Google Hummingbird: When Evolutionary Becomes Revolutionary
The announcement of Google’s Hummingbird algorithm last month made quite a stir in the tech and SEO communities. In a blog post released the same day as the Hummingbird announcement, Google revealed some new features and ended the post with this: We’ll keep improving Google Search so it does a little bit more of the hard […]
The announcement of Google’s Hummingbird algorithm last month made quite a stir in the tech and SEO communities.

Question Answering – The Key to Understanding Hummingbird
In a blog post released the same day as the Hummingbird announcement, Google revealed some new features and ended the post with this:
We’ll keep improving Google Search so it does a little bit more of the hard work for you. This means giving you the best possible answers, making it easy to have a conversation and helping out before you even have to ask. Hopefully, we’ll save you a few minutes of hassle each day. So keep asking Google tougher questions—it keeps us on our toes! After all, we’re just getting started.
Read: Keep asking Google more and more tough questions to assist it in figuring out which questions to answer, both now and in the future.
Hummingbird and Google’s question answering system are not revolutionary in and of themselves. The components that comprise them are all evolutionary in nature and function in a synergistic, interoperable manner. Google is taking Question Answering technology (from the past) along with “big data” technology and simply making them work at scale — with phenomenal results. The overall picture is, in fact, revolutionary in nature.
The Question Answering Component: Form-Based Queries
Google Now allows the user to input queries as full questions and provides (or wants to provide) the best possible answers (even before you ask them, leveraging predictive technology). You can obtain the same functionality in Chrome on a laptop or desktop.
How does Google achieve its outstanding Question Answering capability? They use a technique which I believe Google refers to as form-based queries combined with natural language techniques as an “overlay.”
You may be asking yourself, “What exactly is a form-based query?” I have illustrated some basic examples below. In general, these are relatively easy to answer, as they tend to be simple look-up type queries in a database (the Knowledge Graph, in this case) and do not require much reasoning or computationally expensive joins.
Simple Examples Of Form-Based Queries
As you can see, the questions below cover the who, what, where and when type of question.
- Who is ?x (where ?x is typically an entity of type “person”) – unless a machine passed the Turing test
- What is ?x (where ?x is typically an entity of type “place” or “thing”)
- When did ?x happen? (where ?x is an entity of type “event”)
- Where did ?x happen? (where ?x is of type “event”)
- Where is ?x (where ?x is typically an entity of type “place” or “thing”)
And so on.
These answers exist already in the Knowledge Graph — which has curated, validated and verified answers — so Google can entirely trust it as an information source. The Knowledge Graph has authority.

Who is?x (where ?x is a person [Pablo Picasso])
The query above illustrates a query of the type, “Who is ?x.” The image below illustrates an example of a case where Google supplies an answer to the form-based query, “What is ?x.” In this example, you can see that ?x is evolving to become more complex than just a tangible “thing.” In this case, it is a concept which is the “China fertility rate,” something that needs to be parsed and understood in and of itself. It is possible in the case of “form-based queries” that it could be another form, namely: What is the ?x fertility rate, where ?x, in this case, would be an instance of a country.

What is ?x (where ?x is “the Fertility rate in China”)
Examples of two types of queries from the form-based queries are depicted above. You can see how Google is also getting better at determining user intent and providing more sophisticated answers, especially in the latter case, where they are required to map user intent to a more sophisticated concept (or form). You can also clearly see how more information provided in the user query (explicitly as well as implicitly) makes it easier to determine user intent and map it to the appropriate form-based query. More specifics on that follow.
The Process
So, how does this work? What is the process involved? In a nutshell, Google needs to understand the user queries. They take the query, leverage grammatical structure and boil the query down to one of these forms. They leverage user intent (and various other implicit signals to assist with determining this intent). They can then determine which form to map to.
In short, a simplified version of the process is approximately as follows, and this process may well change or be altered by leveraging machine learning. I would state this merely as an educated guess:
- Parse the grammar of the query
- Identity the form from the user intent
- Identify entity(s) involved
- Attribute synonyms
- Qualify what the user is looking for (refined intent)
- Determine what entities to retrieve
- Determine what properties those entities have
- Determine what to show the user in a meaningful way (the latter of which is device-dependent and needs to be attractive and engaging to the user)
Leveraging context and other implicit factors to understand the query is clearly critical, as understanding user intent is paramount for correct disambiguation and relevant synonym expansion throughout.
Google’s goal is clearly to expand on the number of forms and types of forms they can handle. And Google, as I have stated many times, is a master at big data. Google is merely taking older technology and making it work at scale. They can add new forms based on the combination of search volume (for queries from incoming sources, namely user demand) and lowest-hanging fruit (best bang for the buck, the latter being from a computational cost as well as the possible Question Space they can cover). And so, they keep adding to the types of questions that Google can answer.
You can also see here where Google’s acquisition of Metaweb and the concept of “entity equivalence” are enormously critical, as they now have the Knowledge Graph as a single source to which they can map all related information for an entity, and from which they can pull the required answers (entities and associated attributes or properties of those entities).
In light of the above, let us now re-look at Google’s latest announcement on its 15th birthday.
Let’s look at the first new feature announced in their blog post: “Comparisons and filters in the Knowledge Graph.” This means they added at least one new form which deals with the concept (and I am approximating here):
?entity1 vs. ?entity2 where both ?entity1 and ?entity2 are of the same type
Knowing what you do now of the Knowledge Graph, you can see it is just a matter of pulling up the required entities from the Knowledge Graph, looking at the associated attributes/properties, and figuring out the best means to attractively and engagingly display the answer to the user. An example in Google is depicted below.

Example of “Eiffel Tower vs. Empire State Building”
You can see where other search engines leverage the technology in a similar fashion; for example, if you type the same query into Wolphram Alpha, you get the example below:
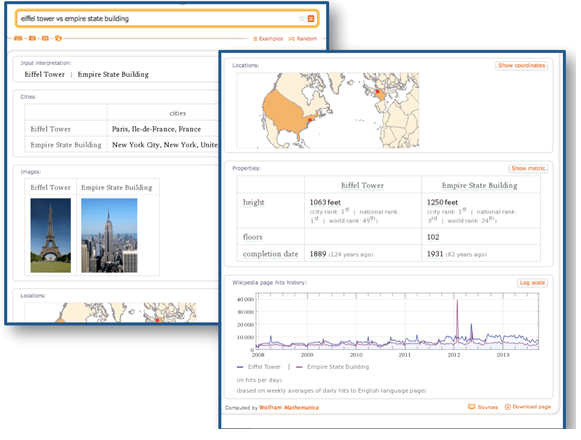
Example of “Eiffel Tower vs. Empire State Building” using Wolphram Alpha
The other two items in Google’s announcement also relate to optimizing displays across devices and leveraging the predictive capabilities of Google Now. These are also critical components of the Hummingbird ecosystem, necessary to maintain, support and give traction to the power embodied in the Knowledge Graph and Google’s ability to leverage Semantics at Scale and across devices.
The proliferation of new query patterns and different device types clearly require a paradigm shift, such as the move to a pragmatic semantic model, which was needed for the survival of search engines.
Personal Assistant Vs. Information Retrieval
You can clearly see where search is acting less and less as information retrieval and more as a personal assistant. Apple’s SIRI leverages semantics as well, initially using it to enable interoperability and the scheduling of services when a natural-language query is initiated. Google Now has similar functionality.
Takeaways — “Keep Helping Google”
- Think in terms of semantic markup. Optimize your website and let Google know what entities are on your site by adding semantic markup language — standards and schema.org are there for a reason. Machine-readable structured data are a great mechanism for telling the search engines what your site is about.
- Think API. Provide additional information that can be used to validate and verify your targeted info in the Knowledge Graph. If there is a means for providing search engines structured data via a data feed (or API), use it. If the information matches other information on your site (which it ought to), it is an additional strong signal in your favor.
- Think user intent. Make sure your website well represents your targeted entities. Your website must be representative of that notion.
- Make use of rel = publisher and rel = author. These are further pieces of essential information to provide Google and to leverage for your website. (Clearly, they ought to increase trust, reputation and brand awareness if used correctly.)
- Think personalization and implicit signals. These may be used to convey user intent in a query and target that aspect. This is presumably your target audience, so ensure you are targeting them with the correct intent.
Rankings were not too affected with this change — merely the way the data is displayed. It does mean, however, that items ranking even number one in Google are going to lose click-throughs to the site (depending on the query), as the traffic may be lost to the Google answer (within the Knowledge Graph) and thereby, to Google itself. Google can justify this with validity as it delivers a better experience to the end user.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author