Ready for Black Friday 2016? 3 critical e-commerce SEO configurations that help you avoid common issues
Columnist Aleyda Solis lays out critical tips for configuring your e-commerce website for SEO success this holiday season.

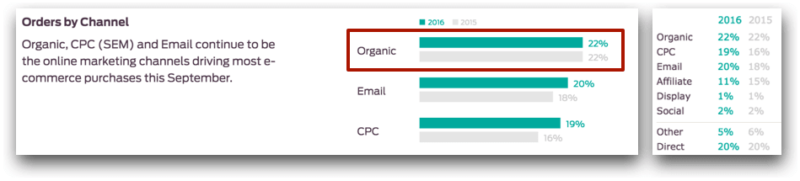
With the most important season for online retailers coming, it’s critical to make sure that your online store is optimized so you’re ready to make the most out of it. Last year, online shoppers spent $4.45 billion on Black Friday and Thanksgiving Day alone. And according to Custora’s E-Commerce Pulse, in September of this year, 22 percent of e-commerce orders in the US were driven by organic search traffic (vs. 20 percent coming from email and 19 percent from PPC):
Coincidentally, in Econsultancy’s Technology for Ecommerce Report 2015 (based on a survey of 600+ client-side and agency e-commerce professionals), “in-built SEO capabilities” was stated to be one of the most critical functionalities to be taken into consideration when selecting an e-commerce solution:

The reality is that although many e-commerce platforms come with SEO-related functionalities built in, these won’t be optimized by default.
These functionalities will help ease the optimization process, but they will need to be manually configured based on your site architecture, product characteristics and content needs to effectively target your users’ search behavior.
Here are three of the most fundamental SEO aspects to configure in your e-commerce platform:
1. Allow only the crawling of URLs that you want to index & rank to avoid crawl budget issues
Among others, there are two very common scenarios in e-commerce platforms that cause crawl budget problems:
- Generating more than one URL for the same page content. For example, perhaps you have the same product appearing within multiple product categories, so you end up having multiple URLs for each instance of the product page instead of just one. Due to this, you will need to no-index or canonicalize those additional URLs to the “original” product URL version to avoid having content duplication issues.
- Crawlable URLs by default for every existing filter in listing pages. For example, in categories listings, visitors may have the option to sort the existing list of products by criteria like size, color, popularity or pricing. This generates specific and crawlable URLs for every combination, most of them showing the same or very similar content, and they will need to end up being no-indexed.
For example, the following filtered listing URL is being canonicalized to the main one, without parameters:

Although this is good for avoiding content duplication or cannibalization issues, these URLs usually remain crawlable, which doesn’t help to solve crawl budget issues. It’s also important to prevent the crawling of these pages that are not meant to be indexed (or ranked); otherwise, we will end up having an scenario like this:
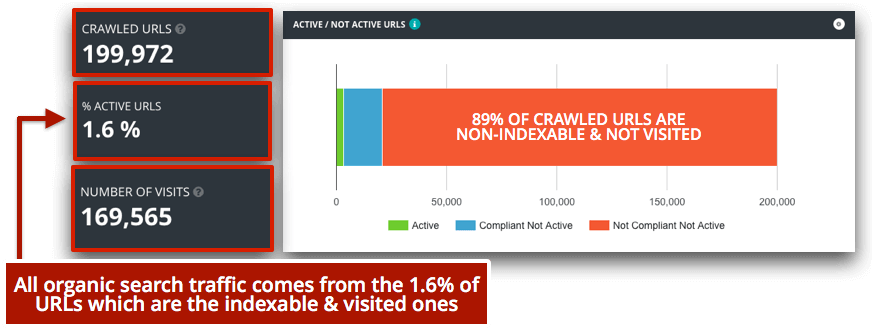
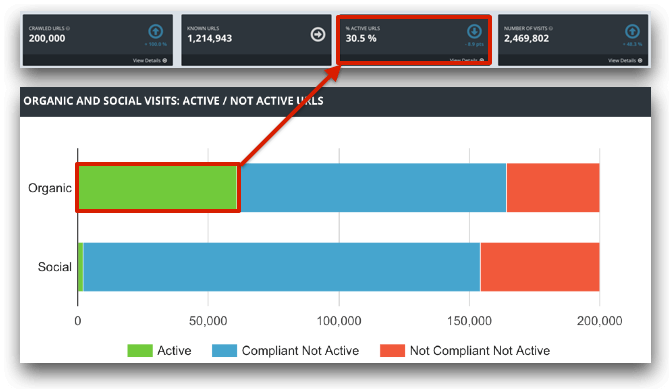
This e-commerce site has only 1.6 percent of active URLs bringing organic search traffic to the site, from a total of 200,000 crawlable ones. A non-trivial amount of crawled URLs are indexable (compliant) but are not bringing any organic search traffic. Worse, 89 percent of the crawled URLs are non-indexable and without organic search visits (“not compliant not active” in the graph above).
Most of these “not compliant not active” URLs are canonicalized or redirected to others, as can be seen in the graph below, and the ones that are “compliant” (indexable and meant to be ranked) are found very deep in the site architecture, making them harder to reach.

Another reason so many non-indexable pages are crawled is the automated generation of XML sitemaps by the platform itself, which might include all of the generated URLs (including those that are non-indexed, redirected, canonicalized to others) instead of only those which are meant to be indexed.
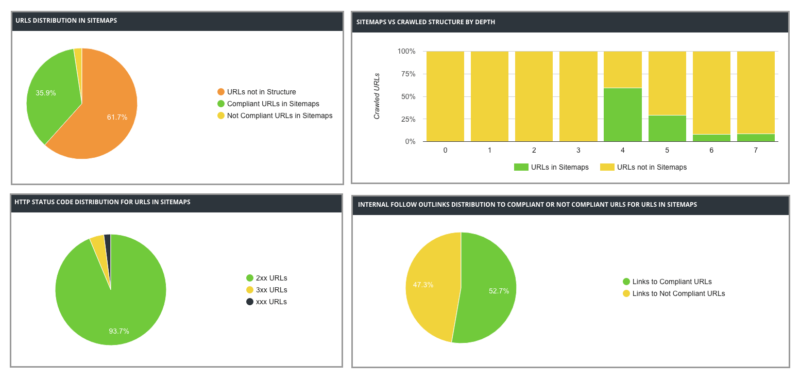
It’s then critical to configure the XML sitemaps in e-commerce platforms to only include the original URLs of each page — the ones that will be indexable and rankable, the ones we want our users to share, link to and arrive at. We will need to refresh these XML sitemaps as often as the content is updated.
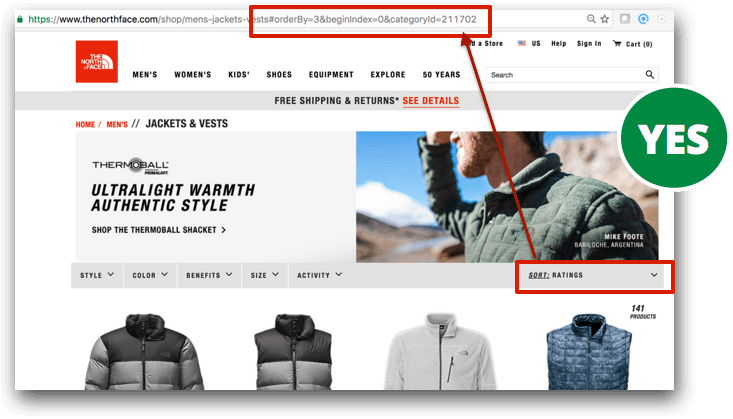
It’s also fundamental to only link to the original URL version of each page internally. If we still need to allow users to access non-indexable pages, like those generated by sorting filters, it’s then important to implement them in a way that they won’t be crawled. This can be achieved in many ways, like using hash (#) parameters instead of query (?) ones to generate these filtered URLs if possible.
The North Face does just that in this example for their listings sorting:
Another alternative is linking to these non-indexable or canonicalized filtered listings with a non-crawlable script, as in this example:

On the other hand, in order to provide a way for users to navigate through the different categories and levels of products in a relevant way — one that also prioritizes the accessibility of the original URLs that are meant to be indexed and ranked — it’s important to make sure that we always link up, sideways and down:
- Up to the main category levels of the site, as well as to the upper hierarchical levels of where we are with a breadcrumb.
- Sideways to related and sister product lines or subcategories of the current category level.
- Down to the next level of product segmentation, more granular sub-categories or filters of the current ones, as well as the specific products

By doing this, we will eliminate the excess of “not meant to be indexed” URLs and improve the crawling behavior and performance of the site, as well as likely improving the performance of those pages that are meant to be indexed and ranked by properly prioritizing them:
2. Set indexation rules based on supply & demand to avoid duplication, cannibalization and index bloat issues
Besides crawl budget, content is another important consideration for e-commerce SEO issues; specifically, we need to watch out for content duplication, cannibalization and thin content.
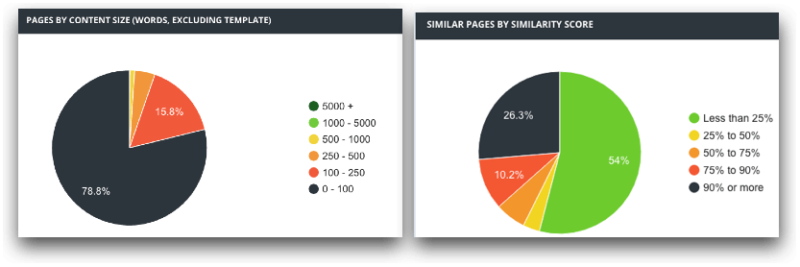
Although we might want to control the generation of content duplication by making sure that there’s only one indexable (and crawlable) URL per page, sub-category and category, the reality is that we will likely end up in the following situation: a high share of pages featuring very little text content, as well as very similar content between the indexable pages:
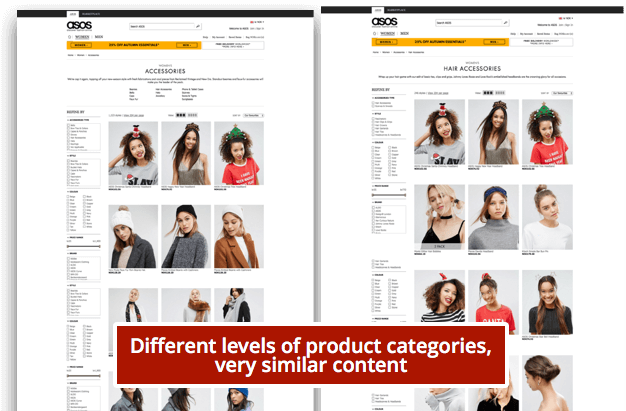
The reason for this is that we will likely have category pages that will show similar products to their subcategory pages, as in the example below. (This is especially true when there are many subcategories and not so many products.)
We may also have subcategory pages with a lot of overlap between them in terms of the products they offer. However, due to the existing product lines, offerings and user behavior, it’s necessary to keep all these similar pages.
The best way to avoid the cannibalization (and overlap) of content between the different levels of our site in a structural, scalable way is by organizing their content differently based on their level of granularity (usually determined by URL depth). This allows us to match page content with user behavior.
Amazon, for example, is great at this. Take a look at what happens when a user drills down from the home page all the way down to a specific product (in this case, a bicycle):
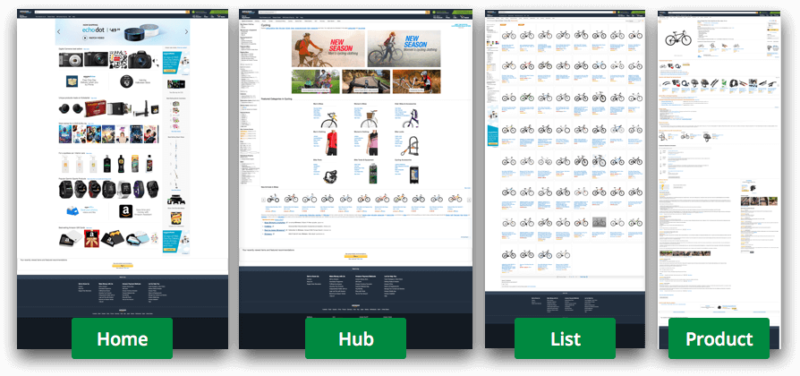
Of note here:
- The general Cycling category page. This is organized as a “hub” page (instead of a listing of products), allowing the user to browse through the very different product sub-categories available (bikes, tubes, helmets, accessories, footwear, hydration and more). Amazon understands that a user who navigates to that page will likely want to filter the search and browse through more specific options in order to buy something.
- A specific bike sub-category. This page is organized as a list, as it features the same type of products — those of the same type and similar characteristics, fulfilling a specific criteria used for the category, where it really makes sense to “showcase” them directly to the user to buy.
By differentiating the site levels like this, we not only reduce the possibility that these main categories’ content will overlap with (and cannibalize) the subcategories ones, but will also likely:
- improve the crawling of the different levels of sub-categories and main products; and
- provide a better user experience by organizing the content in a way that matches the search intent.
Another way to differentiate the content of similar categories, as well as to increase their topical relevance, is to feature specific text descriptions on each one of them. This text should not challenge the listing conversion by obstructing the product views (which is one of the main e-commerce concerns I usually see) but actually support it by providing relevant information to users that complements the text shown on individual product pages.
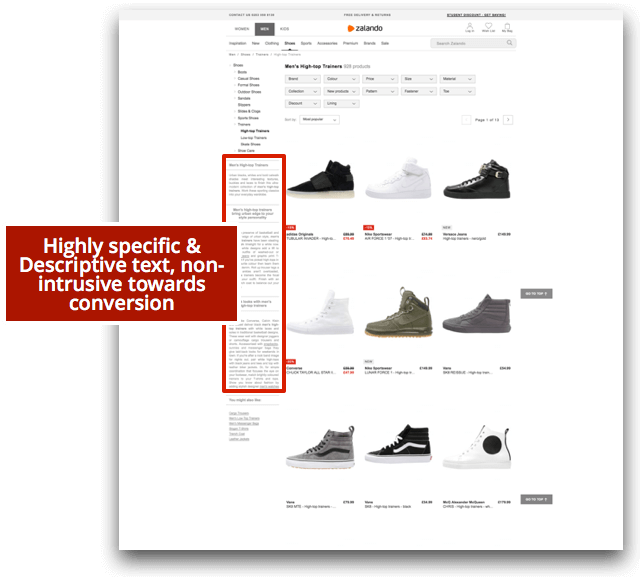
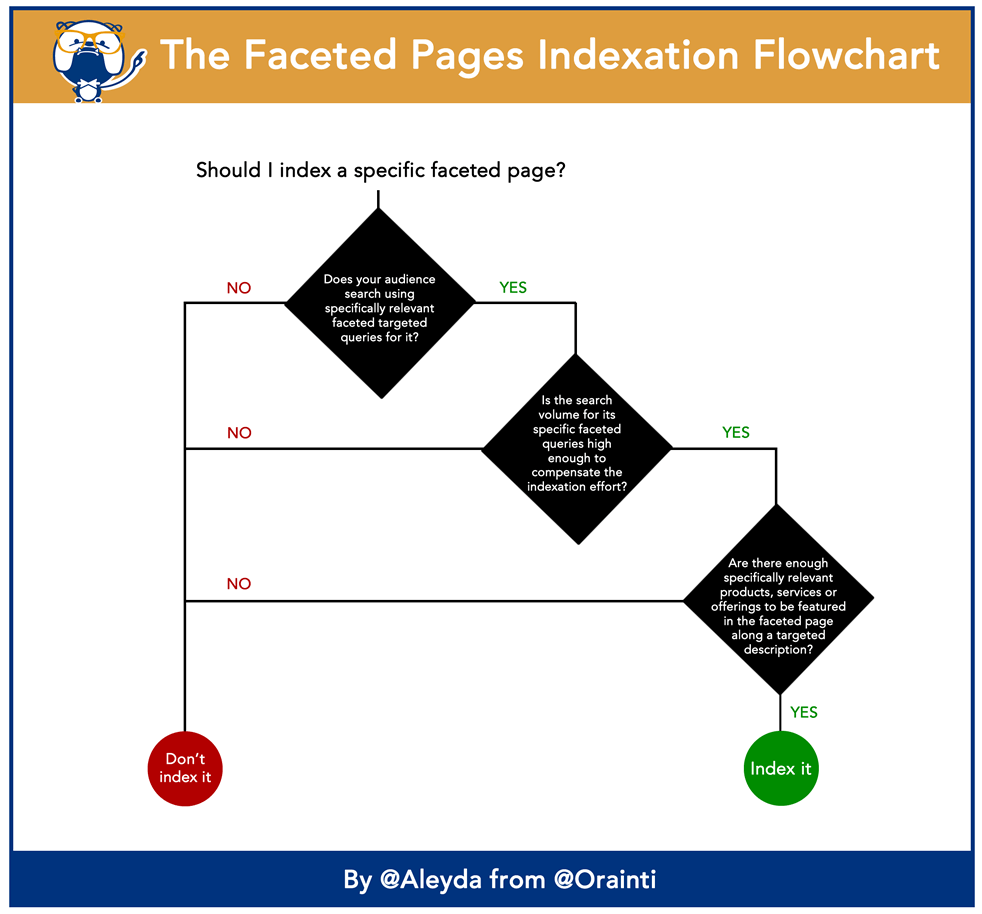
A usual argument against creating specific descriptions for category pages is their related cost — there are so many of them! The solution is to selectively create this content based on “supply and demand” to make a decision that is profitable, using the same flowchart that we can also follow to determine page indexation priority:
- Is the audience searching for it? If so, does the search interest around it compensate the indexation and content creation efforts and costs?
- In that case, are there enough relevant products to feature on that specific page that will fulfill the users’ needs?
If the answers to these questions are “yes,” then it’s likely that content development and indexation for these pages will be profitable and shouldn’t be seen as a cost, but an investment.
Another very common content duplication and overlapping scenario is the one caused by internal search engines whose result pages are improperly configured. These pages will often show the same content as category pages, fulfilling also the same intent.
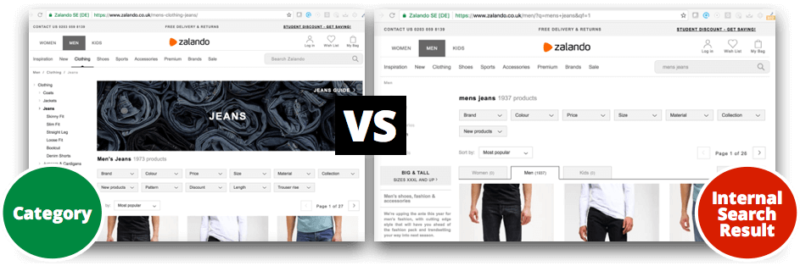
The best way to handle this scenario is to have an internal search engine that searches through the already existing static category and subcategory pages that are part of the site navigation system. When it identifies a match, instead of generating an independent URL with the results, it refers the user to the already existing category or subcategory page. This helps to avoid generating new URLs that will show the same content that already exists elsewhere on the website.
Along these lines, it’s also important that the internal search engine tracks the searched queries so that you can glean helpful insights about user behavior. If certain keywords or phrases are searched often, but there isn’t a matching category or subcategory, an alert can be sent of a potential new category, subcategory or filter page that can be enabled. From there, follow the previously shared flowchart to decide if it’s worth implementing.
If this is not possible, then an easy but less elegant fix is to noindex, follow as well as blocking the crawling of the internal search results pages, although this will mean that at some point your users might decide to share and link those “non-indexable” pages. Although they might be passing their link popularity value to other indexable pages, it will be a missed opportunity to capitalize the relevant category page.

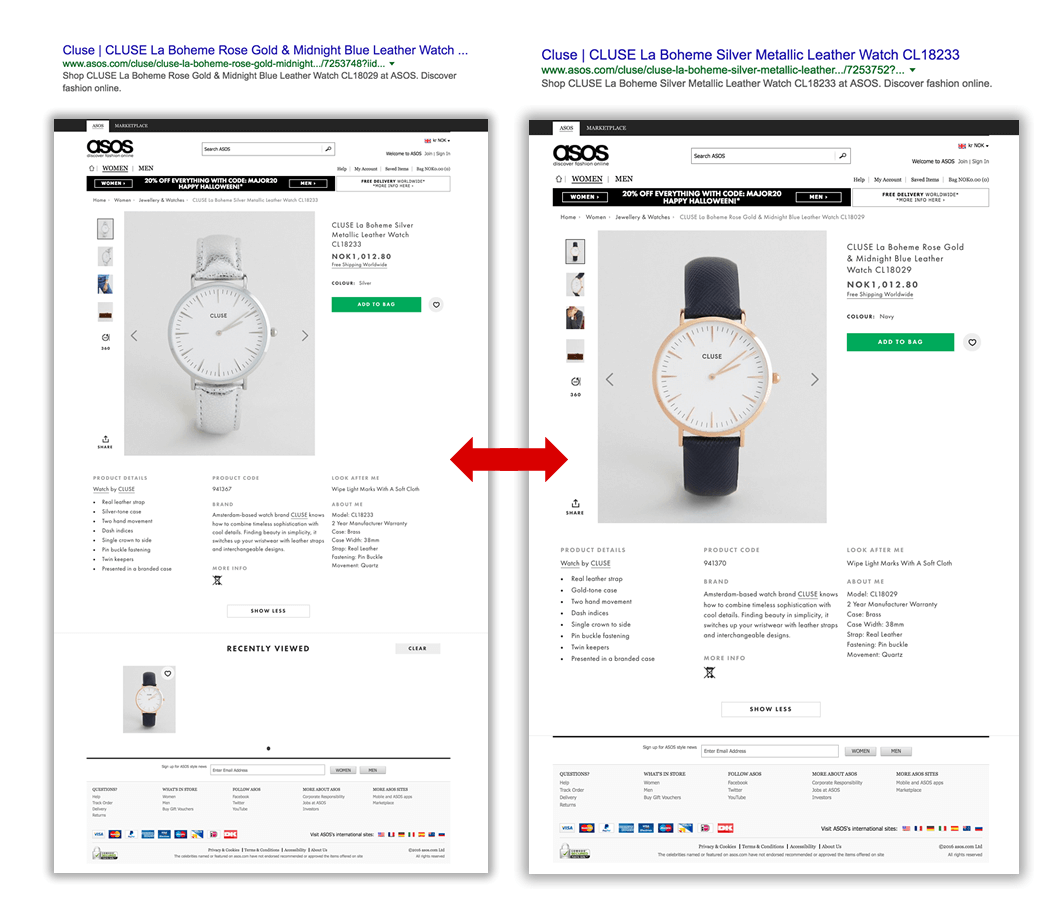
Moving to a more granular level, product pages also have common content issues — specifically those related to very similar products that end up showing almost identical descriptions. In most cases, this doesn’t only happen internally at the site level, but across the content of other e-commerce sites also featuring exactly the same products.
This can be avoided by emphasizing the specific characteristics that differentiate each product, by featuring them in the main content elements of the site: title, meta description, headings and so on. For example:
Additionally, the best way to not only differentiate but enable unique, fresh content in product pages that supports users in making their buying decision is by incentivizing user-generated content, like Q&As from users and reviews and ratings. These, if implemented using the relevant structured data, will also get additional visibility in Google search results with rich snippets, like eBags does here:
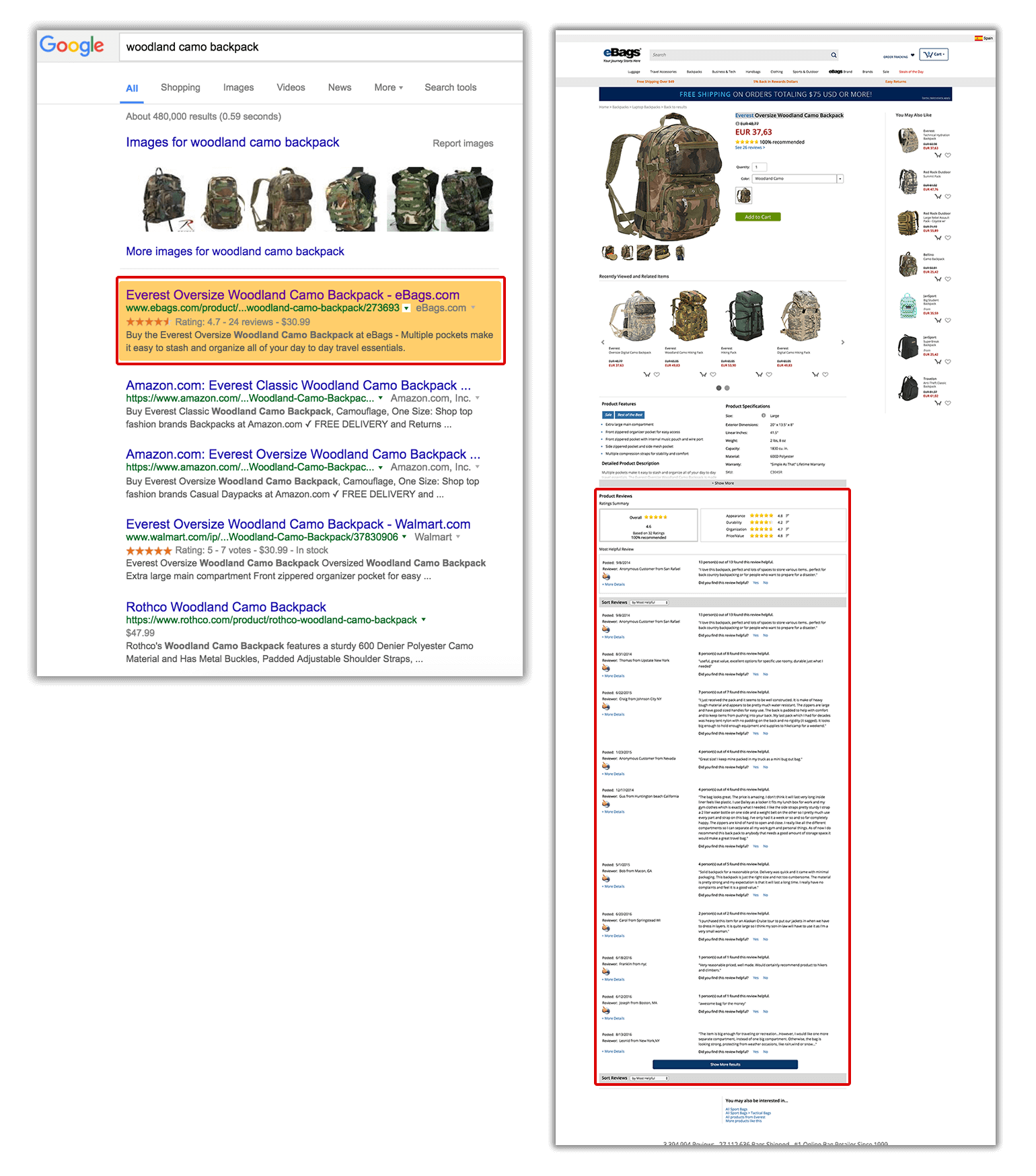
If you want to see which of your competitors are already making the most out of these, you can use SEMrush SERP features reports and obtain the queries for which they are ranking with them (as well as the related position and URLs).

3. Set elimination rules for non-available products, listings & campaign landing pages to keep their value
A very particular characteristic of e-commerce sites is how seasonality impacts their content, from products to campaigns.
Let’s start with campaign landing pages. They are often seasonally oriented (Black Friday, Christmas, New Year’s, Valentine’s Day and so forth) and are usually reused from time to time. The problem is that due to their seasonal nature, they are sometimes not fully capitalized from an SEO perspective, despite the fact that they can achieve a very high level of traffic.
The most common mistake is to just eliminate these pages directly after their relevant campaign time has passed, as shown below with the Black Friday landing page of carrefour.es (compare that to Amazon, which doesn’t suffer from this issue):

If we use the Internet Archive’s Wayback Machine, we can see how this Carrefour Black Friday landing page was used in 2014 and is now showing a 404 Error page, which is a pity, since it still has 31 links from 13 domains pointing to it:

The best way to handle recurrent campaigns is by leaving their campaign landing pages always published and simply updating the content to explain that the offer is not currently available but will be again once the season comes around again. Try offering a countdown to it, allowing the user to get an alert to come back and see other available offers at the time.
Amazon does this, as illustrated below with a (surprise, surprise) already optimized landing page for “Black Friday 2016.” This is a good practice with seasonally driven campaigns: use the year along with the keyword, as people search with it in order to find the offers relevant for the current year.
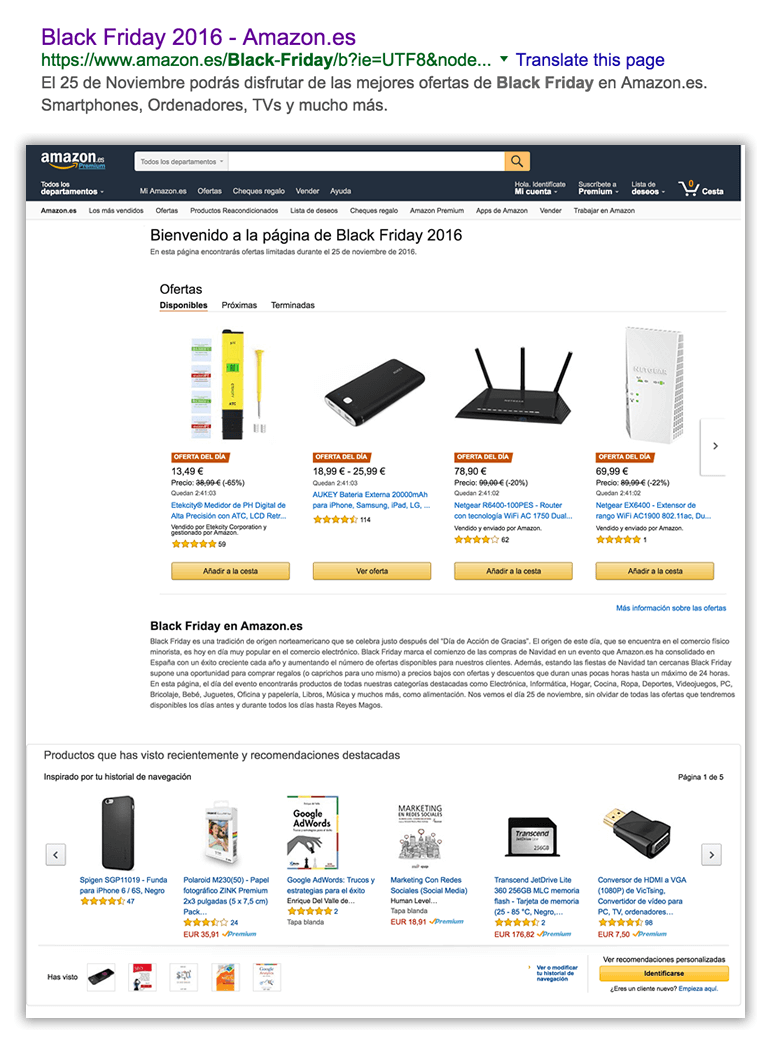
Another very common scenario is the one that happens when products run out of stock. Often times, these product pages are just eliminated from the site, showing a 404 error.
The best way to handle out-of-stock product pages, in case they might be back in the future, is to leave the page as indexable and add an “out of stock” notice, as well as a form to be alerted when the product is back in stock, while offering similar alternatives. That way, you will be able to keep the potential rankings that the page might have earned over time while providing a good user experience.
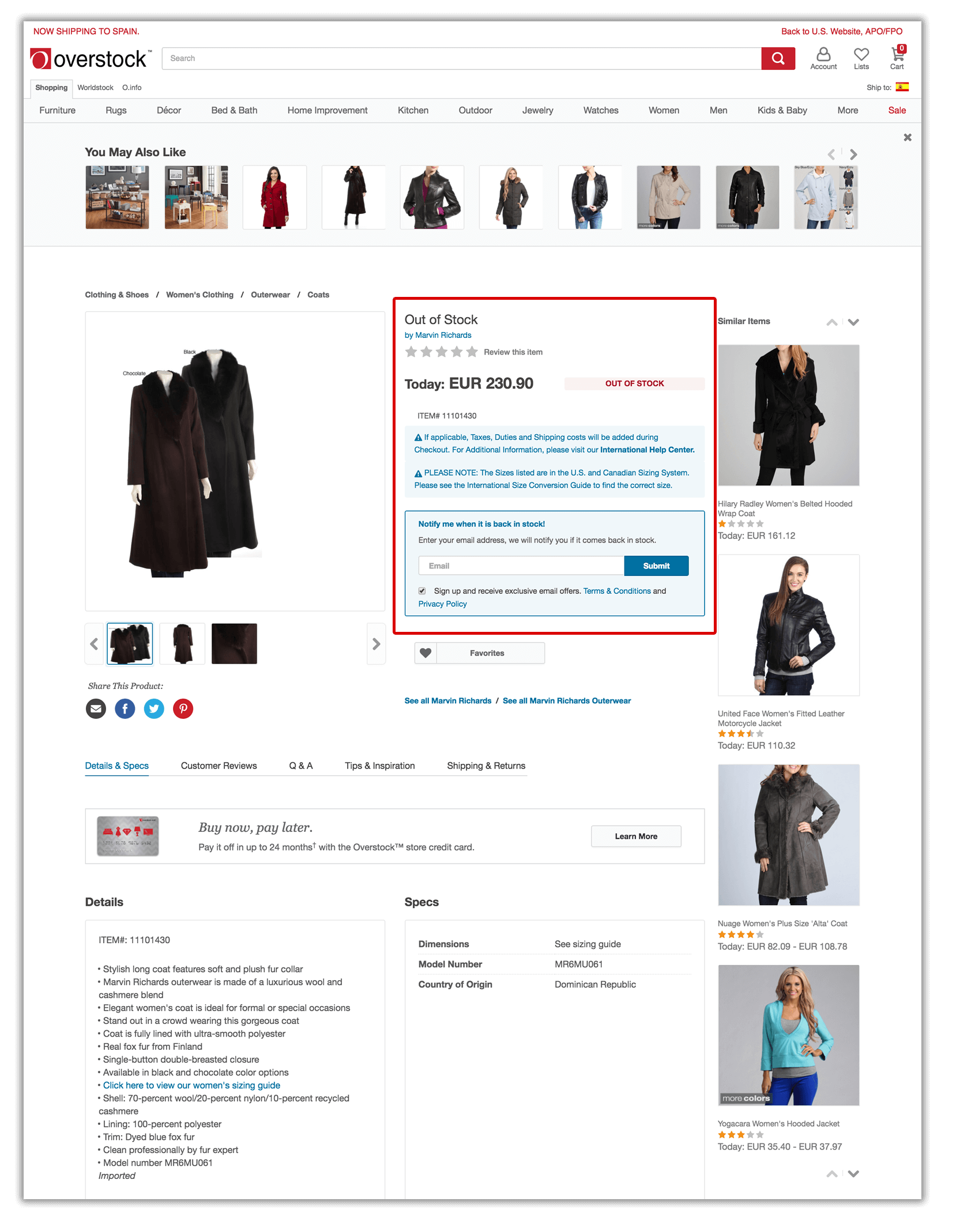
But what should you do in case the product is permanently out of stock, or the landing page is just for a one-time campaign and the pages won’t be reused? The best way to handle that is by 301-redirecting them to their parent category, so the relevance is kept and users can continue browsing through other similar offerings on the site:

Too much work and resources?
These are only the fundamentals. That’s why it’s important to have a flexible e-commerce platform that facilitates these implementations.
Remember that it’s all about the results, and if you have done a good job with SEO, you’ll be able to directly see these kinds of results:
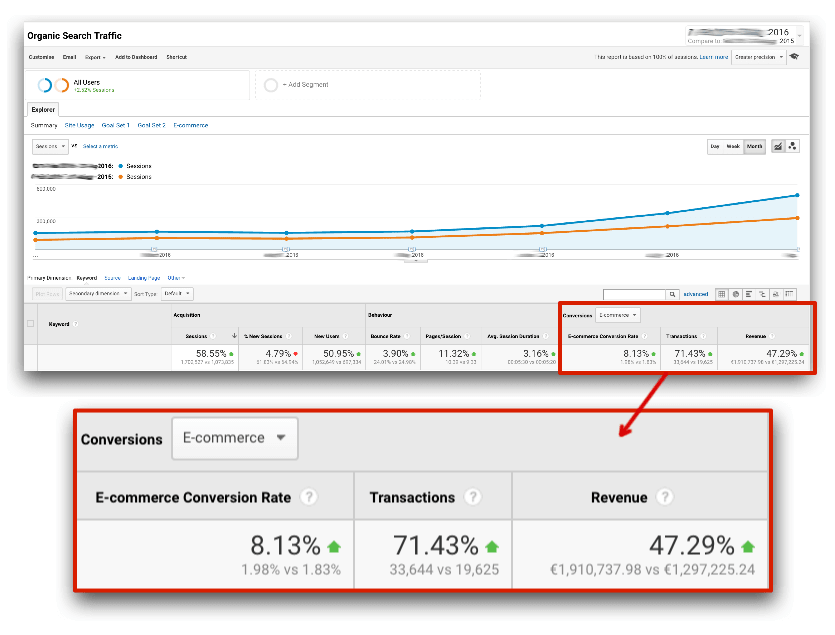
This is the ultimate goal of an e-commerce SEO process: to help you grow your sales and profit.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Related stories
New on Search Engine Land
About the author