A Layman’s Visual Guide To Google’s Knowledge Graph Search API
Columnist Barbara Starr delves into the recently released Knowledge Graph Search API and discusses how SEOs might use this data.

Google released their much-delayed Knowledge Graph Search API on December 16, 2015, which was announced in a post on Google Plus by Freebase. (They did so after retiring Freebase, to support users of the Freebase API.)
The Knowledge Graph Search API allows users to query Google’s Knowledge Graph database to obtain information on the entities contained therein. According to Google, some typical use cases include:
• Getting a ranked list of the most notable entities that match certain criteria.
• Predictively completing entities in a search box.
• Annotating/organizing content using the Knowledge Graph entities.
An illustrated guide is provided below to enable anyone to access this API so its query capabilities can be leveraged and utilized without the need for any programming language skills. The only prerequisite is that you must have a Google account.
The Knowledge Graph Search API: Getting Started
The Knowledge Graph Search API can be found within Google’s APIs Explorer, shown below:
Google’s APIs Explorer,”Knowledge” highlighted [Click to enlarge]

[Click to enlarge]
Click the entry above, which will take you here. You may find it helpful to bookmark this link, as it will typically be your starting point.
The Knowledge Graph Search API: Input GUI
You now have a screen with a graphical user interface (GUI) that contains all the parameters contained in the Knowledge Graph API (the details of which you can find here in their developer guide on the topic).

Explorer GUI for the Google Knowledge graph search API [Click to enlarge]
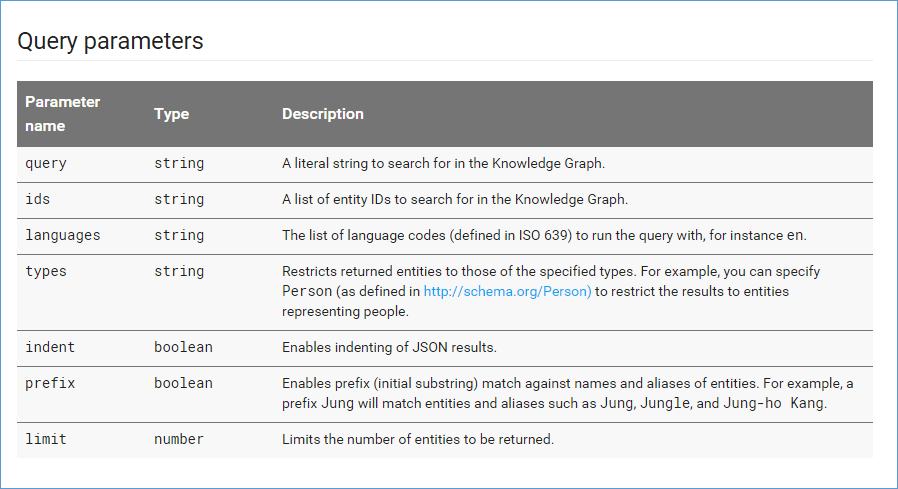
Query Parameters: Knowledge Graph Search API
So let’s look at a few things we can do with this API and see what sort of results we get.
As stated in the developer guide, the API does not return “graphs of interconnected entities,” merely the entities being searched for (with almost no associated attributes or predicates).
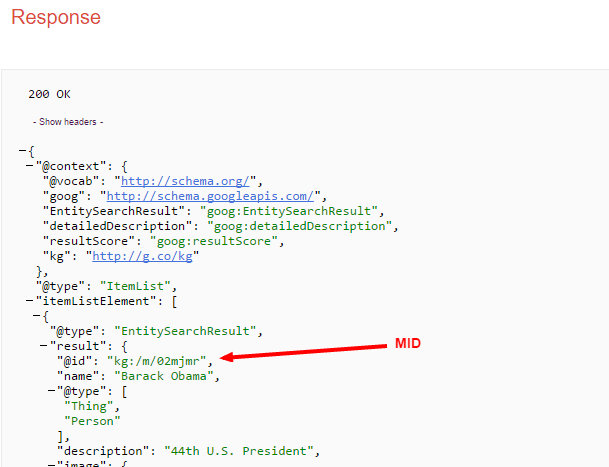
The “ids” field refers to the machine-generated identifier (MID), which is key to understanding concepts in both Freebase and the Google Knowledge Graph. A MID is, as per the Freebase wiki, a unique identifier for an entity. It just so happens that Google appears to leverage them and be dependent upon them in some aspects.
This means that it is important to be able to understand and recognize them. Luckily, it is easy to determine what a freebase MID looks like. They typically start with “/m/” and then some very short appended string (e.g., The MID for “Barack Obama” is /m/02mjmr/).
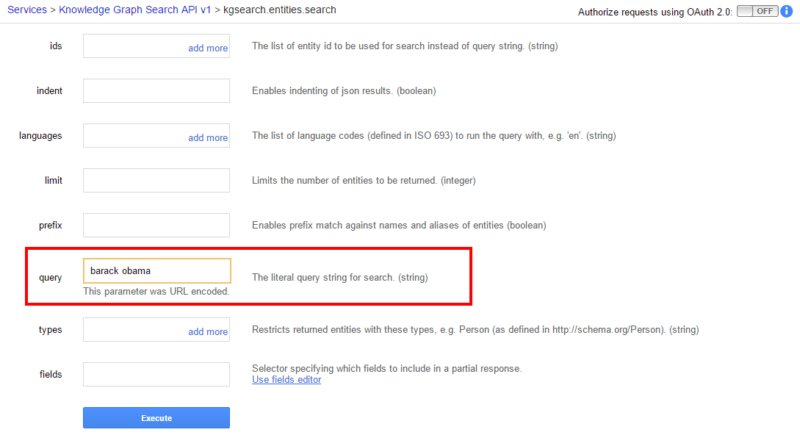
An easy way to now obtain a MID for any entity is now just to enter it into the “query” field in Knowledge Graph Search API.
You can also find MIDs in Google Trends. When you select an entity from the autosuggest list that appears as you begin to type in a query, the resulting URL will contain the MID:

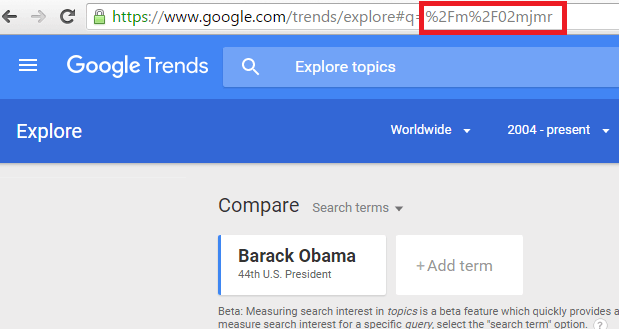
Of interest is that Google still uses MIDs as identifiers here, and not the Qids that Wikidata uses, although there are published mappings from the one to the other. In some regards, you can think of the MIDs as akin to the notion of a “primary database key” for the Knowledge Graph.
(Editor’s note: Contributor Clay Cazier recently wrote a great introduction to Wikidata.)
The Knowledge Graph Search API: Output Fields
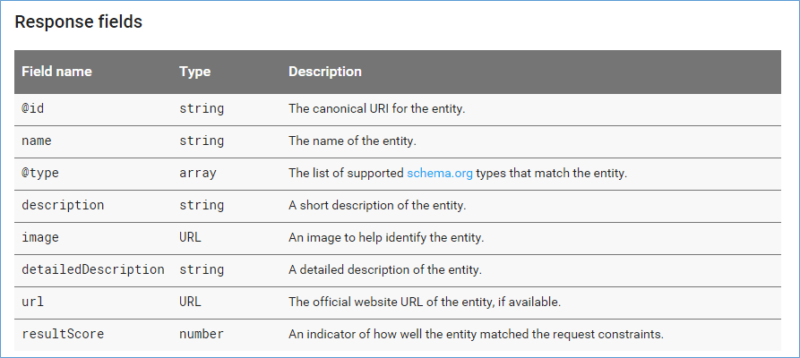
Response Fields: Knowledge Graph Search API
Looking at the above, you can see definitions for precisely what is returned in the “Response” area when you execute a request using the Knowledge Graph Search API.
As stated in the specs, a response message contains a list of entities, presented in JSON-LD format and compatible with schema.org schemas (with limited external extensions). Samples of the output are illustrated and interpreted in the Examples section below.
Contrary to my initial intuitive thoughts, querying the API and restricting output to the type “Person” does not provide the full Person Entity with all the associated attributes of that person, but rather just those items listed in the figure above. (It always helps to read documentation prior to playing with data; however, sometimes it is more fun to just start playing with the data. Google does state that if you want a richer, graph-based response, you can move over to Wikidata and obtain the information from that source instead.)
The API does return the MID used by Google, which is useful when applying semantic markup and adding identifiers to fully disambiguate your content, as described here. With Freebase retiring, this may now be the best way to obtain those identifiers. Adding identifiers is probably generally best done in the last stages of applying semantic markup and is very helpful to the search engines in terms of disambiguating your content.
Another interesting field that’s worthy of note is the resultScore, which is defined as “[a]n indicator of how well the entity matched the request constraints.” (It is likely it may be a type of entity metric, as I described in a previous article.)
Examples
Playing with various inputs and looking at the results can provide some interesting insights. I am going to walk through two queries here and see what we can glean from the results.
In the first query, I entered the Query term “President of the United States,” and for the type, I put “Person.” (Types are derived from schema.org, in this case, schema.org/Person.)
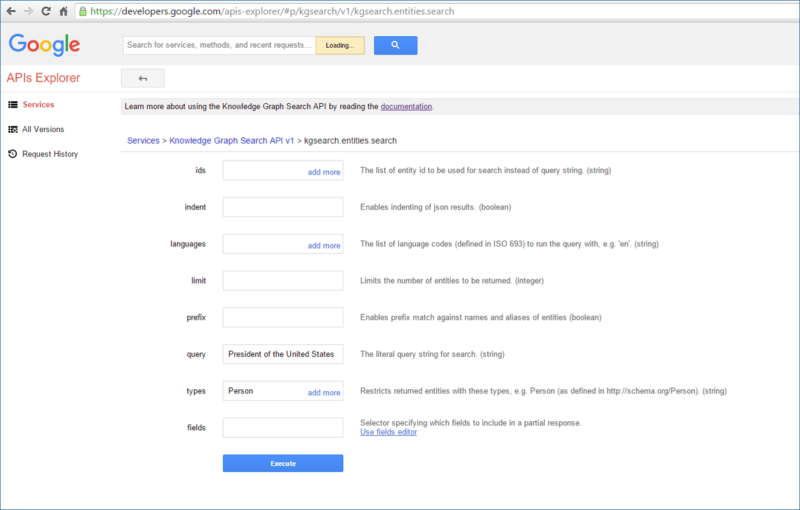
Query: “President of the United States”/Type: “Person”
I then clicked the “Execute” button. This query yields a long output (JSON-LD can tend to be rather verbose). For the purposes of this article, I merely showed the first result page in the figure below. This also provides an example of what to expect in terms of the response format.
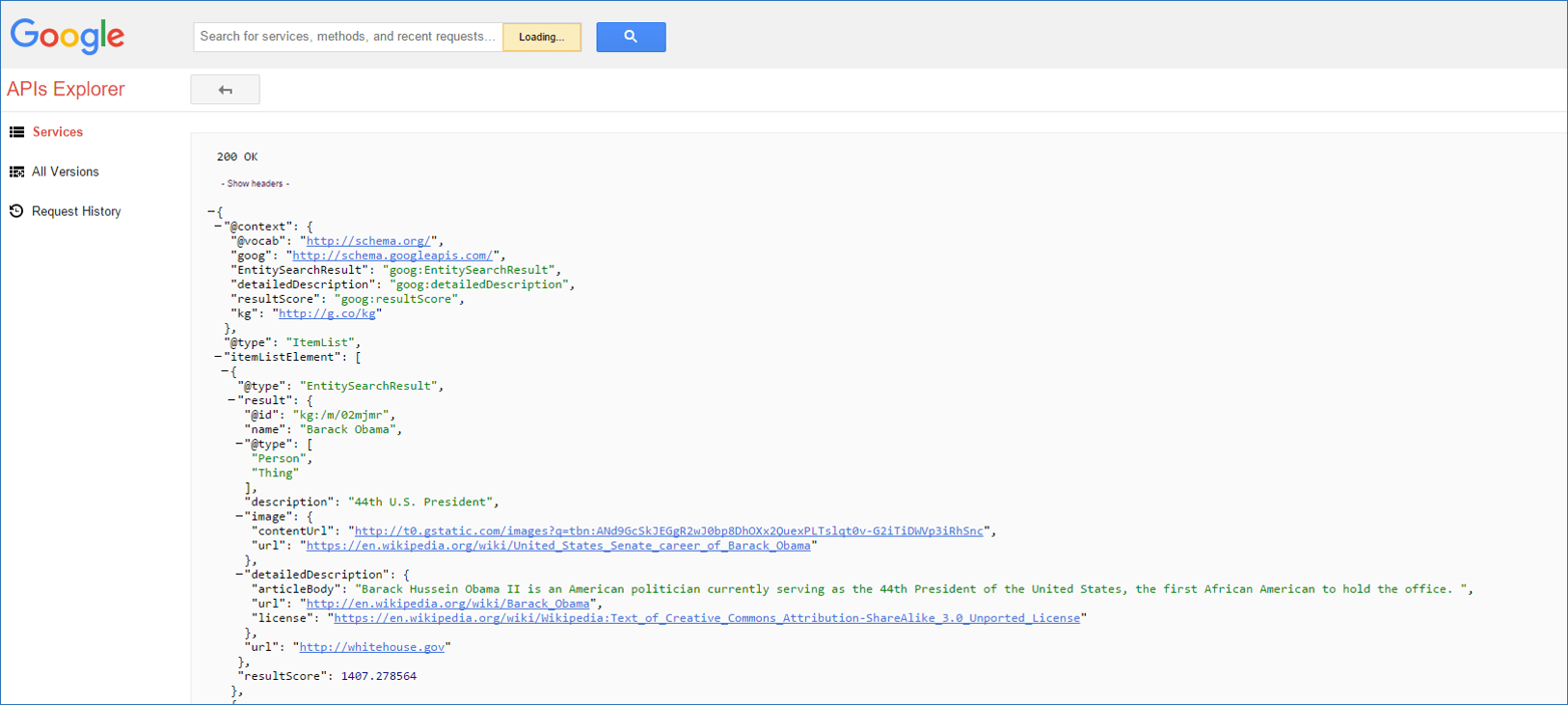
Results from Query 1: “President of the United States” — Barack Obama comes in first with a resultScore of 1407.[Click to enlarge]
The next query I elected to run — “Presidents of the United States” — was similar but instead included the plural form of the term “president” (which would imply I received a list of results, rather than a specific answer).
Running that seemingly similar query in place of the previous term yielded similar results, yet the resultScore for the number 1 entity in the Response was now 251.
The results are illustrated in the diagram below. (In addition, in the image, you can also see the query itself, in the “GET http:” line, before you see the response with the 200 – “OK” – code.)
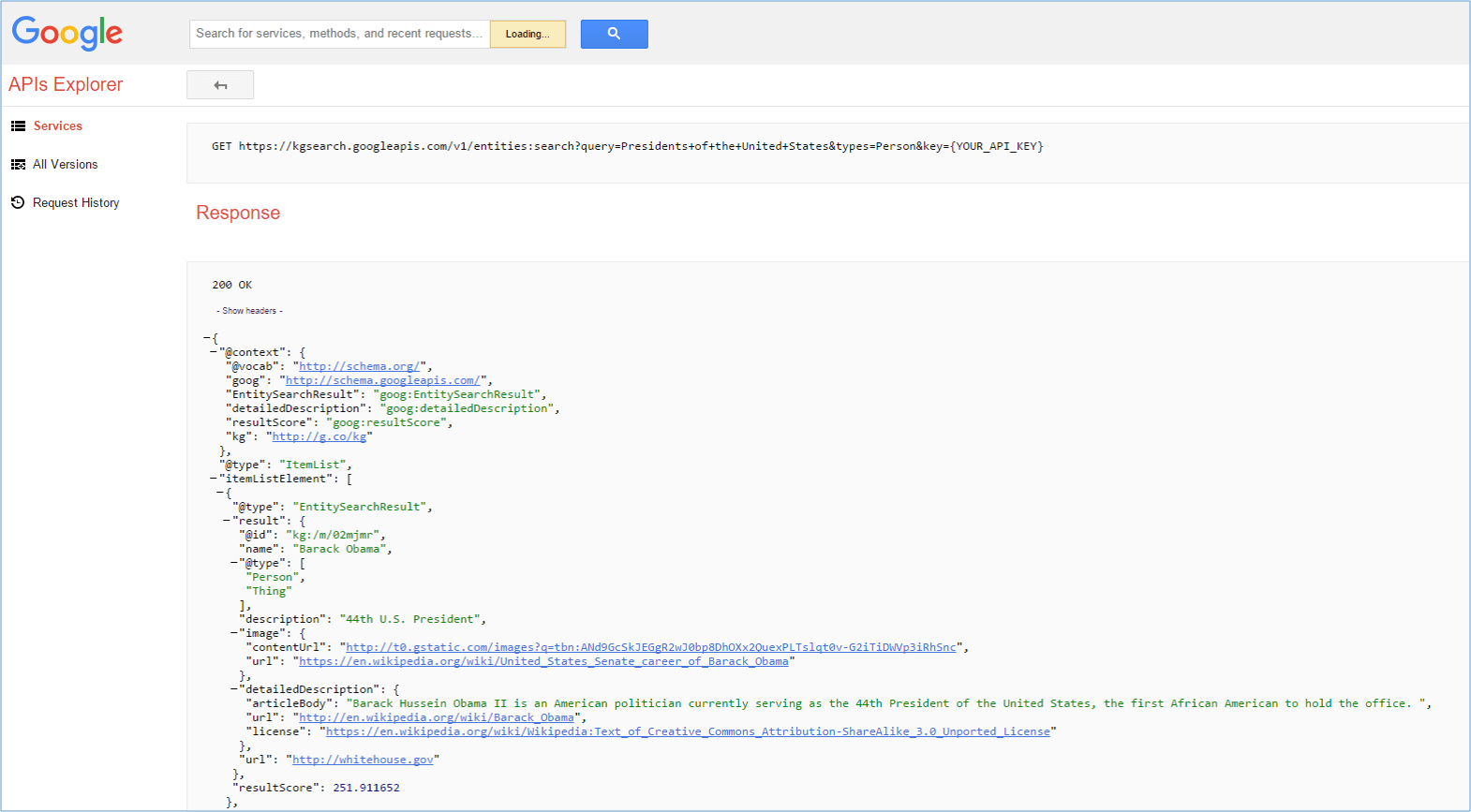
Results from Query 2: “Presidents of the United States”/Type-restricted to “schema.org/Person” [Click to enlarge]
Visualization Of The Result Data From Query Number 1 In A Triple Store
For the next helpful visualization, I decided to take the output and load it into Gruff, which is the graph-based visualization tool from Franz Inc. (You can download a copy for free.)
I also used Greg Kellogg’s RDF distiller to convert the results from JSON-LD to triple format before I loaded it. I then selected the first result and created the visualization below.
The visualization definitely helps in understanding how “things” are linked together.
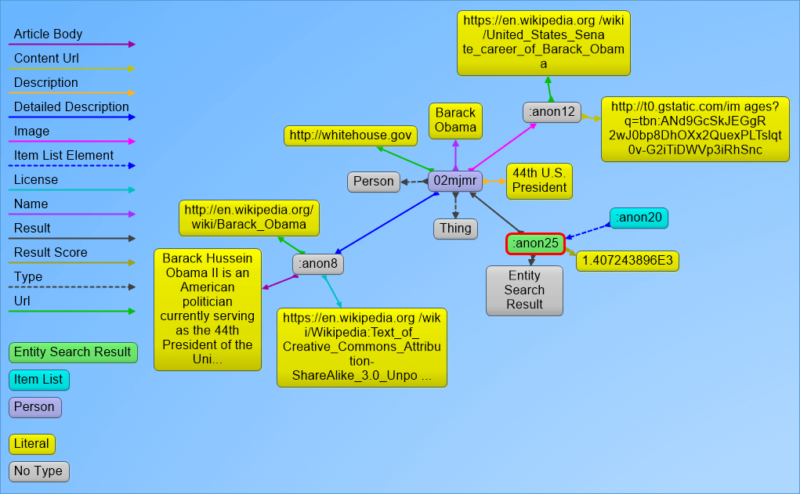
Visualization of the first Entity Search Result in Gruff
Conclusion And Takeaways
Google’s announcement last week that they now support JSON-LD for rich snippets for products and reviews, coupled with the fact that Knowledge Graph search results are only returned in JSON-LD format, provides a strong inkling that providing semantic markup in JSON-LD format is a worthwhile approach for SEOs to adopt.
Using this format for structured data markup means that there is no longer a need to place markup that is correctly wrapped around the appropriate HTML elements — JSON-LD markup can be placed in the header or footer of the page, which radically simplifies things.
Adding identifiers as the last step of the process, in terms of adding semantic markup to a page, and hence aligning your page entities with those in Google’s Knowledge Graph, is a “must.” Obtaining those identifiers is now a simple matter of looking them up in Google’s Knowledge Graph Search API, as I have described above.
In addition, there is a lot of relevant and must-read coverage on the Knowledge Graph Search API that I did not cover, which you can find here.
Also ensure you adhere to all of the structured data policies specified by Google. There are many details that have changed, and the policies continue to evolve.
Helpful Resources
- Semantic Search Marketing Group: https://plus.google.com/communities/103048251221048356778
- Structured Data Linter: https://linter.structured-data.org/
- Knowledge Graph Search API: https://developers.google.com/apis-explorer/#p/kgsearch/v1/kgsearch.entities.search
- Google’s structured data testing tool: https://developers.google.com/structured-data/testing-tool/
- Google’s Structured Data Policies: https://developers.google.com/structured-data/policies
- Gruff Free download: https://franz.com/agraph/gruff/
- RDF Distiller by Gregg Kellogg: https://rdf.greggkellogg.net/distiller
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author