak about is Schema.org. This is because it’s a standard that was developed by and for search engines.
It’s stable, reliable and extensible. For that reason, its adoption has become very broad, and it has become the go-to vocabulary for linked data development by far more than the search engines.
As Bradley noted, it strikes the “right balance between complexity and expressiveness.” It’s also community-driven, and comparatively little development happens elsewhere.
The need for speed
One thing that most active participants in the mobile web agree upon is that there are major opportunities to benefit from increasing its speed.
Facebook led the way with its announcement of Facebook Instant Articles (FIA) back in 2015. What FIA did was to allow certain publishers to host content on the Facebook platform using a certain set of protocols, and in return, the social network gets content that loads pretty much instantly when a user clicks on it.
While this was initially open to only a limited set of major publishers, it was made globally available in April of 2016. The platform leverages HTML5 tags, op:tags, op-* classes and the Open Graph. The FIA platform exists only inside of Facebook, so you need to be comfortable with your content being hosted there. However, you can integrate your own ads and analytics, so you can still control those aspects of what’s published there.
(Or, if you prefer, you can have Facebook sell ads on your behalf, and currently, Facebook keeps 30 percent of the resulting revenue. However, this may be more attractive than it sounds, as there are publishers that report seeing an increase in revenue having Facebook sell their ads, rather than doing it on their own.)
There are the obvious benefits of having your content load incredibly fast, but some companies, such as Buzzfeed and Vox, have reported that it also increases your organic reach, so Facebook may be favoring this type of content.
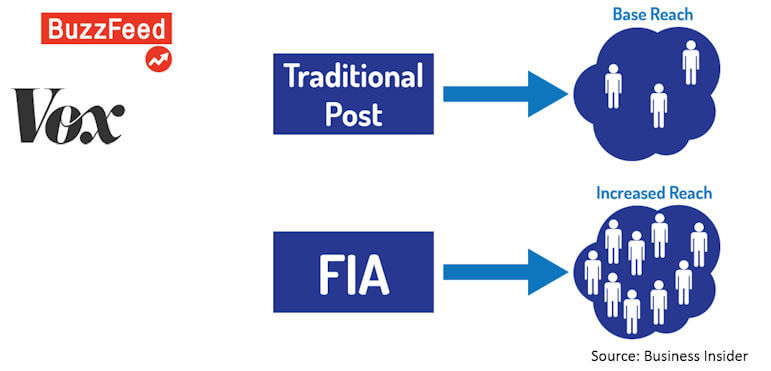
Next into the game was Apple, which launched Apple News Articles (ANA) in November of 2015 (with iOS9). Content for this is provided via Apple News Format or RSS. The RSS version uses some HTML and supports Open Graph and Schema.org. The overall format is JSON-based and has a lot of metadata that is similar to Schema.org.
Google was the most recent major player entering the fray, with its launch of Accelerated Mobile Pages (AMP) in February 2016. Implementing Schema.org in JSON-LD or microdata format is recommended, and Open Graph and Twitter Card markup are encouraged.
One big difference between AMP and FIA/ANA is that it’s an open platform. Other participants in AMP include Pinterest, Twitter and WordPress. AMP uses HTML elements, as well as its own JavaScript library. In fact, you’re not allowed to use any JavaScript elements that are not in the AMP-supplied library.
In some tests I performed at Stone Temple Consulting, I saw a 71-percent reduction in page size using AMP, and the mobile page speed score for our pages (tested with Google’s PageSpeed Insights tool) went from 42 to 88, a really nice jump in overall performance.

Rich results and rich cards
Google rich cards are a type of “rich result” that Google has made the basic unit for presenting its search results. It’s built on the notion of rich snippets and uses Schema.org markup to allow the display of content in the SERPs in a more engaging visual format. It also makes it easier for Google to mix and match different types of presentation units.
One of the main goals of this is to provide users with a better mobile experience. The image below gives you a quick look at the evolution of rich results over time.
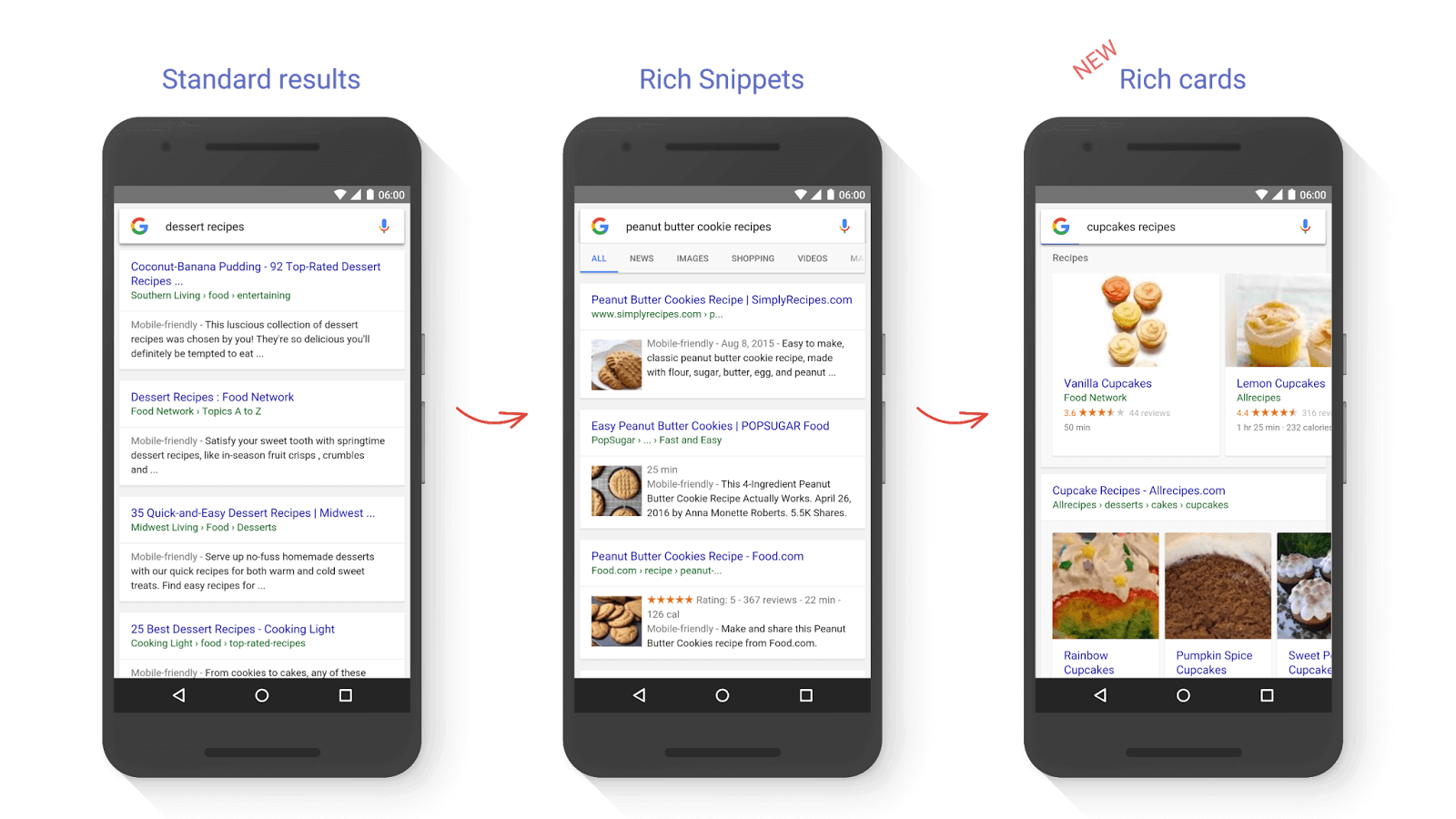
Image via Google [Click to enlarge]
The first two rich card content categories supported by Google are recipes and movies:

Support for rich cards is a part of AMP now, too, with the ability to see a mix of content from multiple sources (Try a query like “orlando news” on your smartphone) or from a single source (Try a query like “washington post”).

Google Structured Data Testing Tool previews
Google’s Structured Data Testing Tool offers great preview capabilities, and in fact, will flag errors that it spots in your structured data. You can see that here:
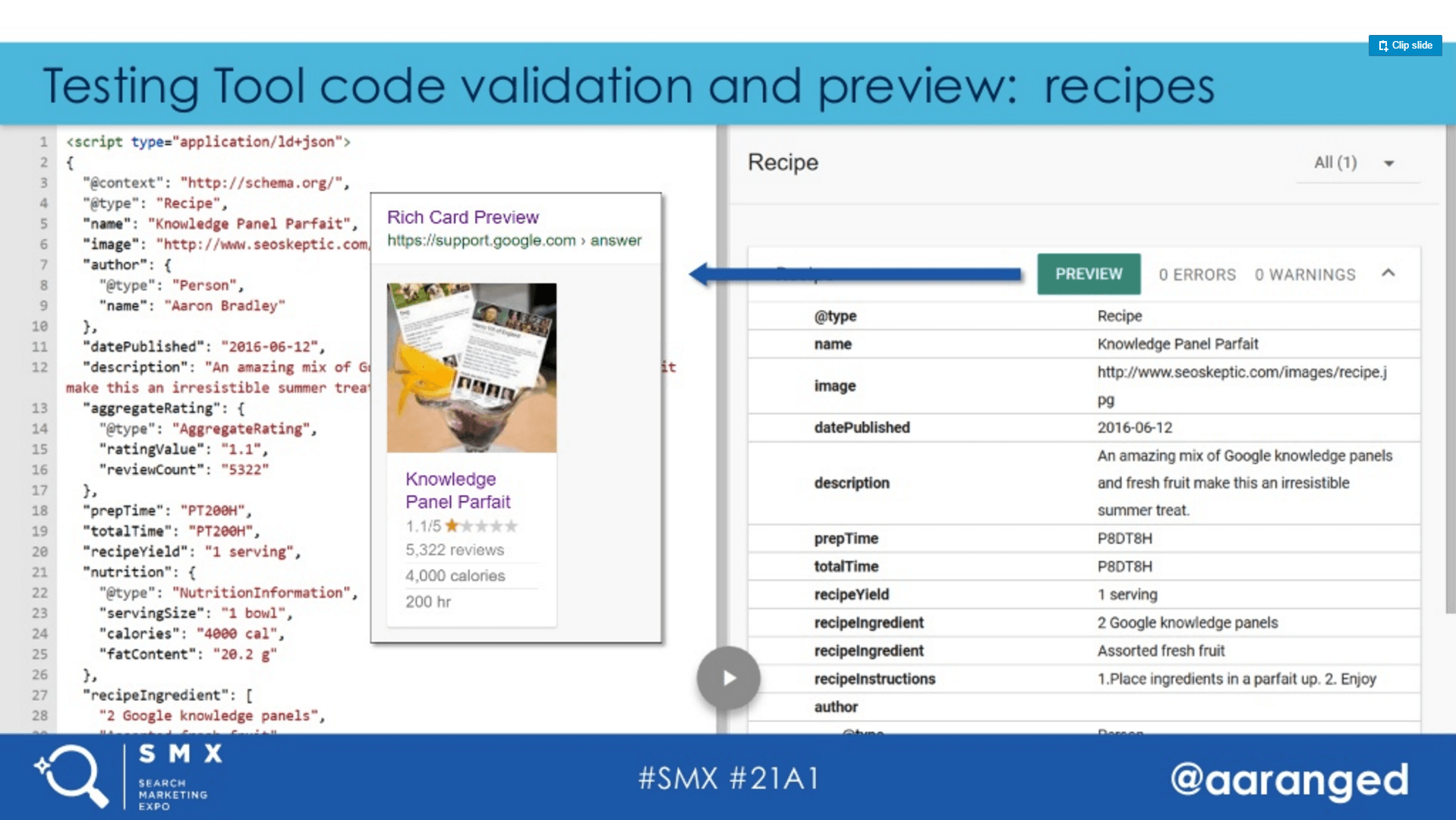
[Click to enlarge]
- All data type examples now open directly in the Testing Tool.
- Testing Tools results now list each declared entity separately.
- Keyboard shortcuts for search/search end replace functions.
- Rich cards report added to Search Console.
- Schema.org and JSON-LD auto-complete in the Testing Tool.
The rise of JSON-LD
If you’re not familiar with JSON-LD and what it’s about, this simple slide from Bradley’s presentation should help you get the picture in a quick nutshell:
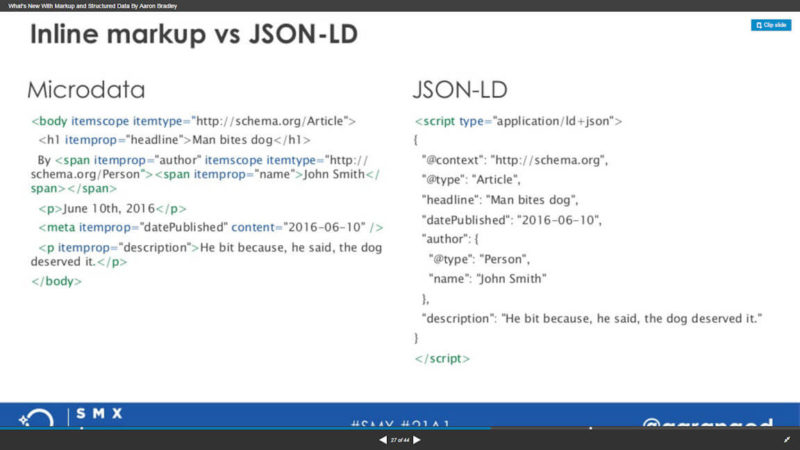
As you can see, the overall format is a lot simpler to look at, and as a result, it’s easier to implement without errors. Support for it was first added by Google in October of 2014, and it has been evolving ever since.
As of May 2016, Google officially supports everything but breadcrumbs. As a result of its simplicity, it’s reasonable to expect that more and more developers will move toward using JSON-LD as the preferred choice for implementing markup.
Many other players are adding support for JSON-LD as well. These include Yandex and Bing, although their support is limited. Among the distributed content platforms (AMP, FIA, ANA), only AMP provides support for JSON-LD.
Global Trade Item Number (GTIN)
GS1 defines trade items as products or services that are priced, ordered or invoiced at any point in the supply chain. GTINs are used to uniquely identify each of those trade items.

Building on top of that is the GS1 SmartSearch standard, and this exists as an extension to Schema.org. As a result, it provides many more detailed properties that e-commerce sites can leverage with their products.
Summary
I’ve reviewed and highlighted the first portions of the presentation, but there is much more in it that you can check out for yourself below. The bottom line is that the concept of linked data is an important one, and more and more platforms are going to support it. This makes it a key part of any website development effort, and it presents many opportunities that you should leverage.
Historically, many have thought that they would only implement Schema.org if there is demonstrable evidence that Google (or other search engines) make use of it to implement rich snippets/rich cards. Now it’s become important that you take a much broader view of Schema.org, and structured data more generally.
The reason why these formats exist is that it’s hard to parse free-form HTML that is implemented with any one of thousands of available publishing platforms and created by any one of millions of developers. Creating software that parse all that arbitrary code is a huge task. Structured data (Linked Data) makes that far easier, and it increases the certainty about what the true contents of the page actually are.
This is what is helping drive and fuel this movement. As more and more people add support, and as its overall structured data capabilities (and dependencies) grow, there will be more and more to gain by having your web developers master it.
See Aaron Bradley’s full presentation below:
Topics on this page
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. Search Engine Land is owned by Semrush. Contributor was not asked to make any direct or indirect mentions of Semrush. The opinions they express are their own.
