Chapter 3: Site Architecture & Search Engine Success Factors

The next major on-page group in the Periodic Table of SEO Factors is site architecture. It plays a critical role in SEO effectiveness. These factors affect the findability and usability of your site.
Good architecture makes content easier for search engines and users to access and navigate. Take the following architectural factors into account as you develop or evaluate your site.
Cr: Crawl
Search engines use web crawling software — Google’s is called Googlebot and Bing’s is called Bingbot — to read your site’s pages and compile copies of them within a searchable index.
When searchers enter a query, the search engine scans its index to filter and rank the relevant pages. If your site isn’t crawlable, it’s not going to get included in the index and therefore won’t be visible in the search results.
Most sites don’t encounter serious crawling issues; however, you should still be aware of the factors that can facilitate or hinder this process.
Improper internal linking, slow page load speeds, URL errors, user access prompts, blocking search engines with the noindex value and showing web crawlers something different from what you’re showing users can all inadvertently prevent your site from surfacing in the search results.
[Pro Tip]
“An effective information architecture and corresponding navigation system actually make web search results and site search results more accurate.” – Shari Thurow, author and founder and SEO Director at Omni Marketing Interactive.
Now that Googlebot supports Chrome 74, more JavaScript apps can get crawled by Google. But, Detlef Johnson, the SEO for Developers expert at Search Engine Land, points out, “The Chromium update to the Googlebot only is relevant for Google. There are other search engines that you want to perform well on, and the future may turn the tables on Google at any point, like the times turned the tables on AltaVista when Google came around.”
“In terms of crawlability, even while Google can now crawl JavaScript links, you’re still better off just adhering as closely as possible to plain HTML for the most important code for your website, which includes, of course, navigation, so the crawlers can discover all your pages,” he says.
Conversely, there are measures you can take to make the most out of your “crawl budget” (the amount of resources a search engine will spend crawling your pages).
Making use of robots.txt, telling search engines not to crawl pages with certain URL parameters and verifying that all your links work properly can help improve crawl efficiency. Keeping clean, up-to-date HTML and XML sitemaps can also make it easier for search engines to crawl your site.
Mo: Mobile
Mobile-friendly doesn’t just mean that your site is viewable on phones and tablets, it means that your site is built for the humans that own those devices — and they should be able to access everything desktop users can access.
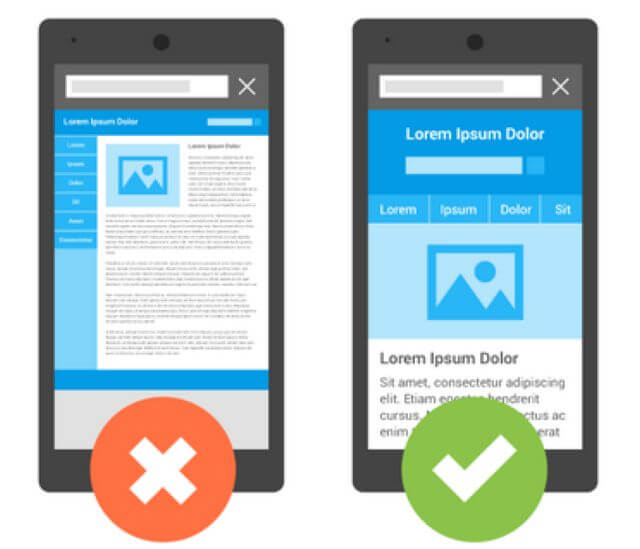
The majority of searches originate from mobile devices, and search engines have adjusted the way they index to respond to this trend. In March, 2018, Google began broadly implementing mobile-first indexing, in which it uses the mobile version of the web as its primary search engine index.
Many CMS’ support mobile versions of websites, but simply having a mobile site isn’t enough: take care to avoid common mistakes including, but not limited to, faulty redirects, slow loading speeds, inappropriate font sizes, touch elements being too close together and interstitials that impede users from accessing what they came for. Many of those considerations factor into your user experience, which is essential to mobile-friendliness.
Some publishers also offer a mobile app. If that includes your brand, make use of app indexing and linking to enable users to click on your search result and view the content in-app. Google’s Accelerated Mobile Pages (AMP) can also be implemented to swiftly deliver your content to mobile users.
For more, on making your site more mobile friendly see:
Dd: Duplicate
“Duplicate content is everywhere,” Patrick Stox, SEO specialist at IBM, pointed out during an Insights talk at SMX Advanced. You only want one version of a page to be available to search engines.This is where canocialization comes in.
If left unchecked, duplicate content may make it more difficult for search engines to figure out which page it should return for a query. It can also lead to people link to different versions of the same page.
That dilutes the value of those links — a measure of trust and authority — and paints an inaccurate picture of how valuable and relevant a page may actually be to searchers.
“In Google’s mind, they’re trying to help people by folding the pages together,” said Stox, explaining what search algorithms are likely to do when they encounter duplicate content. “All these various versions become one. All the signals consolidate to that one page. They’re actually trying to help us by doing that.”
It may be of comfort to know that search engines try to figure out canonicals for you, but when your client or your own brand’s success depends on optimizing for search, using canonicals tags, redirects and effective pagination strategies may offer a more precise degree of control as well as a more fluid user experience.
“No matter what, Google will try to figure it out for you,” says Search Engine Land News Editor Barry Schwartz, adding, “The question is, do you want Google to figure it out for you or not? Or, do you want to control what Google defines as your canonical URL?”
For more, see our SEO: Duplicate Content section.
Sp: Speed
Optimizing for site speed “will never go to a point where you just have a score that you optimize for and be done with it,” Google Webmaster Trends Analyst Martin Splitt said last year.
Your site should load quickly whether visitors are viewing it on mobile or desktop. And, since speed is a Google ranking factor, faster sites will have an SEO advantage (all other factors being equal).
A few months after Google’s broad rollout of mobile-first indexing in 2018, it launched the “Speed Update” for mobile search.
Like many other SEO factors, speed is intertwined with the user experience. Maintaining a zippy site may help prevent visitors from bouncing and improve your engagement and conversion rates. Use tools such as Google’s PageSpeed Insights to identify areas of your site to improve.
For more, see our SEO: Site Speed section to stay up-to-date.
Ps: HTTPS
Google has pushed websites to migrate to HTTPS servers in order to provide better security to searchers. It’s forced the issue in a couple of ways, including rankings.
In 2014, Google started giving a small ranking boost to secure HTTPS/SSL sites. In July, 2018, the Chrome browser began marking pages that don’t use HTTPS as not secure, effectively making HTTPS part of a user’s experience on your site.

“Google will typically index HTTPS first over HTTP,” Patrick Stox explained at SMX Advanced. “So, if you have both and you don’t have a canonical . . . typically, they’re going to choose HTTPS when they can.”
“Using HTTPS is mostly a user experience issue,” Detlef Johnson adds. “However, that user experience issue is important because people who might want to conduct e-commerce with your site — if they’re faced with security warnings, you may have just lost the sale.”
[Pro Tip]
“One thing that I see a lot actually — and this is true mostly for WordPress — there are assets that were uploaded into the content management system, before the site owner switched over to HTTPS, and so a lot of the images that might be a part of layout or part of older posts are hosted with spellings that are for previous, ordinary HTTP. Even though those assets might resolve and you might get them to display on the page, served over HTTPS, you’ll still get a warning that says some assets of this page are not secure, which is similar to ‘Uh-oh, you’ve got insecure pages.'”– Detlef Johnson, Search Engine Land
Ur: URLs
This is not a major ranking factor, but it’s good practice to use descriptive words in your page URLs for search engines and users.
Your URLs appear on search results pages, so having an easy-to-understand URL may give searchers a better idea of what’s on the other end of the link.
Here are some tips to help you create a URL structure that’s easy to understand for humans and search engines.
✅Do ✅ | ????Avoid ???? |
|---|---|
Include keywords within your URL. Use hyphens to separate words (as in the example above). | Stuffing keywords numerous times in your URL. Remember, having a domain match for a given query does not guarantee that you’ll show up at the top of the search results. |
Name your pages using words that describe your content. | Using incomprehensible strings of characters and numbers in your page addresses. |
Make use of directories to organize your pages. Directories can describe your content as well as your site’s structure. | For evergreen content, avoid including a date within your URL. |
SEO Guide chapters: Home – 1: Factors – 2: Content – 3: Architecture – 4: HTML – 5: Trust – 6: Links – 7: User – 8: Toxins – 9: Emerging
New on Search Engine Land