Have You Considered Privacy Issues When Using Robots.txt & The Robots Meta Tag?
Understanding the difference between the robots.txt file and Robots <META> Tag is critical for search engine optimization and security. It can have a profound impact on the privacy of your website and customers as well. The first thing to know is what robots.txt files and Robots <META> Tags are. Robots.txt Robots.txt is a file you place in your […]
Understanding the difference between the robots.txt file and Robots <META> Tag is critical for search engine optimization and security. It can have a profound impact on the privacy of your website and customers as well. The first thing to know is what robots.txt files and Robots <META> Tags are.
Robots.txt
Robots.txt is a file you place in your website’s top level directory, the same folder in which a static homepage would go. Inside robots.txt, you can instruct search engines to not crawl content by disallowing file names or directories. There are two parts to a robots.txt directive, the user-agent and one or more disallow instructions.
The user-agent specifies one or all Web crawlers or spiders. When we think of Web crawlers we tend to think Google and Bing; however, a spider can come from anywhere, not just search engines, and there are many of them crawling the Internet.
Here is a simple robots.txt file telling all Web crawlers that it is okay to spider every page:
User-agent: * Disallow:
To disallow all search engines from crawling an entire website, use:
User-agent: * Disallow: /
The difference is the forward slash after Disallow:, signifying the root folder and everything in it, including sub-folders and files.
Robots.txt is versatile. You can disallow entire sub-folders or individual files. You can disallow specific search engine spiders like Googlebot and Bingbot. The search engines even extended robots.txt to include an Allow directive, file or folder name pattern matching, and XML sitemap locations.
Here is a beautifully executed robots.txt file from SEOmoz:
#Nothing interesting to see here, but there is a dance party #happening over here: https://www.youtube.com/watch?v=9vwZ5FQEUFg User-agent: * Disallow: /api/user?* Disallow: Sitemap: https://www.seomoz.org/blog-sitemap.xml Sitemap: https://www.seomoz.org/ugc-sitemap.xml Sitemap: https://www.seomoz.org/profiles-sitemap.xml Sitemap: https://app.wistia.com/sitemaps/2.xml
If you are unfamiliar with robots.txt, be sure to read these pages:
- https://support.google.com/webmasters/bin/answer.py?hl=en&answer=156449&from=40367&rd=1
- https://www.bing.com/webmaster/help/how-to-create-a-robots-txt-file-cb7c31ec
- https://www.bing.com/community/site_blogs/b/webmaster/archive/2008/06/03/robots-exclusion-protocol-joining-together-to-provide-better-documentation.aspx
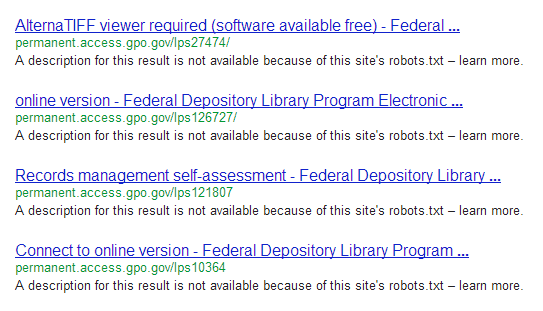
What robots.txt does not do is to keep files out of the search engine indexes. The only thing it does is instruct search engine spiders not to crawl pages. Keep in mind that discovery and crawling are separate. Discovery occurs as search engines find links in documents. When search engines discover pages, they may or may not add them to their indexes.
Robots.txt Does Not Keep Files Out Of The Search Index!
See for yourself at site:permanent.access.gpo.gov.
Is Robots.txt A Security Or Privacy Risk?
Using robots.txt to hide sensitive or private files is a security risk. Not only might search engines index disallowed files, it is like giving a treasure map to pirates. Take a look for yourself and see what you learn.
- https://www.google.com/robots.txt
- https://www.bing.com/robots.txt
- https://searchengineland.com/robots.txt
Here is Search Engine Land’s robots.txt file.
User-Agent: * Disallow: /drafts/ Disallow: /cgi-bin/ Disallow: /gkd/ Disallow: /figz/wp-admin/ Disallow: /wp-content/plugins/ Disallow: /figs/wp-includes/ Disallow: /images/20/ Disallow: /css/ Disallow: /*/feed Disallow: /*/feed/rss Disallow: /*?
I used it to search for inurl:https://searchengineland.com. As you can see, I found a few files I am probably not supposed to know about.
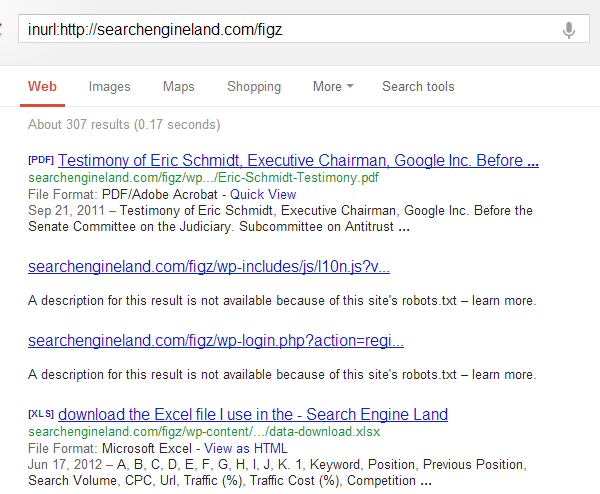
Don’t worry; if I had seen something risky or sensitive on Search Engine Land, I would never have shared this example. Can you say the same about your website or online application?
Use Robots <META> Tag To Keep Files Out Of The Search Index
Because robots.txt does not exclude files from the search indexes, Google and Bing follow a protocol which does accomplish exactly that, the Robots <META> tag.
<html> <head> <title>...</title> <META NAME="ROBOTS" CONTENT="NOINDEX, FOLLOW"> </head>
The robots <META> tag provides two instructions:
- index or noindex
- follow or nofollow
Index or noindex instructs search engines whether or not to index a page. When you select index, they may or may not choose to include a webpage in the index. If you select noindex, the search engines will definitely not include it.
Follow or nofollow instructs Web crawlers whether or not to follow the links on a page. It is like adding an rel=”nofollow” tag to every link on a page. Nofollow evaporates PageRank, the raw search engine ranking authority passed from page to age via links. Even if you noindex a page, it is probably a bad idea to nofollow it. Let PageRank flow through to its final conclusion. Otherwise, you could be pouring perfectly good link juice down the drain.
When you want to exclude a page from the search engine indexes, do this:
<html> <head> <title>...</title> <META NAME="ROBOTS" CONTENT="NOINDEX, FOLLOW"> </head>
There’s No Stopping Bad Behavior
A problem you will have with both robots.txt and the robots <META> tag is that these instructions cannot enforce their directives. While Google and Bing will certainly respect your instructions, someone using Screaming Frog, Xenu, or their own custom site crawler can simply ignore disallow and noindex directives.
The only real security is to lock private content behind a login. If your business is in a competitive space, it will get crawled from time to time and there are few things you can do to stop or impede it.
One last note, I am not letting any cats out of the bag here. Pirates and hackers know all of this. They have known for years. Now you do, too.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Related stories
About the author