Mixed Directives: A reminder that robots.txt files are handled by subdomain and protocol, including www/non-www and http/https [Case Study]
Since robots.txt files impact crawling, it’s important for site owners to understand how they are treated by search engines. Columnist Glenn Gabe covers two cases involving multiple robots.txt files (by subdomain and protocol).

I have run into an interesting robots.txt situation several times over the years that can be tricky for site owners to figure out. After surfacing the problem, and discussing how to tackle the issue with clients, I find many people aren’t even aware it can happen at all. And since it involves a site’s robots.txt file, it can potentially have a big impact SEO-wise.
I’m referring to robots.txt files being handled by subdomain and protocol. In other words, a site could have multiple robots.txt files running at the same time located at www and non-www, or by protocol at https www and http www. And since Google handles each of those separately, you can be sending very different instructions about how the site should be crawled (or not crawled).
In this post, I’ll cover two real-world examples of sites that ran into the problem, I’ll cover Google’s robots.txt documentation, explain how to detect this is happening, and provide several tips along the way based on helping clients with this situation.
Let’s get crawling, I mean moving. :)
Robots.txt by subdomain and protocol
I just mentioned above that Google handles robots.txt files by subdomain and protocol. For example, a site can have one robots.txt file sitting on the non-www version, and a completely different one sitting on the www version. I have seen this happen several times over the years while helping clients and I just surfaced it again recently.
Beyond www and non-www, a site can have a robots.txt file sitting at the https version of a subdomain and then also at the http version of that subdomain. So, similar to what I explained above, there could be multiple robots.txt files with different instructions based on protocol.
Google’s documentation clearly explains how it handles robots.txt files and I recommend you read that document. Here are some examples they provide about how robots.txt instructions will be applied:
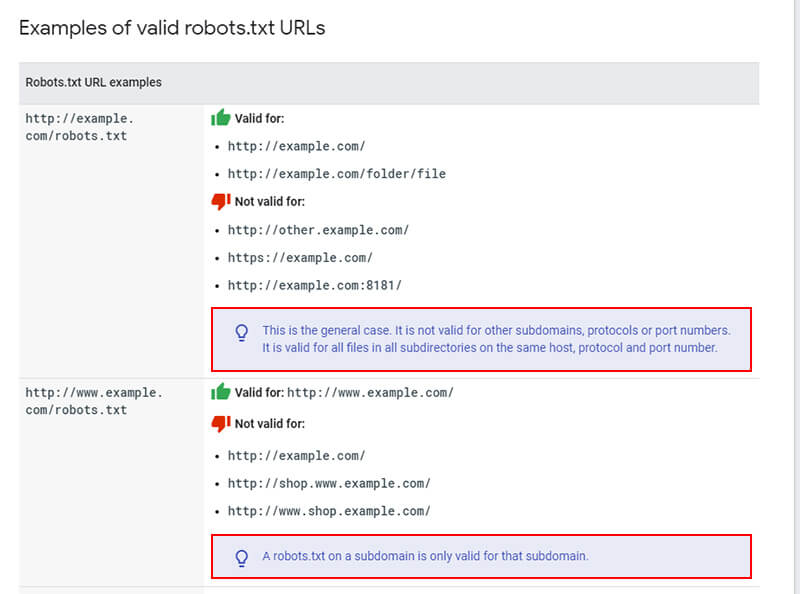
This can obviously cause problems as Googlebot might fetch different robots.txt files for the same site and crawl each version of the site in different ways. Googlebot can end up doing some interesting things while site owners incorrectly believe it’s following one set of instructions via their robots.txt file, when it’s also running into a second set of instructions during other crawls.
I’ll cover two cases below where I ran into this situation.
Case study #1: Different robots.txt files with conflicting directives on www and non-www
While performing a crawl analysis and audit recently on a publisher site, I noticed that some pages being blocked by robots.txt were actually being crawled and indexed. I know that Google 100% obeys robots.txt instructions for crawling so this was clearly a red flag.
And to clarify, I’m referring to URLs being crawled and indexed normally, even when the robots.txt instructions should be disallowing crawling. Google can still index URLs blocked by robots.txt without actually crawling them. I’ll cover more about that situation soon.
When checking the robots.txt file manually for the site, I saw one set of instructions on the non-www version which were limited. Then I started to manually check other versions of the site (by subdomain and protocol) to see if there were any issues.
And there it was, a different robots.txt file was sitting on the www version of the site. And as you can guess, it contained different instructions than the non-www version.
non-www version of the robots.txt file:
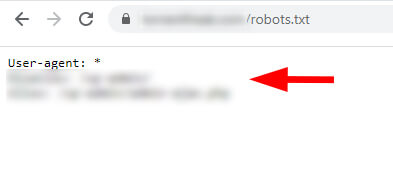
www version of the robots.txt file:
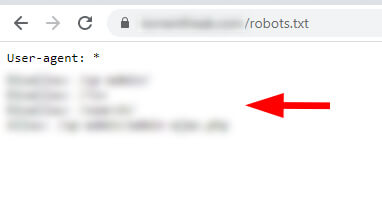
The site was not properly 301 redirecting the www version of the robots.txt file to the non-www version. Therefore, Google was able to access both robots.txt files and find two different sets of instructions for crawling. Again, I know that many site owners aren’t aware this can happen.
A quick note about pages blocked by robots.txt that can be indexed
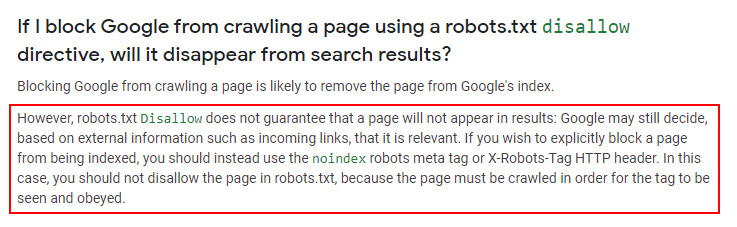
I mentioned earlier that pages properly blocked by robots.txt can still be indexed. They just won’t be crawled. Google has explained this many times and you can read more about how Google can index robotted URLs in its documentation about robots.txt. I know it’s a confusing subject for many site owners, but Google can definitely still index pages that are disallowed. For example, Google can do this when it sees inbound links pointing to those blocked pages.
When that happens, it will index the URLs and provide a message in the SERPs that says, “No information can be provided for this page”. Again, that’s not what I’m referring to in this post. I’m referring to URLs that are being crawled and indexed based on Google seeing multiple versions of a robots.txt file. Here is a screenshot from Google’s documentation about robotted URLs being indexed.
What about Google Search Console (GSC) and robots.txt files?
In a faraway region of Google Search Console, where search tumbleweeds blow in the dusty air, there’s a great tool for site owners to use when debugging robots.txt files. It’s called the robots.txt Tester and it’s one of my favorite tools in GSC. Unfortunately, it’s hard for many site owners to find. There are no links to it from the new GSC, and even the legacy reports section of GSC doesn’t link to it.
When using that tool, you can view previous robots.txt files that Google has seen. And as you can guess, I saw both robots.txt files there. So yes, Google was officially seeing the second robots.txt file.
robots.txt Tester in GSC showing one version:
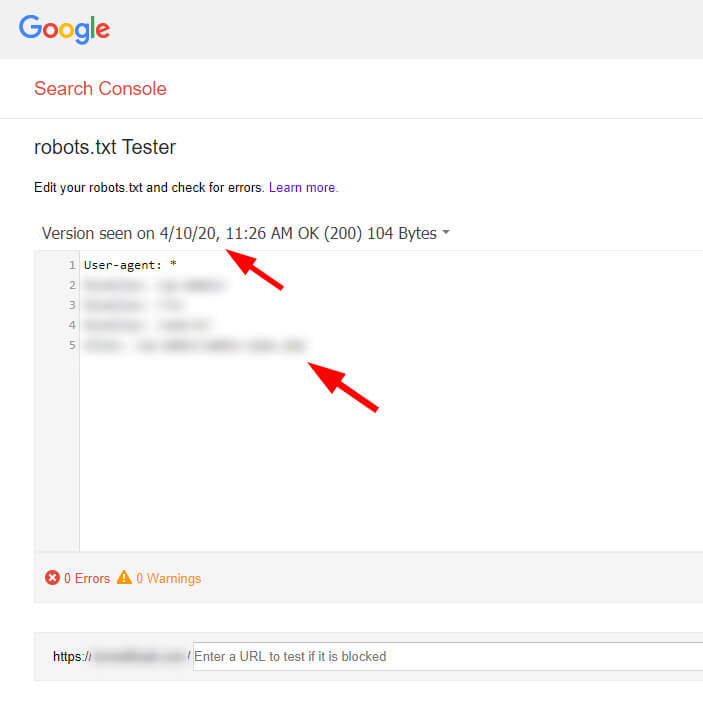
robots.txt Tester in GSC showing the second version:
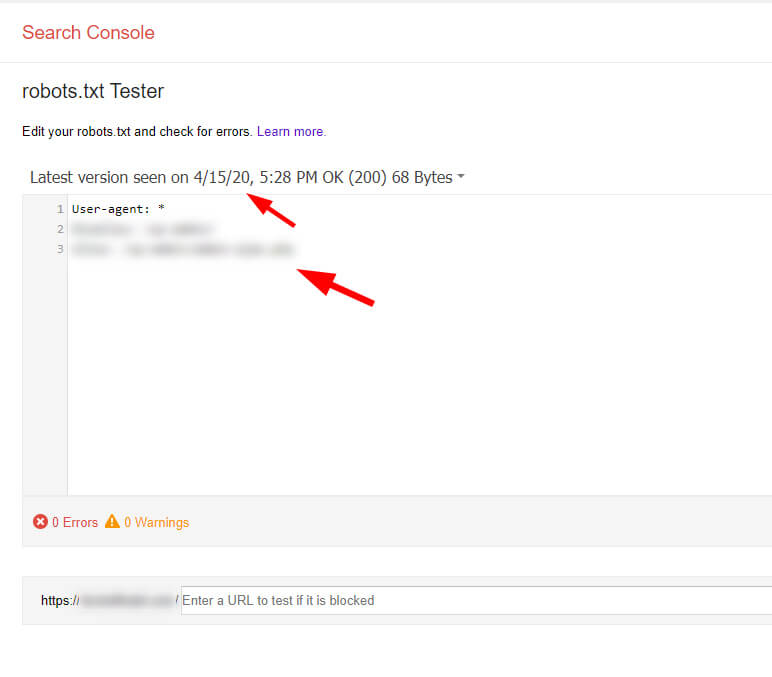
Needless to say, I quickly emailed my client with the information, screenshots, etc., and told them to remove the second robots.txt file and 301 redirect the www version to the non-www version. Now when Google visits the site and checks the robots.txt file, it will consistently see the correct set of instructions.
But remember, there are some URLs incorrectly indexed now. So, my client is opening those URLs up for crawling, but making sure the files are noindexed via the meta robots tag. Once we see that total come down in GSC, we’ll include the correct disallow instruction to block that area again.
Case study #2: Different robots.txt files for http and https and a blanket disallow
As a quick second example, a site owner contacted me a few years ago that was experiencing a drop in organic search traffic and had no idea why. After digging in, I decided to check the various versions of the site by protocol (including the robots.txt files for each version).
When attempting to check the https version of the robots.txt file, I first had to click through a security warning in Chrome. And once I did, there it was in all its glory… a second robots.txt file that was blocking the entire site from being crawled. There was a blanket disallow in the https version of the robots.txt file. For example, using Disallow: /
Note, there were a number of other things going on with the site beyond this issue, but having multiple robots.txt files, and one with a blanket disallow, was not optimal.
The https robots.txt file (hidden behind a security warning in Chrome):

Site health problems showing in GSC for the https property:

Fetching the https version shows it was blocked:
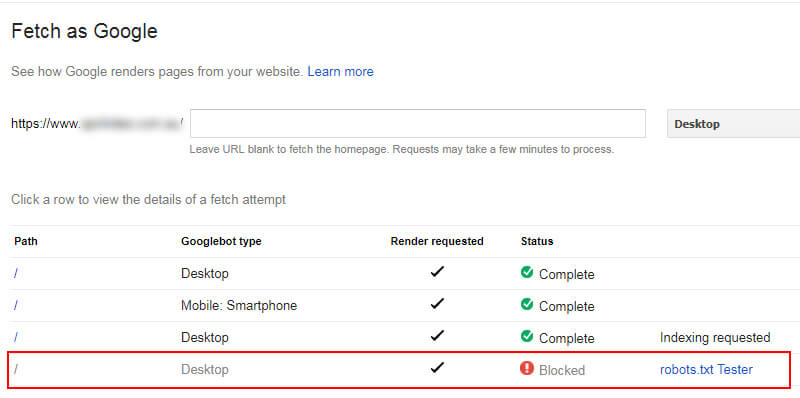
Similar to the first case, the site owner moved quickly to rectify the problem (which was no easy feat based on their CMS). But they eventually got their robots.txt situation in order. It’s another great example of how Google treats robots.txt files and the danger of having multiple files by subdomain or protocol.
Tools of the trade: How to detect multiple robots.txt files by subdomain or protocol
To dig into this situation, there are several tools that you can use beyond manually checking the robots.txt files per subdomain and protocol. The tools can also help surface the history of robots.txt files seen across a site.
Google’s robots.txt Tester
I mentioned the robots.txt Tester earlier and it’s a tool directly from Google. It enables you to view the current robots.txt file and previous versions that Google has picked up. It also acts as a sandbox where you can test new directives. It’s a great tool, even though Google is putting it in a distant corner of GSC for some reason.

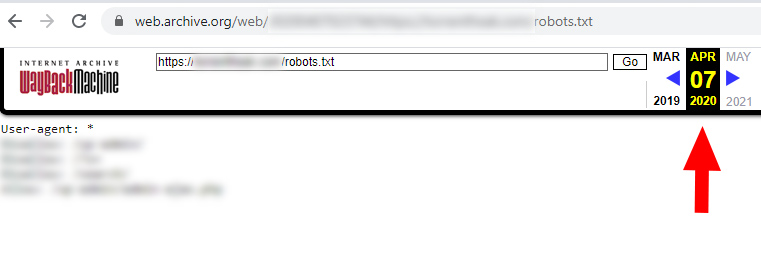
The wayback machine
Yes, the internet archive can help greatly with this situation. I’ve covered this in a previous column on Search Engine Land, but the wayback machine is not just for checking standard webpages. You can also use it to review robots.txt files over time. It’s a great way to track down previous robots.txt versions.
The fix: 301 redirects to the rescue
To avoid robots.txt problems by subdomain or protocol, I would make sure you 301 redirect your robots.txt file to the preferred version. For example, if your site runs at www, then redirect the non-www robots.txt to the www version. And you should already be redirecting http to https, but just make sure to redirect to the preferred protocol and subdomain version. For example, redirect to https www if that’s the preferred version of your site. And definitely make sure all URLs are properly redirected on the site to the preferred version.

For other subdomains, you might choose to have separate robots.txt files, which is totally fine. For example, you might have a forum located at the subdomain forums.domain.com and those instructions might be different from www. That’s not what I’m referring to in this post. I’m referring to www versus non-www and http versus https for your core website. Again, other subdomains could absolutely have their own robots.txt files.
Summary: For robots.txt files, watch subdomain and protocol
Since it controls crawling, it’s incredibly important to understand how Google handles robots.txt files. Unfortunately, some sites could be providing multiple robots.txt files with different instructions by subdomain or protocol. And depending on how Google crawls the site, it might find one, or the other, which can lead to some interesting issues with crawling and indexing. I would follow the instructions, pun intended, in this post to understand how your site is currently working. And then make sure you are sending the clearest directions possible to Googlebot for how to crawl your site.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
About the author