Programming Data Collection For SEO Research
Last month, I showed you three tricks I use when gathering data on websites. I used these techniques to download webpages into a local folder. In and of themselves, these procedures are not SEO; however, a search engine optimization professional working on a large or enterprise website ought to know how to do this. In this […]

Last month, I showed you three tricks I use when gathering data on websites. I used these techniques to download webpages into a local folder. In and of themselves, these procedures are not SEO; however, a search engine optimization professional working on a large or enterprise website ought to know how to do this. In this article, I’ll show you how to:
- Make a list of pages inside a folder
- Set up a development environment
- Open webpages from a script and extract data
If you learn these procedures, I am certain you will find legitimate opportunities to use each, together or alone.
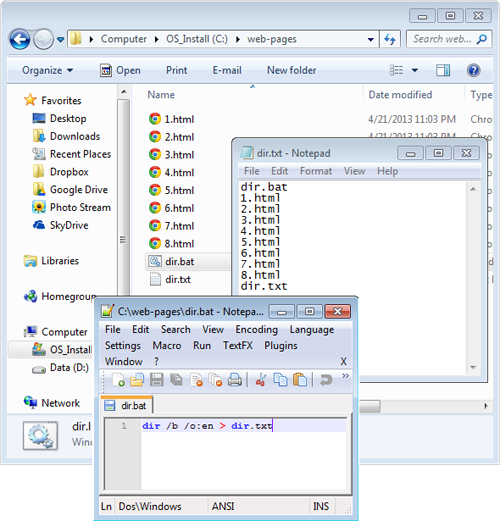
Create A List Of Files In A Directory
Mac users may wonder why I am bothering to go over how to take a list of files inside a directory and turn their names into a text list. On the Mac, you just have to:
- Select all the files names in the folder and hit copy
- Create an empty text file
- In the menu, select Edit, then Paste and Match Style
In Windows, on the other hand, there is no easy way to do this. Here’s my recipe:
- Create a text file named dir.bat
- Into the file, type the line dir /b /o:en > dir.txt
- Save, close, then drop this file into the directory for which you want the list of files
- Double click on the file to run the script
- The .bat file will make a new text file with the list of file names
 Now that you have a list of files, let’s open one up and find the content you are looking for.
Now that you have a list of files, let’s open one up and find the content you are looking for.
Set Up A PHP Environment
If the thought of setting-up a PHP environment scares you, relax. All you need is a hosted website or a disk drive. A hosting account is the easiest way to go here. It includes PHP, so all you need is an FTP program to create a subfolder and upload your script files.
For example, I created a simple Hello World script on one of my sites. If you do not have a hosted site, you can create your own Apache with PHP environment for free with XAMPP. XAMPP installs Apache, PHP, MySQL, and some other programs that, together, create a development environment on your disk. I keep XAMPP on the thumb drive so I always have my scripts available wherever there’s a PC with a USB port. After installing XAMPP:
- Visit the XAMPP directory and run xampp-control.exe
- Start Apache
- In a Web browser, visit https://localhost
Website spaces go into /xampp/htdocs/ as a subfolder; for example, the scripts go in /xampp/htdocs/scripts/. Copy and save the following as /xampp/htdocs/scripts/hello-world.php:
<?php echo “<html><head><title>Hello World</title></head><body><p style=\”font-family: \’Segoe UI\’, Tahoma, Geneva, Verdana, sans-serif; font-size: x-large; color: #FFFFFF; background-color: #8E8E17; margin-top: 250px; padding: 25px 25px 25px 25px;text-align:center\”>Hello World. Seattle Calling. </p><p style=\”font-family: \’Segoe UI\’, Tahoma, Geneva, Verdana, sans-serif; font-size: x-large; color: #FFFFFF; background-color: #8E8E17; margin-top: 0px; padding: 25px 25px 25px 25px;text-align:center\”>You can <a href=\”javascript:history.go(-1)\”>[Go Back]</a> now.</p></body></html>”; ?>
To run the script, visit https://localhost/scripts/hello-world.php. Whether you put a subfolder on a hosted Web account or install XAMPP, either will function as your development environment. I prefer XAMPP on my thumb drive because I can save and execute files without having to upload them.
Extract Content From A Webpage
Enter this script into your development environment as twitter-followers.php.
<?php $a[1]=’https://twitter.com/seomoz’; $a[2]=’https://twitter.com/sengineland’; $a[3]=’https://twitter.com/apple_worldwide’; $a[4]=’https://twitter.com/microsoft’; $a[5]=’https://twitter.com/smartsheet’; foreach($a as $objectURL){ $handle = file_get_contents($objectURL); if(!$handle) die(“Can’t open device”); preg_match(‘/(<strong>)(.*)(<\/strong> Followers)/i’, $handle, $followers); echo “\”” . $objectURL . “\”;\”” . $followers[2] . “\”<br />”; sleep(.5); } ?>
Now, run it: https://localhost/scripts/twitter-followers.php or wherever your development environment is located. It should output a delimited file with each Twitter URL and the number of followers the account has. Here is what is happening in this script.
$a[1]=’https://twitter.com/seomoz’;
Each of lines 2 to 6 define a variable as a Twitter address. Notice the [1], [2], [3], etc. This makes it easy to write a formula in Excel that will write a line of PHP code for each Twitter address. $a[1]=’https://twitter.com/seomox’;
foreach($a as $objectURL){}
This creates a loop that will go through all the $a[ ] variables you created. With each pass it assigns the contents of $a[ ] to $objectURL.
$handle = file_get_contents($objectURL);
This line reads the web URL and stores the HTML markup into $handle.
preg_match(‘/(<strong>)(.*)(<\/strong> Followers)/i’, $handle, $followers);
This is where the magic happens. This is a Perl Regular Expression Match command.
- It checks against the HTML markup in $handle and writes the results to $followers
- It stores anything between parentheses () in $followers
- The beginning / and ending / are the start and end of the test
- .* is a regular expression that matches any set or length of characters, in this case between <strong> and </strong> Followers
- The \ character is an escape. When placed before a reserved character, like / or *, it tells PHP to treat it like a regular or real letter, number or punctuation
- The small i after the second / instructs the matching command to ignore letter case, or be case insensitive
echo “\”” . $objectURL . “\”;\”” . $followers[2] . “\”<br />”;
This line prints the results. Notice the escape characters before the printed quotes. Also note the 2 in $followers[2]; this matches the second set of parentheses.
Knowing what you have learned, what do you think this line of code will do?
preg_match(‘/(<div class=\”fsm fwn fcg\”>)(.*)( likes · )(.*)( talking about this<\/div>)/i’, $handle, $followers);
If you said, “match Facebook like and talking about,” you’re right. However, if you try it, it will not work. Why? Because Facebook tests for a user agent, and the script does not provide one. Here is a case where you can go back to part one, write a macro that will download the webpages to your local computer, then capture the data you want. In your script, just change the URLs to files.
$a[1]=’c:\file-1.html’;
PHP is perfectly capable of sending a user agent; however, you can get trapped for different reasons. Another example is the requirement to be logged into your account on websites like Open Site Explorer.
preg_match(‘/(subdomain_mozrank\”:)(.*)(,\”subdomain_mozrank_raw)/i’, $handle, $followers);
Rather than learning a PHP for every situation, the iMacros I shared last month will get you going immediately. If you want to take this further, read these pages and study up on regular expressions:
- https://php.net/manual/en/function.file-get-contents.php
- https://php.net/manual/en/function.preg-match.php
There is a whole world of learning out there. It does not have to be PHP, either. Python, Ruby, PERL, and others will all work. Do some research, browse through some tutorials and talk to your developer friends. Make the choice that is right for you.
A word of caution: some of the straight quotes may be changed to smart quotes. Be sure to use straight quotes in your coding.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Related stories
About the author