Leveraging Search Algorithms In A Semantic Search World
Innovation velocity in the search world is causing knowledge graphs to become increasingly sophisticated and ubiquitous. In light of that, it is imperative that semantic Web groups and SEO groups maintain a frequent and open communication. The SEO of the future will need to have a strong understanding of how knowledge graphs work — as well […]
Innovation velocity in the search world is causing knowledge graphs to become increasingly sophisticated and ubiquitous. In light of that, it is imperative that semantic Web groups and SEO groups maintain a frequent and open communication.
The SEO of the future will need to have a strong understanding of how knowledge graphs work — as well as a solid grasp of semantic Web markup — in order to leverage this information for search marketing campaigns.
The Knowledge Graph: Things, Not Strings
On May 12, 2012, Google launched their knowledge graph, discussing it in a post entitled, “Introducing the Knowledge Graph: things, not strings.” The title alludes to Google’s continued evolution from a system that understands search queries as groups of keywords (“strings”) to one that understands them as references to real entities/concepts/objects (“things”).
Schema markup is an effective way for webmasters to denote “things” in a way that search engines understand, though Google has also become very good at associating “strings” with these “things” in the absence of such markup.
Take this example from Google, where the search queries [things to do in encinitas] — a string — and [tourist attractions in encinitas] — a thing that can be denoted with schema markup — actually produce identical knowledge graph results. Feel free to try it yourself with any location.

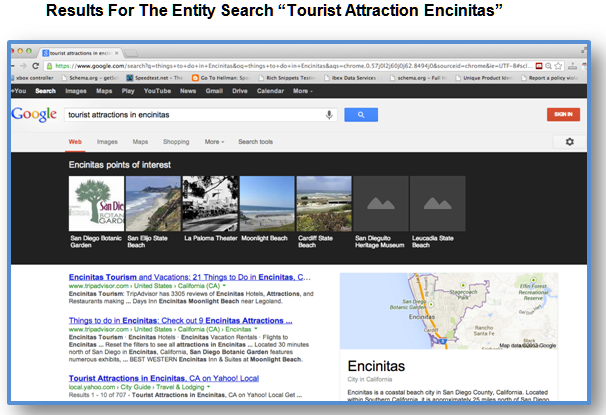
There are many mechanisms that could potentially be used for mapping search strings to entity results in the knowledge graph, but that is a subject in and of itself. Part of the point of the migration from “strings” to “things,” or the semantic search approach, is to make “things” findable.
Knowledge Graph Origins
Much of the information contained in Google’s knowledge graph was originally from dbpedia (the “graph based” or “linked data” version of Wikipedia) and from freebase (a consequence of Google’s acquisition of metaweb). I have cited the diagram below, as have others in many cases.
As an example of this, let’s look at PubMed, a free database accessing the MEDLine database of life sciences and biomedical topics. PubMed exists within dbpedia’s linked open data diagram below.

Searching for a medical or psychological condition in Google triggers knowledge graph results, and you can see an example of PubMed results in the Google Knowledge Graph illustrated below. The “National Library of Medicine” URL shown in the entry, in fact, takes you to a PubMed URL — as does clicking the links for Causes, Symptoms, Tests, Treatments or Prognosis.
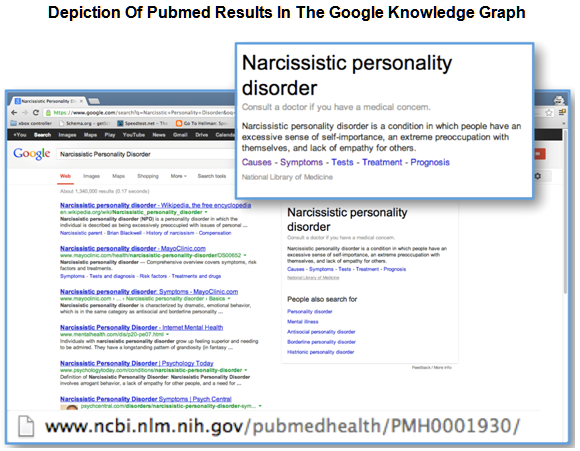
This seems to be an extension of Google’s decision to include medication information in the Knowledge Graph late last year, but the correlation to the datasets in the linked open diagram is still worthy of note.
Google Is Investing In Semantic Web
Another item of note in this arena is that Google has hired Denny Vrandečić full time. Denny has headed up the wikidata project, which was initially funded in part by Google and in part by the Allen Institute for Artificial Intelligence.
This isn’t the first time Google has invested in semantic Web talent, either. As another example, Dan Brickley, who heads up the schema.org initiative, is also a Google employee. Clearly, Google has plans for a continued integration of semantic Web technologies into their search engine.
Facebook Adds Structured Metadata To User Posts
Facebook has had structured data from day one, including basic user information that a user adds to their profile. However, they have had issues in terms of monetizing their traffic because of the limited granularity of structured data. Graph Search has certainly added an interesting dimension to that.
Continuing along that vein, Facebook’s latest mechanism that lets users add their own structured data to their posts is nothing short of brilliant and adds a phenomenal dimension to the utility and monetization aspects of their social graph. This announcement is close on the heels of Facebook’s Graph Search roll out to all US English users.
Emotion Markup Language
The W3C’s proposed Emotion Markup Language recommendation stated: “As the Web is becoming ubiquitous, interactive, and multimodal, technology needs to deal increasingly with human factors, including emotions.”
Along these lines, Facebook has created a very engaging new feature which allows users to add both moods and activities to their posts. All that natural language processing and other artificial intelligence technologies used to determine sentiment are no longer really necessary. Now, the user can just tell you their mood (they can even add their own from the list Facebook provides). Below is an image from Facebook of the options users are provided.
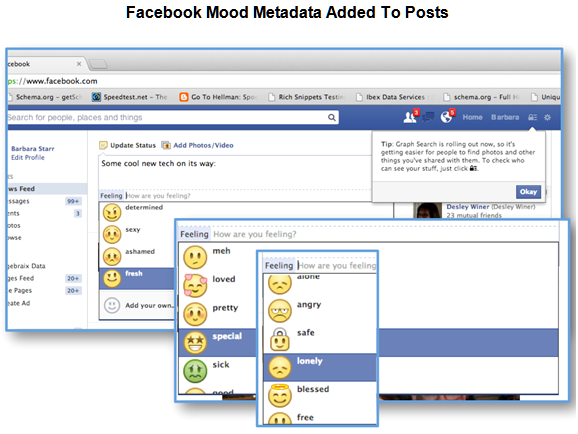
Gauging User Intent With Mood
Mood is a wonderful mechanism for gauging a user’s intent, especially for advertisers. For example, if you are a female and in a sad mood, perhaps now is the moment to make yourself happy by buying that pair of shoes you keep looking at to cheer you up. Or, if you are single and your mood is lonely — perhaps you are more likely to sign up (or renew) a membership to a dating service.
Yes, marketers can create great apps, gift giving services and more. But perhaps even better is the incredible dataset of structured information they will obtain about user behavior — and the deductions those predictive analytics engines can now make so much more accurately when it comes to customer retention issues (for dating services, or other subscriptions and services).
You can clearly see here an example of where adding metadata takes the work out of sentiment analysis. This tagged data can later be used for machine learning/training as well. There is now no need to “guess” at sentiment if advertisers can know it and what is associated with it.
Gleaning Information Via Activities
From your activities, advertisers will know what you do (and when you do it). Unfortunately, multitasking seems to be an issue; you can only select one option, it appears, at the time of this writing.
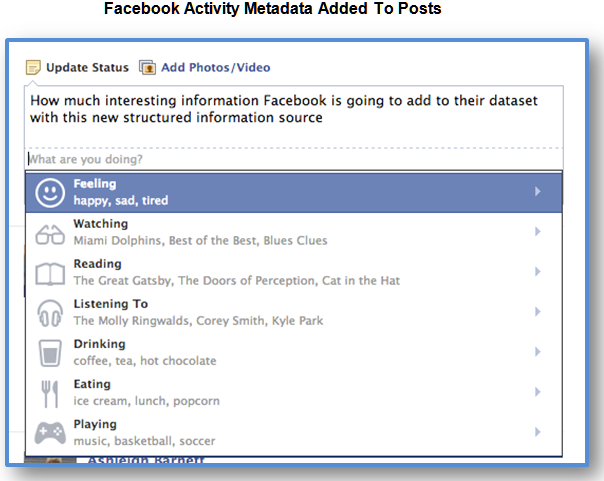
This information could well turn the corner for Facebook in terms of information provided to advertisers. I doubt it will be included in their Graph Search. However, on second thought, you could well want to find others in the same mood as yourself, currently performing or interested in the same activities. Then you could become friends or interact with them!
The Importance Of Innovation Velocity
I mentioned the importance of innovation velocity in search, addressing the fast pace of change taking place in search today, making it important for search practitioners to engage in “cross technology” pollination. This requires communication between semantic Web groups and SEO groups so the latter can stay current with the latest search know how.
- Semantic Search, Graph Search, Knowledge Graphs and Social Graphs are now a fact of life in the major search and social engines.
- Understanding how to leverage graph search is a key task for anyone in search marketing.
- Advertisers can capitalize on gauging user intent with emotion markup language, gleaning for information through activities.
- Herein rests the classic paradox: Innovation velocity is increased by providing “cross technology” pollination. The best way to keep up with the rapid velocity of today’s innovation is to leverage free, available resources and place yourself in that mix!
- Cross technology pollination means communication among semantic Web groups, SEO groups, etc., a key component to ensure you stay current with trends and the latest know how!
For those SEOs wanting to learn semantics, join a local Semantic Web Meet up on meetup.com – its free! For example, such a meetup is being held this month in San Diego, a Semantic Web 101, which you are invited to attend if in the area.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author