Structured Data & The SERPs: What Google’s Patents Tell Us About Ranking In Universal Search
Columnist Barbara Starr delves into several Google patents to explore the ways in which the search giant is displaying search results based on structured data and context.

The use of structured data is now increasingly apparent in many aspects of search — but perhaps nowhere is it more evident than in today’s search engine results pages.
Search engine results pages have evolved considerably over the years. We’ve seen a shift from the classic “10 blue links” to an information-rich display that blends many different types of results. In addition to the standard organic search results we all know and love, we’re also seeing knowledge panels, image results, local packs, Google news, and more — each of which has its own unique algorithm for determining placement within these areas.
Google’s shift towards these “blended” search results that include Knowledge Graph-based information has had a marked effect on the search engine optimization (SEO) community. Not only do we need to start incorporating structured data into our SEO strategies, but we need to have an understanding of what factors determine which content gets displayed in different areas of the search engine results pages.
Today, I’m going to delve into some Google patents to help give you a better understanding of how the search giant is thinking about the display of search results based on structured data and context.
Ranking & Ordering Via Entity Metrics
A recent patent of Google’s, “Ranking search results based on entity metrics,” discusses the ways in certain metrics might be used by a search system (e.g. Google Search) to rank and order results.
The patent starts out by describing how a search engine algorithm works: It looks at a variety of metrics (what we typically refer to as “ranking factors”), then computes a relevance score based on a weighted sum of these metrics to determine placement within search results.
The patent also notes that “ranking search results may be distinct from ordering search results for presentation.” In other words, ranking is an internal measurement based on relevancy, whereas ordering refers to how search results are presented on a page.
So, what does this have to do with structured and entity search?
Well, the patent then goes on to describe how, in some instances, search results are based on information found within “data structures.”
[blockquote]In some implementations, search results are retrieved from a data structure. In some implementations, the data structure also contains data regarding relationships between topics, links, contextual information, and other information related to the search results that the system may use to determine the ranking metrics. For example, the data structure may contain an unordered list of movies, along with the awards and reviews for each respective movie. The search system may use the awards and reviews to determine a ranking of the list, and may present the search results using that ranking.[/blockquote]
In other words, information from various external data sources (such as Wikidata, a repository of structured data that helps to power Google’s Knowledge Graph) as well as structured data within your website could be used to determine search engine results page placement.
Entity-specific metrics might be used to enhance and refine this ranking/ordering process. In particular, the patent discusses four entity metrics: a relatedness metric, a notable entity type metric, a contribution metrics, and a prize metric. (Note: The patent also indicates that these 4 metrics are illustrative examples, meaning that others may also potentially be used.)
The four illustrative entity metrics are described as follows:
1. Relatedness Metric
The relatedness metric looks at the co-occurrence of an entity and its “entity type” on web pages. An “entity type” is generally a categorization or defining characteristic of an entity — for example, George Washington is an entity, of the entity type “US Presidents.”
[blockquote][W]here the search query contains the entity reference ‘Empire State Building,’ which is determined to be of the entity type ‘Skyscraper,’ the co-occurrence of the text ‘Empire State Building’ and ‘Skyscraper’ in webpages may determine the relatedness metric.[/blockquote]
In other words, when you type in a search query, Google may determine that a web page is more or less related to that query based on what other, related words are included on the page.
2. Notable Entity Type Metric
The notable entity type metric refers to the fact that an entity may be categorized under many different entity types, some of which are more “notable” than others — for example, Barack Obama could be categorized as an Author, Politician, Public Speaker and Celebrity, but he is most notable for being a U.S. President.
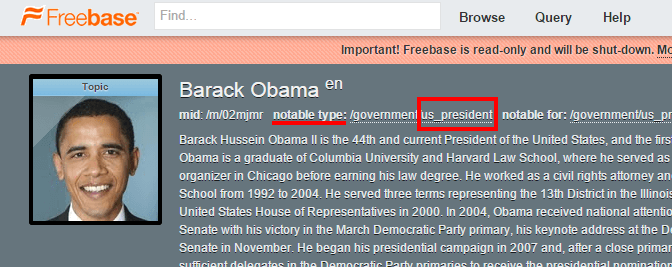
The notable entity type metric also takes into account that multiple entities can be of the same entity type, so one in particular may be the most relevant to a searcher. For example, both George Washington and Barack Obama are of the entity type U.S. Presidents — but a Google search for “us president” yields a direct answer containing Barack Obama.
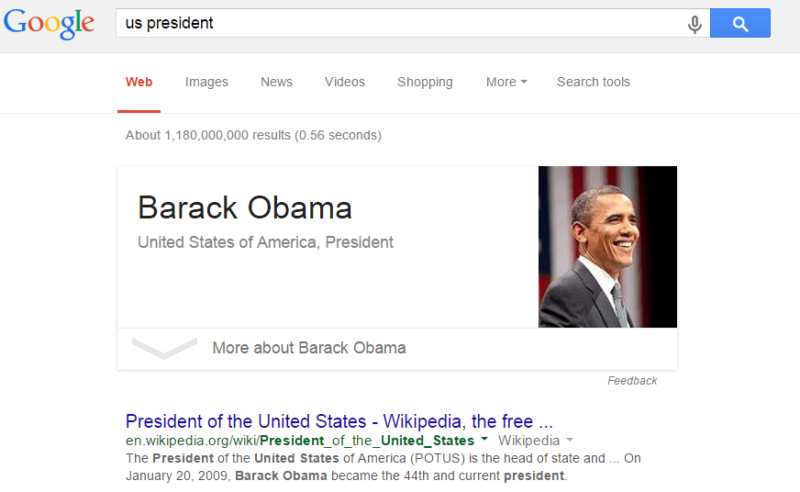
[blockquote]In some implementations, the value of the notable entity type metric is a global popularity metric divided by a notable entity type rank. The notable entity type rank indicates the position of an entity type in a notable entity type list.[/blockquote]
3. Contribution Metric (And Fame Metric)
[blockquote]In some cases, the contribution metric is based on critical reviews, fame rankings, and other information. In some implementations, rankings are weighted such that the highest values contribute most heavily to the metric.[/blockquote]
It is no surprise that Google may have discovered the power and potential of something like a contribution metric and then applied that to other domains leveraging context. These are a couple of other interesting tidbits regarding reviews that the patent provides which are stated as follows:
- “[I]nformation for determining a contribution metric may include social media, news sources, research publications, books, magazines, professional and user reviews on commerce websites, e.g. Amazon product reviews, professional and user reviews on dedicated reviewing sites, e.g. restaurant reviews on Yelp, user reviews on industry or domain specific sites, e.g. movie reviews on IMDB, any other suitable source of information, or any combination thereof.”
- “[T]he search system may combine professional critic reviews and user reviews of restaurants, giving more weight to the professional reviews and less weight to the user reviews.”
The Fame Metric
A sub-metric of the contribution metric, the fame metric takes into account all the contributions of a particular entity. “For example, the fame metric of a movie actor may include a summation of the contribution metrics of that actor’s movies.”
Check out the search engine results page below for actor Tom Hanks. You can see below that the “contributions” involved in calculating this fame metric (in this case, his movies) are displayed prominently in the Knowledge Graph Panel in its own dedicated area, as mapped to the knowledge panel template in Google’s patent, “Providing Knowledge Panels With Search Results.”

A screenshot of the Google search results page for “tom hanks.”
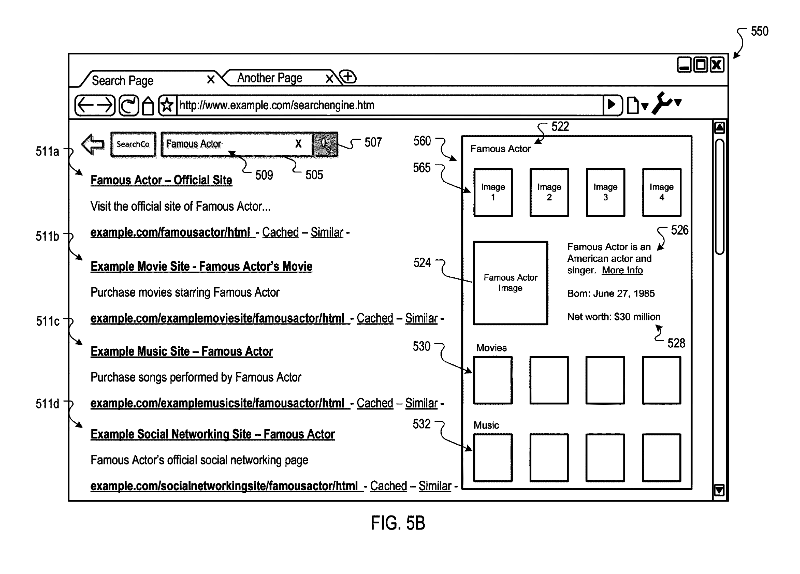
FIG. 5B is a screen shot of an example search interface in which a knowledge panel is presented with search results. From Google’s patent, “Providing Knowledge Panels With Search Results”
4. Prize Metric
[blockquote]The prize metric is based on an entity’s awards and prizes. For example, a movie may have been awarded a variety of awards such as Oscars and Golden Globes, each with a particular value. In some implementations, the prize metric is weighted such that the highest values contribute most heavily to the metric.[/blockquote]
The patent provides strong evidence that semantic web technology is being used as background context for the definitions of the metrics and the environment in which they are framed.
Different Algorithms For Different Screen Areas
There are many interesting elements to the patent, and the last I wanted to address is Figure 3.0 below.

Figure 3 – Ranking Entity Metrics in Search Results Patent
At first glance, it looks very innocuous, like an image of standard search results with a bunch of links. You find those sort of diagrams in many search patents. However it is accompanied by a very intriguing explanation of the figure, part of which reads as follows:
[blockquote]It will be understood that the presentation of search results in user interface 300 is merely an example and that any suitable presentation of any suitable results may be used. In another example, results may be image thumbnail links, ordered horizontally based on score . In another example, search results may include elements of a map and the search system uses score -* to determine which elements to present on the map.[/blockquote]
What is interesting here is that it seems that specific regions of the search results are defined or templated in some manner, and ranking/ordering for each varies by context or domain. (Have you noted those fine lines on the screen demarcating or separating results in your search results?) From an SEO point of view, this means that optimizing a company’s website or web presence will be based on targeting these templates, each of which may well have their own ranking algorithm based on context.
As further food for thought, I would like to close with the diagram below, which shows an image from a patent on context, “Maintaining Search Context,” compared to a Google search engine results page for “golden retriever.”
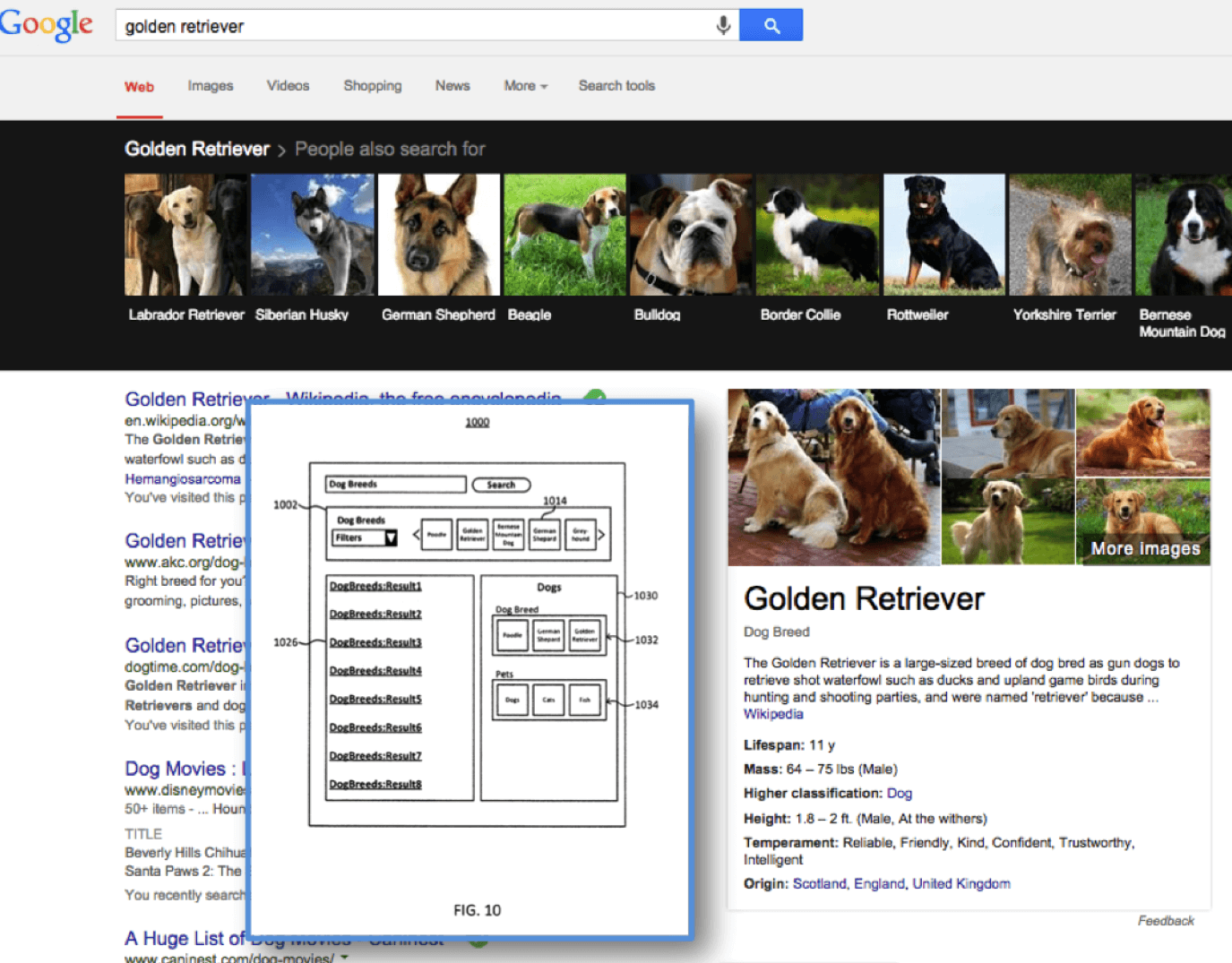
Figure 10 from Google’s “Maintaining Search Context” patent, compared to Google search results for “golden retriever.”
[blockquote]FIG. 10 shows user interface 1000, [which] includes exemplary content displayed in response to receiving a search query “Dog Breeds.” In some implementations, the search system displays related entity area links in the related entity area 1002, […] including “Bernese Mountain Dog,” “Poodle,” Golden Retriever,” “German Shepherd,” and “Greyhound.” The search system displays search results related to the query “Dog Breeds” in a search result area 1026. The search system displays information related to the entity “Dogs” in an information area, for example information area 1030. Information area may include links to other types of entities such as information area links 1032 to entities of the type “dog breed” and information area links 1034 to entities of the type “Service Animals.”[/blockquote]
As you can see, different areas of the screen correspond to different result sets for the same query, presumably each with their own distinct algorithm for ranking and ordering information.
Takeaways/Summary
With the increasing shift from keyword search to entity search — and with the increased growth and usage of Knowledge Graph Panels and other data-based displays — comes the corresponding shift in the direction of SEO.
Ordering of items and ranking of information driven by a need for a positive and personalized user experience means that different algorithms apply at different times. These algorithms are based not just on traditional ranking factors that assess relevance and authority, but also by how data may be optimally visually displayed for various device types and screen sizes.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
About the author