Don’t underestimate the power of advanced filtering when analyzing crawl data
Columnist Glenn Gabe shares various ways of filtering crawl data to obtain actionable insights.

While helping clients deal with major algorithm updates, troubleshoot technical SEO problems and more, I’m often auditing large-scale sites. That almost always requires a thorough site crawl (typically several crawls over the life of an engagement). And when you’re hunting down SEO gremlins that can be wreaking havoc on a site, it’s extremely important to slice and dice that crawl data in order to focus your analysis.
With good data filtering, you can often surface page types, sections or subdomains that might be causing serious problems. Once surfaced, you can heavily analyze those areas to better understand the core issues and then address what needs to be fixed.
From a crawler perspective, I’ve already covered two of my favorites here on Search Engine Land, DeepCrawl and Screaming Frog. Both are excellent tools, and I typically use DeepCrawl for enterprise crawls while using Screaming Frog for surgical crawls, which are more focused. (Note: I’m on the customer advisory board for DeepCrawl.) In my opinion, the combination of using DeepCrawl and Screaming Frog is killer, and I often say that 1 + 1 = 3 when using both tools together.
Below, I’ll cover several examples of using filtering in both tools so you can get a feel for what I’m referring to. By filtering crawl data, you’ll be ready to isolate and surface specific areas of a site for further analysis. And after you start doing this, you’ll never look back. Let’s rock and roll.
Examples of filtering in DeepCrawl
Indexable pages
Let’s start with a basic, yet important filter. Content quality issues can be extremely problematic on several levels, and you definitely want to make sure those problems are not present on indexable pages. When Google evaluates a site from a quality perspective, it takes your entire site into account. That includes every page that’s indexed. Here is a video from John Mueller explaining that.
So, as you surface problems on the site, it’s great to filter that list by indexable URLs in order to focus your analysis on pages that can be hurting your site quality-wise. And I’m not saying to ignore the other URLs because they aren’t being indexed! You should absolutely take care of them, too. Remember, users are interacting with those pages, and you don’t want unhappy users. It’s just smart to isolate pages that can be indexed when digging into content and/or other quality issues.

Thin content + regex for page type = awesome
For those of you who love regex, I have good news. DeepCrawl supports regular expressions for advanced filtering. So you could choose a filter and then select “Matches regex” or “Doesn’t match regex” to perform some surgical filtering. By the way, it’s awesome to have a “Doesn’t match regex” filter to start weeding out URLs you want to exclude versus include.
For example, let’s start simple by using pipe characters to combine three different directories in the filter. A pipe character represents “or” in a regular expression.
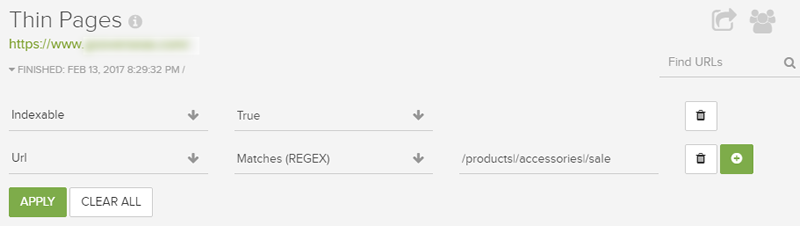
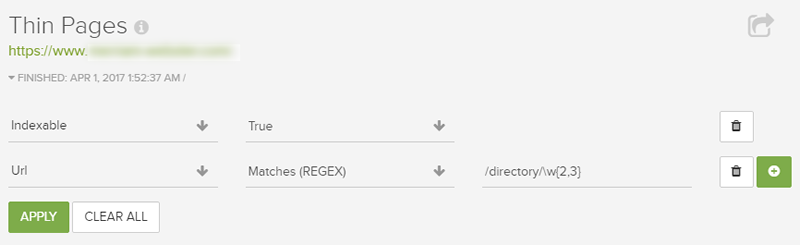
Or, how about excluding specific directories and then focusing on URLs that end with just two or three characters (which is an actual example of URLs I deemed to be problematic from a content standpoint during a particular audit):
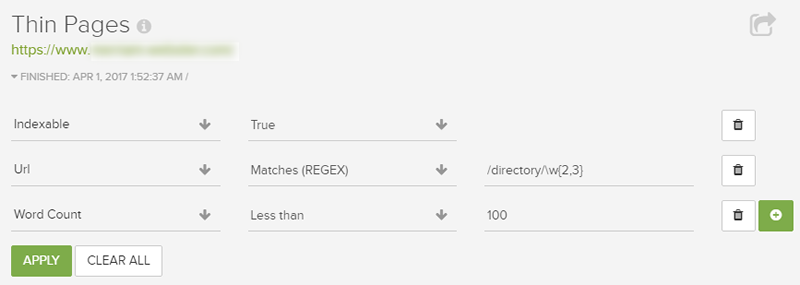
Or, how about mixing regex for page type with word count to identify really thin pages by page type or directory? This is why filtering is so powerful (and time-saving).
You get the picture. You can include or exclude any type of URLs or patterns you want. And you can layer on filters to hone your report. It’s amazing for focusing large-scale crawls.
Canonical problems: Response header
Last year I wrote a post about how to check the X-Robots-Tag to troubleshoot potentially dangerous robots directives (since they can be delivered via the header response and be invisible to the naked eye). On large-scale sites, this can be extremely sinister, as pages could incorrectly be noindexed when they look fine on the surface.
Well, you can set rel canonical via the header response, too. And that can lead to some strange problems (that can drive you crazy if you don’t know how rel canonical is being set.) And in some situations, you can end up with multiple canonical tags for one URL (one through the header response and one set in the html). When that happens, Google can ignore all canonical tags, as explained in their blog post about common mistakes with rel canonical.
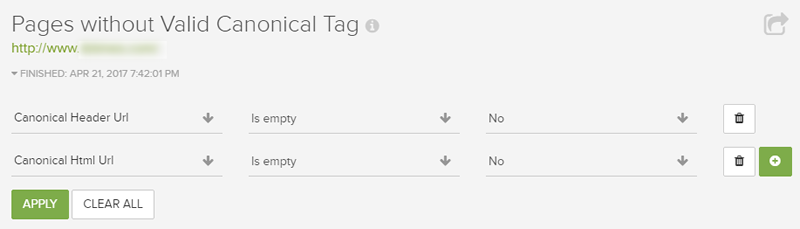
By checking the “Pages Without Valid Canonical Tag” report, and then filtering by both rel canonical header URL and rel canonical html URL, you can surface all URLs that have this problem. Then you can dig in with your dev team to determine why that’s happening code-wise.
Found at URL! Identifying the source of links to errors
You will undoubtedly come across crawl errors during a large-scale crawl (like 404s, 500s and others). Just knowing the URLs returning errors often isn’t good enough. You really need to track down where those URLs are being linked from across the site.
You want to fix problems at scale, and not just one-offs. To do this, filter by “found at” URLs from any of the crawl error reports (or from the non-200 report). Then you can use regex to surface page types and/or directories that might be heavily linking to pages that return crawl errors.

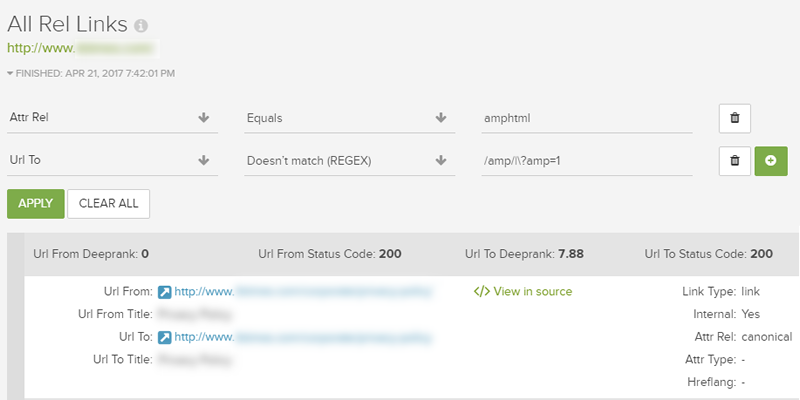
Double-check AMP URLs: All rel links
Using Accelerated Mobile Pages (AMP)? To double-check the URLs you are referencing via rel=amphtml in your html, you can check the “All rel links” report and filter by amphtml. Then you can apply another filter for “URL to” in order to make sure those are truly amp URLs you are referencing. Again, it’s just another quick example of how filtering can uncover sinister problems sitting below the surface.
Download filtered CSV
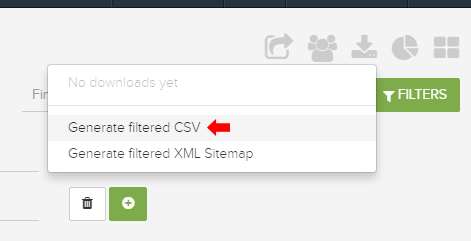
I provided several examples above of what you can do with advanced filtering when analyzing crawl data in DeepCrawl. But what about when you want to export that data? Since you did such a great job filtering, you definitely don’t want to lose the filtered data when exporting.
For that reason, DeepCrawl has a powerful option for “Generate Filtered CSV.” By using this feature, you can easily export just the filtered data versus the whole enchilada. Then you can further analyze in Excel or send to your team and/or clients. Awesome.
Filtering in Screaming Frog
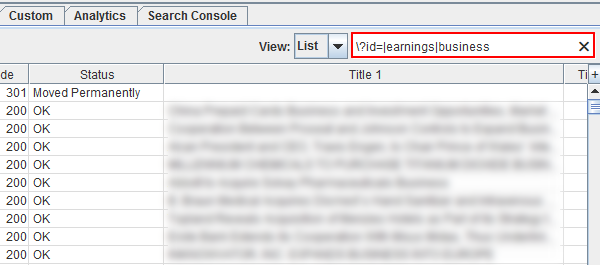
For Screaming Frog, the filters aren’t as robust, but you can still filter data right in the UI. Many people don’t know this, but regex is supported in the search box. So you can use any of the regular expressions you are using in DeepCrawl (or elsewhere) to filter URLs by report type right in Screaming Frog.
For example, checking response codes and want to quickly check those URLs by directory? Then use pipe characters to include specific page types or directories (or patterns). You’ll see the report change based on the regex.
And you can leverage the pre-filtered reports and then layer on your own filtering. For example, you can check pages with long titles and then filter using a regular expression to start surfacing specific page types or patterns.
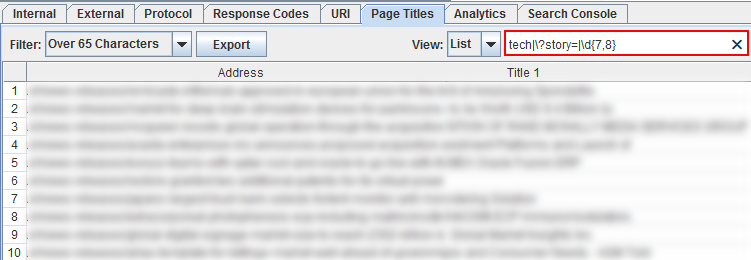
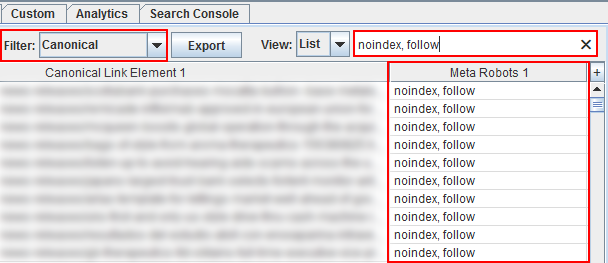
And the filter applies to all columns! So you can use regex for any of the columns listed in that specific report. For example, below I’m starting with all URLs that contain the canonical URL tag, and then I’m surfacing URLs that contain the meta robots tag using “noindex.”
If a URL is noindexed, then it shouldn’t contain the canonical URL tag (the two go against one another). Rel canonical tells the engines which is the preferred URL for indexing, while the meta robots tag using noindex tells the engines to not index the URL. That makes no sense. It’s a just a quick example of what you can do with filtering in Screaming Frog. Note: Screaming Frog has a “canonical errors” report, but this is a quick way to filter in the UI to surface problems.
From an export standpoint, you unfortunately can’t export just the filtered data. But you can quickly copy and paste the filtered data into Excel. And who knows, maybe the smart people over at Screaming Frog will build an “export filtered data” option.
Summary: It’s all in the filters
I spend a lot of time crawling sites and analyzing crawl data, and I can’t emphasize enough the power of filtering. And when you add regex support, you can really start slicing and dicing your data in order to surface potential problems. And the quicker you can surface problems, the quicker you can fix those problems. This is especially important for large-scale sites with tens of thousands, hundreds of thousands, or even millions of pages. So go ahead… filter away.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. Search Engine Land is owned by Semrush. Contributor was not asked to make any direct or indirect mentions of Semrush. The opinions they express are their own.


