The first steps of your SEO audit: Indexing issues
Even a magic SEO wand will not get a web page to rank if the page has not been indexed. Contributor Janet Driscoll Miller suggests that making sure web pages can be indexed is key during an SEO audit.
 Indexing is really the first step in any SEO audit. Why?
Indexing is really the first step in any SEO audit. Why?
If your site is not being indexed, it is essentially unread by Google and Bing. And if the search engines can’t find and “read” it, no amount of magic or search engine optimization (SEO) will improve the ranking of your web pages.
In order to be ranked, a site must first be indexed.
Is your site being indexed?
There are many tools available to help you determine if a site is being indexed.
Indexing is, at its core, a page-level process. In other words, search engines read pages and treat them individually.
A quick way to check if a page is being indexed by Google is to use the site: operator with a Google search. Entering just the domain, as in my example below, will show you all of the pages Google has indexed for the domain. You can also enter a specific page URL to see if that individual page has been indexed.
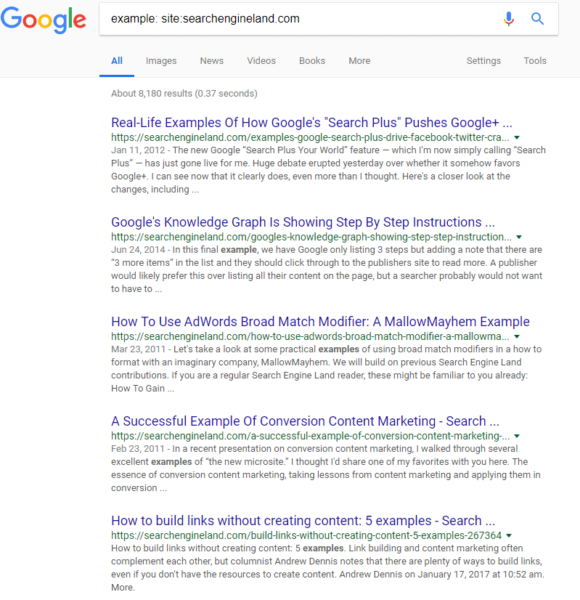
When a page is not indexed
If your site or page is not being indexed, the most common culprit is the meta robots tag being used on a page or the improper use of disallow in the robots.txt file.
Both the meta tag, which is on the page level, and the robots.txt file provide instructions to search engine indexing robots on how to treat content on your page or website.
The difference is that the robots meta tag appears on an individual page, while the robots.txt file provides instructions for the site as a whole. On the robots.txt file, however, you can single out pages or directories and how the robots should treat these areas while indexing. Let’s examine how to use each.
Robots.txt
If you’re not sure if your site uses a robots.txt file, there’s an easy way to check. Simply enter your domain in a browser followed by /robots.txt.
Here is an example using Amazon (https://www.amazon.com/robots.txt):

The list of “disallows” for Amazon goes on for quite awhile!
Google Search Console also has a convenient robots.txt Tester tool, helping you identify errors in your robots file. You can also test a page on the site using the bar at the bottom to see if your robots file in its current form is blocking Googlebot.

If a page or directory on the site is disallowed, it will appear after Disallow: in the robots file. As my example above shows, I have disallowed my landing page folder (/lp/) from indexing using my robots file. This prevents any pages residing in that directory from being indexed by search engines.
There are many cool and complex options where you can employ the robots file. Google’s Developers site has a great rundown of all of the ways you can use the robots.txt file. Here are a few:

Robots meta tag
The robots meta tag is placed in the header of a page. Typically, there is no need to use both the robots meta tag and the robots.txt to disallow indexing of a particular page.
In the Search Console image above, I don’t need to add the robots meta tag to all of my landing pages in the landing page folder (/lp/) to prevent Google from indexing them since I have disallowed the folder from indexing using the robots.txt file.
However, the robots meta tag does have other functions as well.
For example, you can tell search engines that links on the entire page should not be followed for search engine optimization purposes. That could come in handy in certain situations, like on press release pages.
![]()
Probably the two directives used most often for SEO with this tag are noindex/index and nofollow/follow:
- Index follow. Implied by default. Search engine indexing robots should index the information on this page. Search engine indexing robots should follow links on this page.
- Noindex nofollow. Search engine indexing robots should NOT index the information on this page. Search engine indexing robots should NOT follow links on this page.
The Google Developer’s site also has a thorough explanation of uses of the robots meta tag.

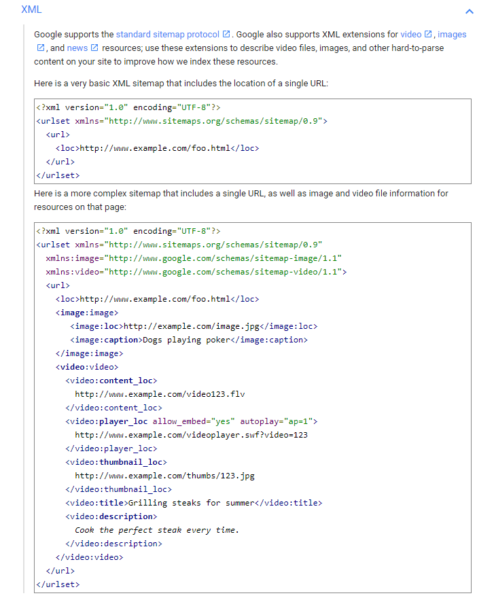
XML sitemaps
When you have a new page on your site, ideally you want search engines to find and index it quickly. One way to aid in that effort is to use an eXtensible markup language (XML) sitemap and register it with the search engines.
XML sitemaps provide search engines with a listing of pages on your website. This is especially helpful when you have new content that likely doesn’t have many inbound links pointing to it yet, making it tougher for search engine robots to follow a link to find that content. Many content management systems now have XML sitemap capability built in or available via a plugin, like the Yoast SEO Plugin for WordPress.
Make sure you have an XML sitemap and that it is registered with Google Search Console and Bing Webmaster Tools. This ensures that Google and Bing know where the sitemap is located and can continually come back to index it.
How quickly can new content be indexed using this method? I once did a test and found my new content had been indexed by Google in only eight seconds — and that was the time it took me to change browser tabs and perform the site: operator command. So it’s very quick!
JavaScript
In 2011, Google announced it was able to execute JavaScript and index certain dynamic elements. However, Google isn’t always able to execute and index all JavaScript. In Google Search Console, the Fetch and Render tool can help you determine if Google’s robot, Googlebot, is actually able to see your content in JavaScript.
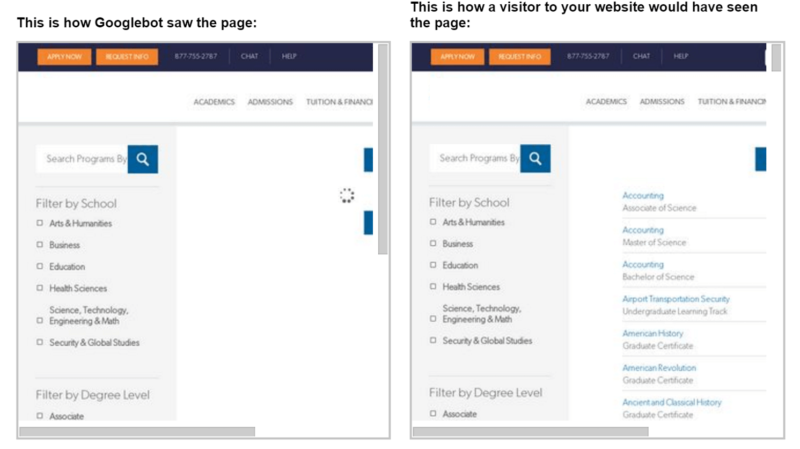
In this example, the university website is using asynchronous JavaScript and XML (AJAX), which is a form of JavaScript, to generate a course subject menu that links to specific areas of study.
The Fetch and Render tool shows us that Googlebot is unable to see the content and links the same way humans will. This means that Googlebot cannot follow the links in the JavaScript to these deeper course pages on the site.
Conclusion
Always keep in mind your site has to be indexed in order to be ranked. If search engines can’t find or read your content, how can they evaluate and rank it? So be sure to prioritize checking your site’s indexability when you’re performing an SEO audit.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author