Removing URLs From The Index In Bulk
Need to remove URLs from the index? For a small number of URLs, this can be a relatively straightforward process — when you are dealing with thousands or tens of thousands, it can be a lot more complex, especially if you feel a great deal of urgency about the matter. This is what I am […]
Need to remove URLs from the index? For a small number of URLs, this can be a relatively straightforward process — when you are dealing with thousands or tens of thousands, it can be a lot more complex, especially if you feel a great deal of urgency about the matter.
This is what I am going to focus on today: situations where the amount of content is massive and the urgency is high. It turns out that you have several options — so let’s explore what they are!
Why Remove Content In The First Place?
There are many possible reasons, but here are some of the most common:
- You published content by mistake. This is certainly one of those that might cause you to feel a great deal of urgency. Accidentally published your company’s strategic business plan? Probably want to get that out of the index, fast.
- You discovered massive duplicate content. We all know that duplicate content is bad. Large quantities of it can definitely impact your traffic and rankings, so getting rid of it is important.
- Your site was hit by Panda for poor quality pages. Let’s say you think that set of 12,386 pages on your site is way too low in quality, and you are guessing that it led to your site being Pandalyzed. You want to dump them as quickly as you can!
- You received a notice in Google Webmaster Tools about pages violating Google’s guidelines. Worse still, it was accompanied by a drop in traffic. Ouch. You want to fix that one fast, too.
One quick followup on my Panda example: we have helped sites recover from Panda solely through noindexing perceived poor quality pages. The first site we helped had in fact been hit by Panda 1.0. Mind you, this only works if you can afford to cut off that limb to save the patient.
So, this is not always practical, but it can work if you recognize a large block of pages as the likely culprit, you know they are going to be hard to fix, and you can afford to live without them.
When you have large quantities of pages to remove, and there is reason to believe that Google and Bing will crawl these at a slow rate, you may need to move to more aggressive solutions. Google and Bing may crawl pages infrequently if your site has low PageRank, or if it simply believes they are poor quality pages (such as pages that are duplicate or that caused a penalty or algorithmic deprecation of your rankings).
The Basics
There are three basic tools in the toolkit. By themselves, these tools do not provide for rapid removal of content, but they represent an important part of the overall puzzle. The three basic tools are:
1. NoIndex Metatag: This is pretty straightforward. Place code like this on the page you want removed:
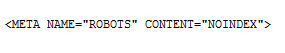
The next time a search engine crawls the page, it will come across the noindex tag, which directs it to not include the page in its index (or to remove the page from the index if it’s already there). The noindex tag is considered a directive, which means it will prevent the page from being indexed even if you screw up and put it on the wrong page — so, be careful! The page itself will still get crawled, though the search engines may visit it less often over time.
The other nice thing about this tag is that pages with the noindex tag can still pass PageRank to other pages both on and off your site. For this reason, do not specify “nofollow” with this tag. This chart summarizes the impact of the noindex tag:

2. Rel=Canonical Tag: This tag is implemented with code like this:
![]()
The tag suggests to the search engine that the page with the tag on it is either a duplicate or a subset of the page that the tag points to (the canonical page). The search engines may choose to obey this suggestion. Unlike with the noindex tag, they may choose to ignore it if they believe you have made a mistake in implementing the rel=canonical tag.
You should still use this tag with care. There are known cases of sites that implemented a rel=canonical tag on every page of their site pointing back to their home page. If the search engines obeyed that tag, it would essentially be a one-page site.
The rel=canonical tag has one big advantage over the noindex tag. While the noindex tag can pass some PageRank through links, the rel=canonical tag passes all its PageRank back to the target page listed in the tag. This is probably closer to what you want. Here is a chart to help you visualize the impact of this tag:

3. Robots.txt: To be clear, adding a page or a folder to the “Disallow” list in your Robots.txt file does not remove it from the index — it just tells the search engines not to crawl that page or folder. Thus, this is more of a preventative measure than anything else. However, while you can’t use your Robots.txt file to remove already-indexed pages, there are scenarios where adding pages to the “Disallow” list can be effective when used in conjunction with the URL Removal Tools, and I will discuss this below.
The main benefit of asking robots not to crawl certain areas of your site is that it saves on crawl budget. If you have a large and complex site, and search engines are not able to crawl all the pages, this could be important. We can summarize the impact of Robots.txt as follows:

Important Note: Don’t bother putting the noindex tag on pages that are listed in Robots.txt! Since the search engines won’t load the page, they will never see the tag!
Use With Great Care: The URL Removal Tool
The URL removal tools provided by the search engines themselves are the way to get things done fast. However, use this with extreme care. Doing this incorrectly can take your site (or part of your site) out of the index for extended periods of time. If you have any discomfort at all about how to use the tool, then do not use it. Simply rely on the other tools outlined above and wait out Google and Bing’s crawl times.
If you have survived the test of the disclaimers, here is what the URL removal tool does for you: It is fast. You don’t need to wait for Google or Bing to crawl the pages. You can get the pages out quickly. The tool will allow you to remove:
- A page
- A folder
- Your entire site
You can find the tool within Google Webmaster Tools here:
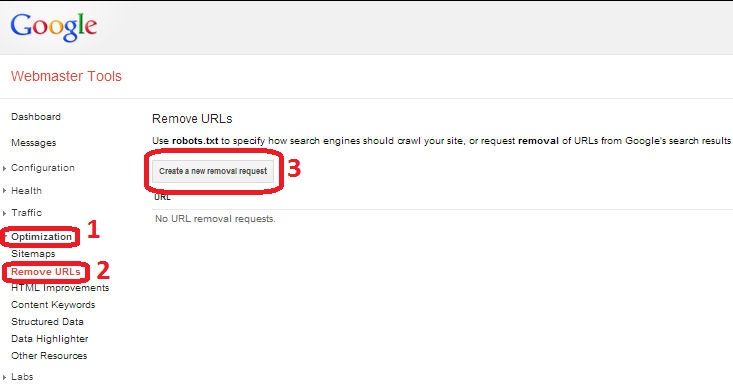
Use of the Google and Bing URL removal tools are straightforward, and documented in detail on these pages:
- Google’s URL Removal Tool Help page
- Google: When not to use this tool
- Bing’s URL Removal Tool Help page
When you are dealing with a large block of pages, the key is the ability to delete a folder. Note that this is only useful if all the pages you want to remove are in the same folder(s), and there is no content that you want to keep in those specific folders.
Combining The URL Removal Tool With The Basic Tools
Google’s URL Removal Tool only removes the content from their index for 90 days, so it is not permanent. It is important, therefore, that you take additional steps to make sure that content does not come back into the index. You need to combine its use with one of the Basic Tools discussed above. Here is a table that represents how I look at the choices:
| Tactic | When to Use |
|---|---|
| URL Removal Tool, Plus Deleting Pages and All Links to them, Plus 301s to Best Fit Pages | Always the best choice if there is no need for the pages to exist and if you are able to eliminate the pages. |
| URL Removal Tool Plus Rel=Canonical Tagging | The best remaining choice if preserving PageRank is a priority; however, you can only use this when your pages are a true duplicate or a strict subset of the pages that the tags point to. |
| URL Removal Tool Plus NoIndex Tag | Use when preserving PageRank is a priority, but the Rel=Canonical tag is not appropriate. |
| URL Removal Tool Plus DisAllow in Robots.txt | Use when reducing the number of pages that the search engines have to crawl is the priority. |
Summary
The first and most important step is to be paranoid when using the URL Removal Tools. You can seriously hurt your business if you do it incorrectly. Whoever does this for you needs to be very deliberate and precise — someone that you would trust the fate of your business to.
Again, the URL removal tools only help with large blocks of pages if those pages all exist within one folder or a small set of folders that do not also contain content you want to keep in the index.
But, if you have a very large number of pages that need to be removed, and it needs to happen fast, a URL removal tool can potentially be quite helpful. Just combine it with the right Basic Tool to ensure that the pages you are trying to remove stay out of the index for good.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author